 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Instance Retrieval with Deep Convolutional Networks
May 09, 2016
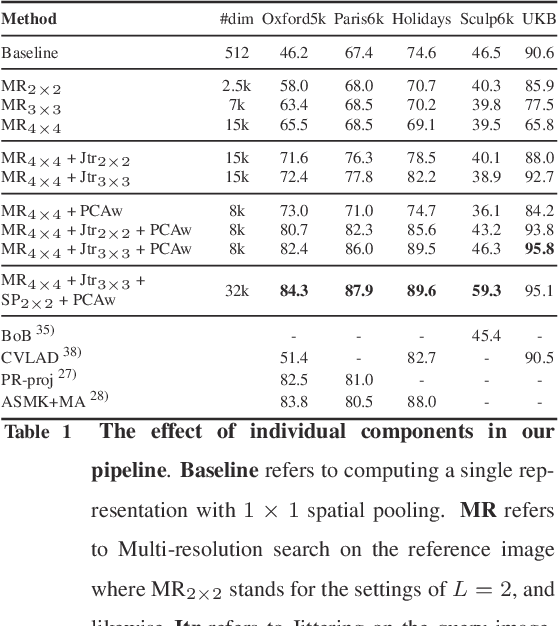
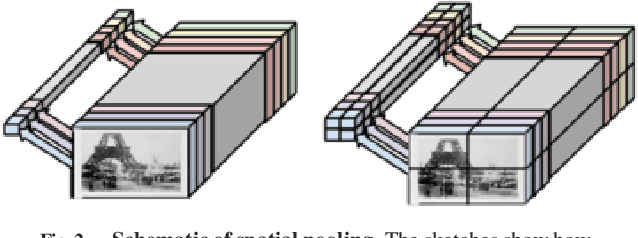
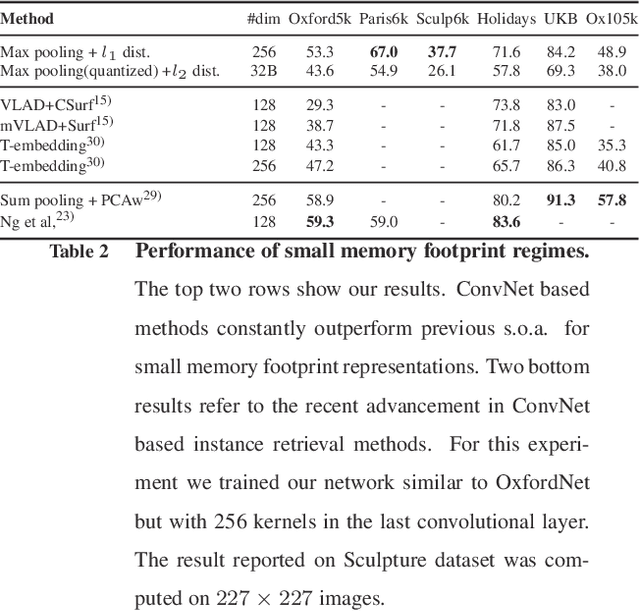
This paper provides an extensive study on the availability of image representations based on convolutional networks (ConvNets) for the task of visual instance retrieval. Besides the choice of convolutional layers, we present an efficient pipeline exploiting multi-scale schemes to extract local features, in particular, by taking geometric invariance into explicit account, i.e. positions, scales and spatial consistency. In our experiments using five standard image retrieval datasets, we demonstrate that generic ConvNet image representations can outperform other state-of-the-art methods if they are extracted appropriately.
Factors of Transferability for a Generic ConvNet Representation
Jul 15, 2015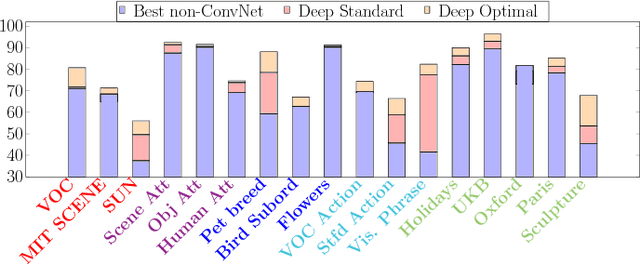
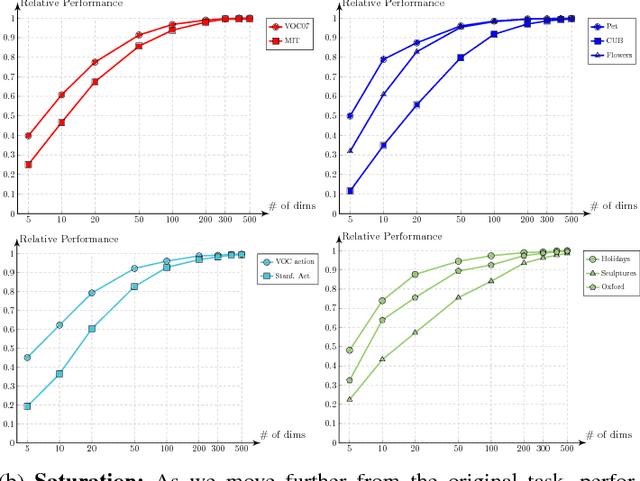

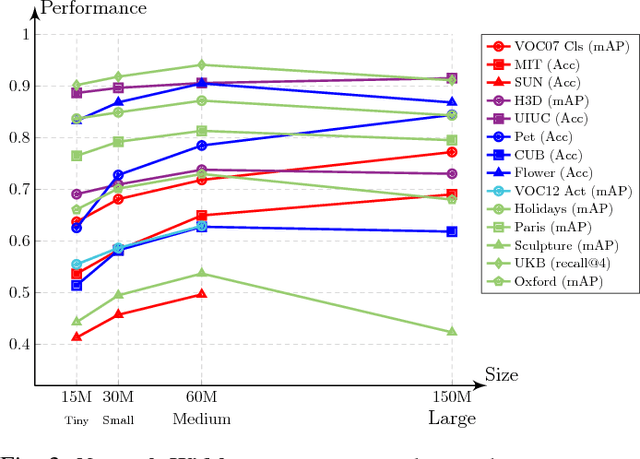
Evidence is mounting that Convolutional Networks (ConvNets) are the most effective representation learning method for visual recognition tasks. In the common scenario, a ConvNet is trained on a large labeled dataset (source) and the feed-forward units activation of the trained network, at a certain layer of the network, is used as a generic representation of an input image for a task with relatively smaller training set (target). Recent studies have shown this form of representation transfer to be suitable for a wide range of target visual recognition tasks. This paper introduces and investigates several factors affecting the transferability of such representations. It includes parameters for training of the source ConvNet such as its architecture, distribution of the training data, etc. and also the parameters of feature extraction such as layer of the trained ConvNet, dimensionality reduction, etc. Then, by optimizing these factors, we show that significant improvements can be achieved on various (17) visual recognition tasks. We further show that these visual recognition tasks can be categorically ordered based on their distance from the source task such that a correlation between the performance of tasks and their distance from the source task w.r.t. the proposed factors is observed.
Persistent Evidence of Local Image Properties in Generic ConvNets
Nov 24, 2014
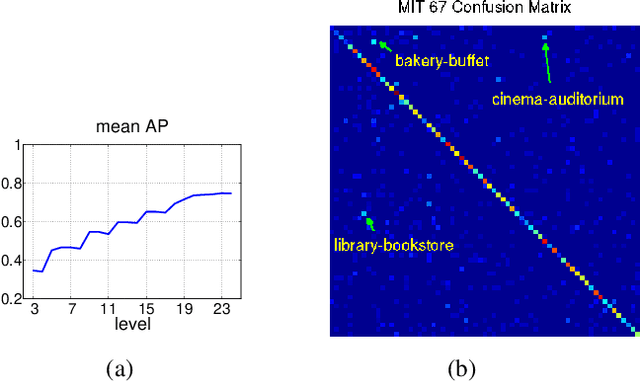
Supervised training of a convolutional network for object classification should make explicit any information related to the class of objects and disregard any auxiliary information associated with the capture of the image or the variation within the object class. Does this happen in practice? Although this seems to pertain to the very final layers in the network, if we look at earlier layers we find that this is not the case. Surprisingly, strong spatial information is implicit. This paper addresses this, in particular, exploiting the image representation at the first fully connected layer, i.e. the global image descriptor which has been recently shown to be most effective in a range of visual recognition tasks. We empirically demonstrate evidences for the finding in the contexts of four different tasks: 2d landmark detection, 2d object keypoints prediction, estimation of the RGB values of input image, and recovery of semantic label of each pixel. We base our investigation on a simple framework with ridge rigression commonly across these tasks, and show results which all support our insight. Such spatial information can be used for computing correspondence of landmarks to a good accuracy, but should potentially be useful for improving the training of the convolutional nets for classification purposes.
CNN Features off-the-shelf: an Astounding Baseline for Recognition
May 12, 2014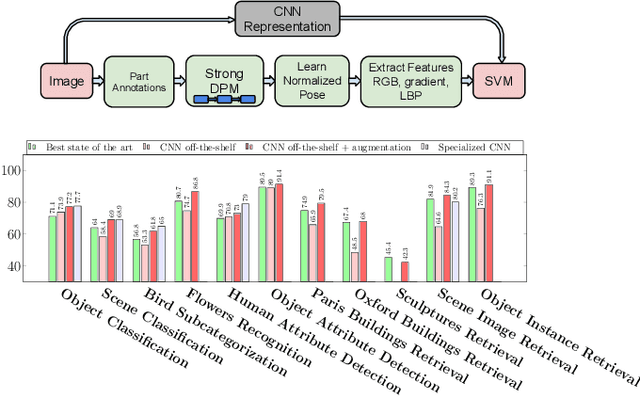


Recent results indicate that the generic descriptors extracted from the convolutional neural networks are very powerful. This paper adds to the mounting evidence that this is indeed the case. We report on a series of experiments conducted for different recognition tasks using the publicly available code and model of the \overfeat network which was trained to perform object classification on ILSVRC13. We use features extracted from the \overfeat network as a generic image representation to tackle the diverse range of recognition tasks of object image classification, scene recognition, fine grained recognition, attribute detection and image retrieval applied to a diverse set of datasets. We selected these tasks and datasets as they gradually move further away from the original task and data the \overfeat network was trained to solve. Astonishingly, we report consistent superior results compared to the highly tuned state-of-the-art systems in all the visual classification tasks on various datasets. For instance retrieval it consistently outperforms low memory footprint methods except for sculptures dataset. The results are achieved using a linear SVM classifier (or $L2$ distance in case of retrieval) applied to a feature representation of size 4096 extracted from a layer in the net. The representations are further modified using simple augmentation techniques e.g. jittering. The results strongly suggest that features obtained from deep learning with convolutional nets should be the primary candidate in most visual recognition tasks.