 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOracle Supervision Transfers for Hyperparameter Prediction in Model-Based Image Denoising
May 19, 2026Hyperparameter prediction is a critical practical bottleneck for model-based image denoisers, ranging from classical TV/TGV variational solvers to modern diffusion-based models such as DiffPIR. While existing learned predictors can achieve near-oracle performance, this approach scales poorly: each new configuration conventionally requires its own oracle-labeled training set, and each label requires a hierarchical grid search evaluated against clean ground truth. We therefore ask whether oracle supervision collected on source configurations can transfer to target configurations with few or no target oracle labels. We propose HyperDn, a single configuration-conditioned predictor that pools oracle supervision across source configurations and predicts heterogeneous hyperparameters for new denoiser--noise configurations. In a cross-paradigm experiment, HyperDn transfers from relatively cheap TV/TGV variational sources to more expensive diffusion-based DiffPIR. With only $2$ target oracle labels, it reaches $30.23$\,dB, within $0.90$\,dB of the oracle, and outperforms the $64$-label per-configuration predictor trained from scratch, using $1/32$ as many target labels as that baseline point. Without any target oracle labels, HyperDn also reaches near-oracle PSNR on two unseen mixtures of seen noise types and on transfer from relatively cheap $96\times 96$ source images to $512\times 768$ targets. Together, these results show that expensive oracle supervision for hyperparameter prediction can be transferred from source to new target configurations, reducing the need to rebuild oracle labels for each new denoising configuration.
Geometric Layer-wise Approximation Rates for Deep Networks
Apr 22, 2026Depth is widely viewed as a central contributor to the success of deep neural networks, whereas standard neural network approximation theory typically provides guarantees only for the final output and leaves the role of intermediate layers largely unclear. We address this gap by developing a quantitative framework in which depth admits a precise scale-dependent interpretation. Specifically, we design a single shared mixed-activation architecture of fixed width $2dN+d+2$ and any prescribed finite depth such that each intermediate readout $Φ_\ell$ is itself an approximant to the target function $f$. For $f\in L^p([0,1]^d)$ with $p\in [1,\infty)$, the approximation error of $Φ_\ell$ is controlled by $(2d+1)$ times the $L^p$ modulus of continuity at the geometric scale $N^{-\ell}$ for all $\ell$. The estimate reduces to the geometric rate $(2d+1)N^{-\ell}$ if $f$ is $1$-Lipschitz. Our network design is inspired by multigrade deep learning, where depth serves as a progressive refinement mechanism: each new correction targets residual information at a finer scale while the earlier correction terms remain part of the later readouts, yielding a nested architecture that supports adaptive refinement without redesigning the preceding network.
Multigrade Neural Network Approximation
Jan 23, 2026We study multigrade deep learning (MGDL) as a principled framework for structured error refinement in deep neural networks. While the approximation power of neural networks is now relatively well understood, training very deep architectures remains challenging due to highly non-convex and often ill-conditioned optimization landscapes. In contrast, for relatively shallow networks, most notably one-hidden-layer $\texttt{ReLU}$ models, training admits convex reformulations with global guarantees, motivating learning paradigms that improve stability while scaling to depth. MGDL builds upon this insight by training deep networks grade by grade: previously learned grades are frozen, and each new residual block is trained solely to reduce the remaining approximation error, yielding an interpretable and stable hierarchical refinement process. We develop an operator-theoretic foundation for MGDL and prove that, for any continuous target function, there exists a fixed-width multigrade $\texttt{ReLU}$ scheme whose residuals decrease strictly across grades and converge uniformly to zero. To the best of our knowledge, this work provides the first rigorous theoretical guarantee that grade-wise training yields provable vanishing approximation error in deep networks. Numerical experiments further illustrate the theoretical results.
Online Learning of HTN Methods for integrated LLM-HTN Planning
Nov 17, 2025We present online learning of Hierarchical Task Network (HTN) methods in the context of integrated HTN planning and LLM-based chatbots. Methods indicate when and how to decompose tasks into subtasks. Our method learner is built on top of the ChatHTN planner. ChatHTN queries ChatGPT to generate a decomposition of a task into primitive tasks when no applicable method for the task is available. In this work, we extend ChatHTN. Namely, when ChatGPT generates a task decomposition, ChatHTN learns from it, akin to memoization. However, unlike memoization, it learns a generalized method that applies not only to the specific instance encountered, but to other instances of the same task. We conduct experiments on two domains and demonstrate that our online learning procedure reduces the number of calls to ChatGPT while solving at least as many problems, and in some cases, even more.
* The Twelfth Annual Conference on Advances in Cognitive Systems (ACS-2025)
Computational Advantages of Multi-Grade Deep Learning: Convergence Analysis and Performance Insights
Jul 27, 2025Multi-grade deep learning (MGDL) has been shown to significantly outperform the standard single-grade deep learning (SGDL) across various applications. This work aims to investigate the computational advantages of MGDL focusing on its performance in image regression, denoising, and deblurring tasks, and comparing it to SGDL. We establish convergence results for the gradient descent (GD) method applied to these models and provide mathematical insights into MGDL's improved performance. In particular, we demonstrate that MGDL is more robust to the choice of learning rate under GD than SGDL. Furthermore, we analyze the eigenvalue distributions of the Jacobian matrices associated with the iterative schemes arising from the GD iterations, offering an explanation for MGDL's enhanced training stability.
Addressing Spectral Bias of Deep Neural Networks by Multi-Grade Deep Learning
Oct 21, 2024Deep neural networks (DNNs) suffer from the spectral bias, wherein DNNs typically exhibit a tendency to prioritize the learning of lower-frequency components of a function, struggling to capture its high-frequency features. This paper is to address this issue. Notice that a function having only low frequency components may be well-represented by a shallow neural network (SNN), a network having only a few layers. By observing that composition of low frequency functions can effectively approximate a high-frequency function, we propose to learn a function containing high-frequency components by composing several SNNs, each of which learns certain low-frequency information from the given data. We implement the proposed idea by exploiting the multi-grade deep learning (MGDL) model, a recently introduced model that trains a DNN incrementally, grade by grade, a current grade learning from the residue of the previous grade only an SNN composed with the SNNs trained in the preceding grades as features. We apply MGDL to synthetic, manifold, colored images, and MNIST datasets, all characterized by presence of high-frequency features. Our study reveals that MGDL excels at representing functions containing high-frequency information. Specifically, the neural networks learned in each grade adeptly capture some low-frequency information, allowing their compositions with SNNs learned in the previous grades effectively representing the high-frequency features. Our experimental results underscore the efficacy of MGDL in addressing the spectral bias inherent in DNNs. By leveraging MGDL, we offer insights into overcoming spectral bias limitation of DNNs, thereby enhancing the performance and applicability of deep learning models in tasks requiring the representation of high-frequency information. This study confirms that the proposed method offers a promising solution to address the spectral bias of DNNs.
A Dynamic Weighting Strategy to Mitigate Worker Node Failure in Distributed Deep Learning
Sep 14, 2024



The increasing complexity of deep learning models and the demand for processing vast amounts of data make the utilization of large-scale distributed systems for efficient training essential. These systems, however, face significant challenges such as communication overhead, hardware limitations, and node failure. This paper investigates various optimization techniques in distributed deep learning, including Elastic Averaging SGD (EASGD) and the second-order method AdaHessian. We propose a dynamic weighting strategy to mitigate the problem of straggler nodes due to failure, enhancing the performance and efficiency of the overall training process. We conduct experiments with different numbers of workers and communication periods to demonstrate improved convergence rates and test performance using our strategy.
Sparse Deep Learning Models with the $\ell_1$ Regularization
Aug 05, 2024



Sparse neural networks are highly desirable in deep learning in reducing its complexity. The goal of this paper is to study how choices of regularization parameters influence the sparsity level of learned neural networks. We first derive the $\ell_1$-norm sparsity-promoting deep learning models including single and multiple regularization parameters models, from a statistical viewpoint. We then characterize the sparsity level of a regularized neural network in terms of the choice of the regularization parameters. Based on the characterizations, we develop iterative algorithms for selecting regularization parameters so that the weight parameters of the resulting deep neural network enjoy prescribed sparsity levels. Numerical experiments are presented to demonstrate the effectiveness of the proposed algorithms in choosing desirable regularization parameters and obtaining corresponding neural networks having both of predetermined sparsity levels and satisfactory approximation accuracy.
Incorporating Domain Differential Equations into Graph Convolutional Networks to Lower Generalization Discrepancy
Apr 01, 2024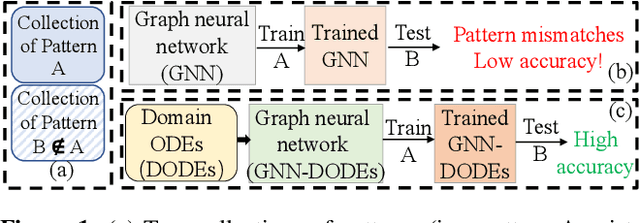

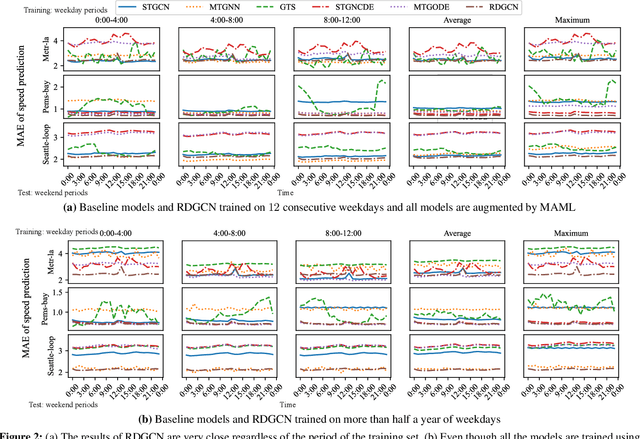

Ensuring both accuracy and robustness in time series prediction is critical to many applications, ranging from urban planning to pandemic management. With sufficient training data where all spatiotemporal patterns are well-represented, existing deep-learning models can make reasonably accurate predictions. However, existing methods fail when the training data are drawn from different circumstances (e.g., traffic patterns on regular days) compared to test data (e.g., traffic patterns after a natural disaster). Such challenges are usually classified under domain generalization. In this work, we show that one way to address this challenge in the context of spatiotemporal prediction is by incorporating domain differential equations into Graph Convolutional Networks (GCNs). We theoretically derive conditions where GCNs incorporating such domain differential equations are robust to mismatched training and testing data compared to baseline domain agnostic models. To support our theory, we propose two domain-differential-equation-informed networks called Reaction-Diffusion Graph Convolutional Network (RDGCN), which incorporates differential equations for traffic speed evolution, and Susceptible-Infectious-Recovered Graph Convolutional Network (SIRGCN), which incorporates a disease propagation model. Both RDGCN and SIRGCN are based on reliable and interpretable domain differential equations that allow the models to generalize to unseen patterns. We experimentally show that RDGCN and SIRGCN are more robust with mismatched testing data than the state-of-the-art deep learning methods.
Hypothesis Spaces for Deep Learning
Mar 11, 2024This paper introduces a hypothesis space for deep learning that employs deep neural networks (DNNs). By treating a DNN as a function of two variables, the physical variable and parameter variable, we consider the primitive set of the DNNs for the parameter variable located in a set of the weight matrices and biases determined by a prescribed depth and widths of the DNNs. We then complete the linear span of the primitive DNN set in a weak* topology to construct a Banach space of functions of the physical variable. We prove that the Banach space so constructed is a reproducing kernel Banach space (RKBS) and construct its reproducing kernel. We investigate two learning models, regularized learning and minimum interpolation problem in the resulting RKBS, by establishing representer theorems for solutions of the learning models. The representer theorems unfold that solutions of these learning models can be expressed as linear combination of a finite number of kernel sessions determined by given data and the reproducing kernel.