 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperplane Arrangements of Trained ConvNets Are Biased
Mar 17, 2020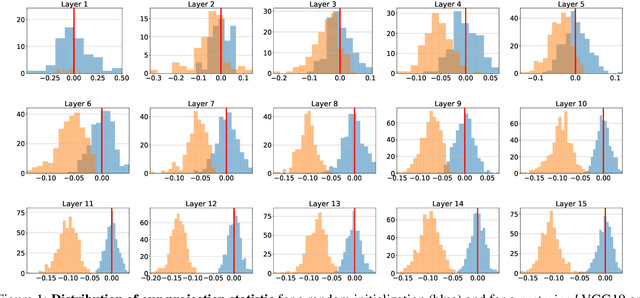
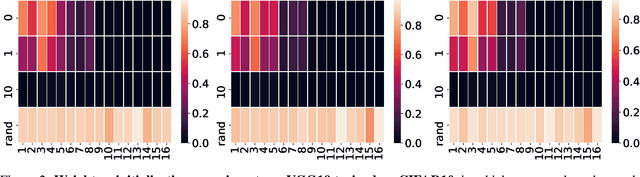

We investigate the geometric properties of the functions learned by trained ConvNets in the preactivation space of their convolutional layers, by performing an empirical study of hyperplane arrangements induced by a convolutional layer. We introduce statistics over the weights of a trained network to study local arrangements and relate them to the training dynamics. We observe that trained ConvNets show a significant statistical bias towards regular hyperplane configurations. Furthermore, we find that layers showing biased configurations are critical to validation performance for the architectures considered, trained on CIFAR10, CIFAR100 and ImageNet.
Geometry of Deep Convolutional Networks
May 21, 2019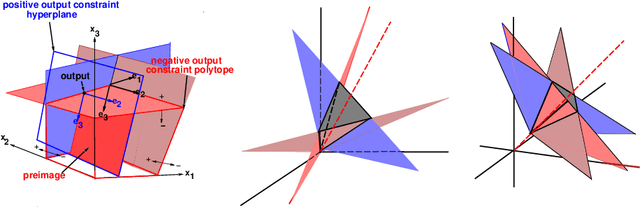

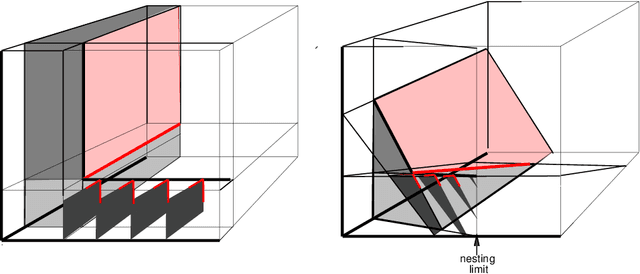

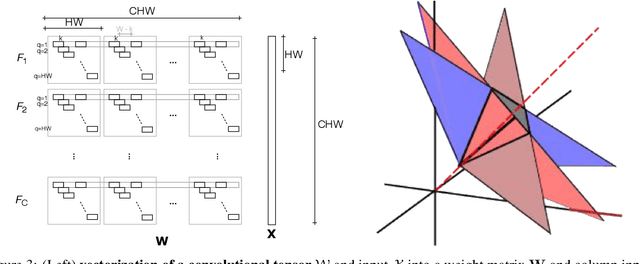
We give a formal procedure for computing preimages of convolutional network outputs using the dual basis defined from the set of hyperplanes associated with the layers of the network. We point out the special symmetry associated with arrangements of hyperplanes of convolutional networks that take the form of regular multidimensional polyhedral cones. We discuss the efficiency of large number of layers of nested cones that result from incremental small size convolutions in order to give a good compromise between efficient contraction of data to low dimensions and shaping of preimage manifolds. We demonstrate how a specific network flattens a non linear input manifold to an affine output manifold and discuss its relevance to understanding classification properties of deep networks.
Visual Instance Retrieval with Deep Convolutional Networks
May 09, 2016
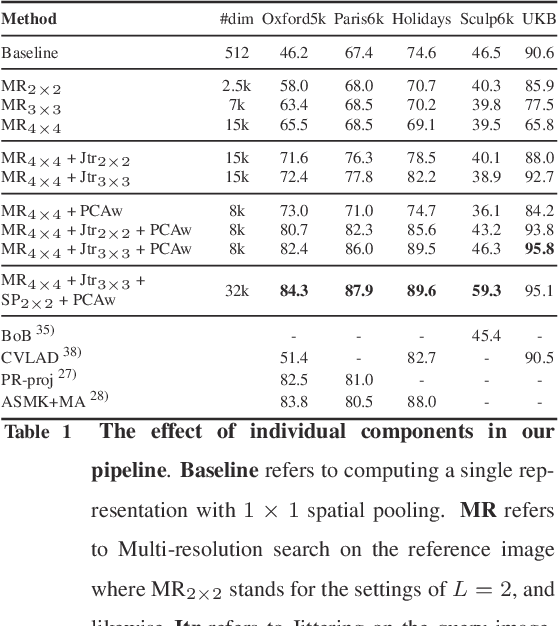
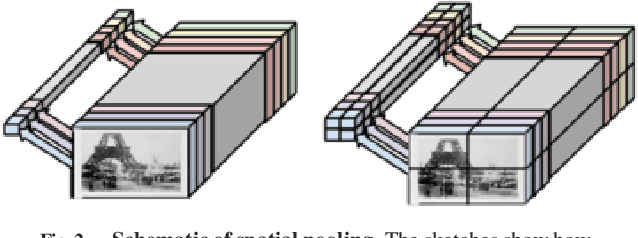
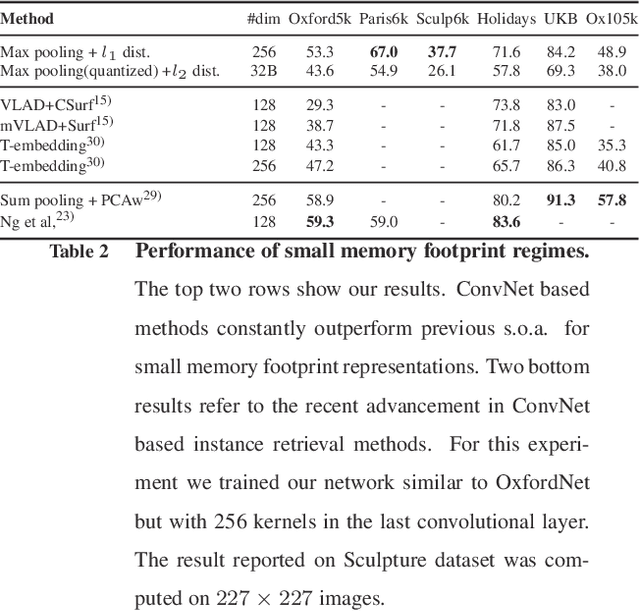
This paper provides an extensive study on the availability of image representations based on convolutional networks (ConvNets) for the task of visual instance retrieval. Besides the choice of convolutional layers, we present an efficient pipeline exploiting multi-scale schemes to extract local features, in particular, by taking geometric invariance into explicit account, i.e. positions, scales and spatial consistency. In our experiments using five standard image retrieval datasets, we demonstrate that generic ConvNet image representations can outperform other state-of-the-art methods if they are extracted appropriately.
Factors of Transferability for a Generic ConvNet Representation
Jul 15, 2015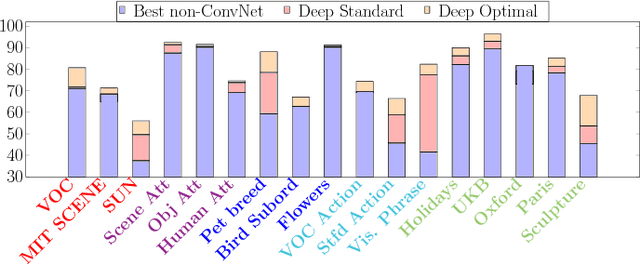
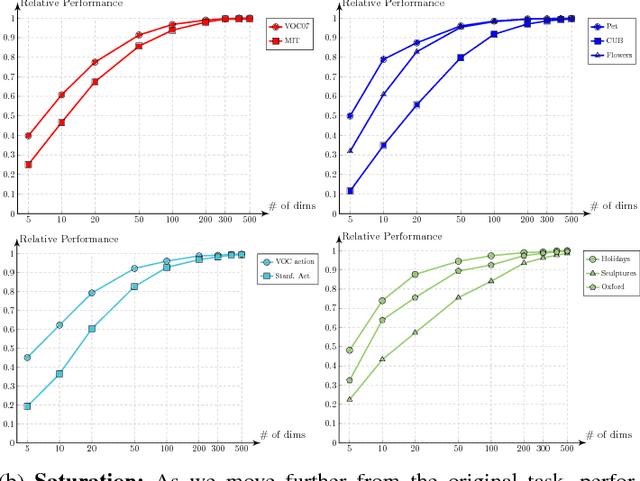

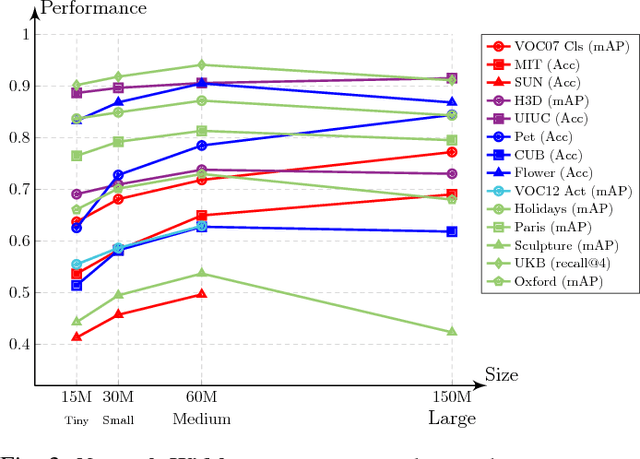
Evidence is mounting that Convolutional Networks (ConvNets) are the most effective representation learning method for visual recognition tasks. In the common scenario, a ConvNet is trained on a large labeled dataset (source) and the feed-forward units activation of the trained network, at a certain layer of the network, is used as a generic representation of an input image for a task with relatively smaller training set (target). Recent studies have shown this form of representation transfer to be suitable for a wide range of target visual recognition tasks. This paper introduces and investigates several factors affecting the transferability of such representations. It includes parameters for training of the source ConvNet such as its architecture, distribution of the training data, etc. and also the parameters of feature extraction such as layer of the trained ConvNet, dimensionality reduction, etc. Then, by optimizing these factors, we show that significant improvements can be achieved on various (17) visual recognition tasks. We further show that these visual recognition tasks can be categorically ordered based on their distance from the source task such that a correlation between the performance of tasks and their distance from the source task w.r.t. the proposed factors is observed.
Spotlight the Negatives: A Generalized Discriminative Latent Model
Jul 08, 2015


Discriminative latent variable models (LVM) are frequently applied to various visual recognition tasks. In these systems the latent (hidden) variables provide a formalism for modeling structured variation of visual features. Conventionally, latent variables are de- fined on the variation of the foreground (positive) class. In this work we augment LVMs to include negative latent variables corresponding to the background class. We formalize the scoring function of such a generalized LVM (GLVM). Then we discuss a framework for learning a model based on the GLVM scoring function. We theoretically showcase how some of the current visual recognition methods can benefit from this generalization. Finally, we experiment on a generalized form of Deformable Part Models with negative latent variables and show significant improvements on two different detection tasks.
Persistent Evidence of Local Image Properties in Generic ConvNets
Nov 24, 2014
Supervised training of a convolutional network for object classification should make explicit any information related to the class of objects and disregard any auxiliary information associated with the capture of the image or the variation within the object class. Does this happen in practice? Although this seems to pertain to the very final layers in the network, if we look at earlier layers we find that this is not the case. Surprisingly, strong spatial information is implicit. This paper addresses this, in particular, exploiting the image representation at the first fully connected layer, i.e. the global image descriptor which has been recently shown to be most effective in a range of visual recognition tasks. We empirically demonstrate evidences for the finding in the contexts of four different tasks: 2d landmark detection, 2d object keypoints prediction, estimation of the RGB values of input image, and recovery of semantic label of each pixel. We base our investigation on a simple framework with ridge rigression commonly across these tasks, and show results which all support our insight. Such spatial information can be used for computing correspondence of landmarks to a good accuracy, but should potentially be useful for improving the training of the convolutional nets for classification purposes.
Large Scale, Large Margin Classification using Indefinite Similarity Measures
May 27, 2014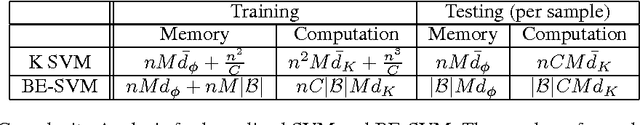
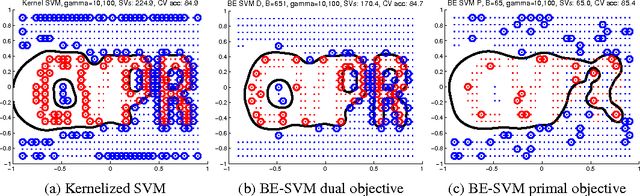
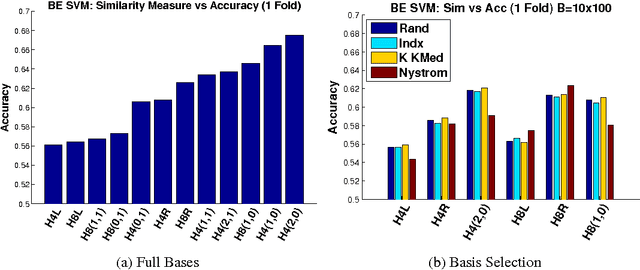

Despite the success of the popular kernelized support vector machines, they have two major limitations: they are restricted to Positive Semi-Definite (PSD) kernels, and their training complexity scales at least quadratically with the size of the data. Many natural measures of similarity between pairs of samples are not PSD e.g. invariant kernels, and those that are implicitly or explicitly defined by latent variable models. In this paper, we investigate scalable approaches for using indefinite similarity measures in large margin frameworks. In particular we show that a normalization of similarity to a subset of the data points constitutes a representation suitable for linear classifiers. The result is a classifier which is competitive to kernelized SVM in terms of accuracy, despite having better training and test time complexities. Experimental results demonstrate that on CIFAR-10 dataset, the model equipped with similarity measures invariant to rigid and non-rigid deformations, can be made more than 5 times sparser while being more accurate than kernelized SVM using RBF kernels.
Self-tuned Visual Subclass Learning with Shared Samples An Incremental Approach
May 26, 2014



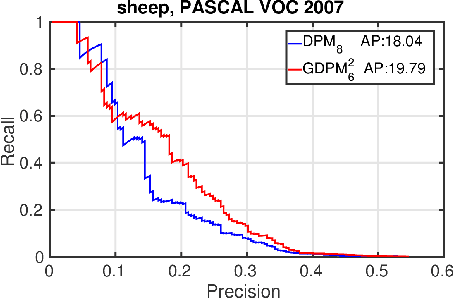
Computer vision tasks are traditionally defined and evaluated using semantic categories. However, it is known to the field that semantic classes do not necessarily correspond to a unique visual class (e.g. inside and outside of a car). Furthermore, many of the feasible learning techniques at hand cannot model a visual class which appears consistent to the human eye. These problems have motivated the use of 1) Unsupervised or supervised clustering as a preprocessing step to identify the visual subclasses to be used in a mixture-of-experts learning regime. 2) Felzenszwalb et al. part model and other works model mixture assignment with latent variables which is optimized during learning 3) Highly non-linear classifiers which are inherently capable of modelling multi-modal input space but are inefficient at the test time. In this work, we promote an incremental view over the recognition of semantic classes with varied appearances. We propose an optimization technique which incrementally finds maximal visual subclasses in a regularized risk minimization framework. Our proposed approach unifies the clustering and classification steps in a single algorithm. The importance of this approach is its compliance with the classification via the fact that it does not need to know about the number of clusters, the representation and similarity measures used in pre-processing clustering methods a priori. Following this approach we show both qualitatively and quantitatively significant results. We show that the visual subclasses demonstrate a long tail distribution. Finally, we show that state of the art object detection methods (e.g. DPM) are unable to use the tails of this distribution comprising 50\% of the training samples. In fact we show that DPM performance slightly increases on average by the removal of this half of the data.
CNN Features off-the-shelf: an Astounding Baseline for Recognition
May 12, 2014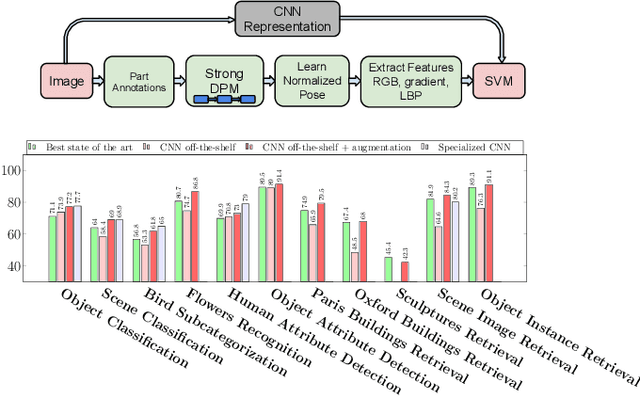


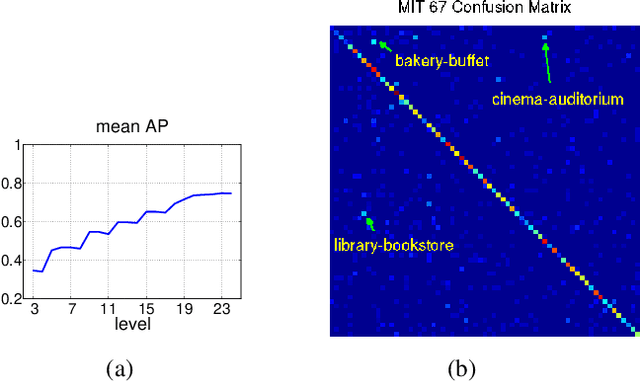
Recent results indicate that the generic descriptors extracted from the convolutional neural networks are very powerful. This paper adds to the mounting evidence that this is indeed the case. We report on a series of experiments conducted for different recognition tasks using the publicly available code and model of the \overfeat network which was trained to perform object classification on ILSVRC13. We use features extracted from the \overfeat network as a generic image representation to tackle the diverse range of recognition tasks of object image classification, scene recognition, fine grained recognition, attribute detection and image retrieval applied to a diverse set of datasets. We selected these tasks and datasets as they gradually move further away from the original task and data the \overfeat network was trained to solve. Astonishingly, we report consistent superior results compared to the highly tuned state-of-the-art systems in all the visual classification tasks on various datasets. For instance retrieval it consistently outperforms low memory footprint methods except for sculptures dataset. The results are achieved using a linear SVM classifier (or $L2$ distance in case of retrieval) applied to a feature representation of size 4096 extracted from a layer in the net. The representations are further modified using simple augmentation techniques e.g. jittering. The results strongly suggest that features obtained from deep learning with convolutional nets should be the primary candidate in most visual recognition tasks.