 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Grade Deep Learning for Partial Differential Equations with Applications to the Burgers Equation
Sep 14, 2023



We develop in this paper a multi-grade deep learning method for solving nonlinear partial differential equations (PDEs). Deep neural networks (DNNs) have received super performance in solving PDEs in addition to their outstanding success in areas such as natural language processing, computer vision, and robotics. However, training a very deep network is often a challenging task. As the number of layers of a DNN increases, solving a large-scale non-convex optimization problem that results in the DNN solution of PDEs becomes more and more difficult, which may lead to a decrease rather than an increase in predictive accuracy. To overcome this challenge, we propose a two-stage multi-grade deep learning (TS-MGDL) method that breaks down the task of learning a DNN into several neural networks stacked on top of each other in a staircase-like manner. This approach allows us to mitigate the complexity of solving the non-convex optimization problem with large number of parameters and learn residual components left over from previous grades efficiently. We prove that each grade/stage of the proposed TS-MGDL method can reduce the value of the loss function and further validate this fact through numerical experiments. Although the proposed method is applicable to general PDEs, implementation in this paper focuses only on the 1D, 2D, and 3D viscous Burgers equations. Experimental results show that the proposed two-stage multi-grade deep learning method enables efficient learning of solutions of the equations and outperforms existing single-grade deep learning methods in predictive accuracy. Specifically, the predictive errors of the single-grade deep learning are larger than those of the TS-MGDL method in 26-60, 4-31 and 3-12 times, for the 1D, 2D, and 3D equations, respectively.
Sparse Deep Neural Network for Nonlinear Partial Differential Equations
Jul 27, 2022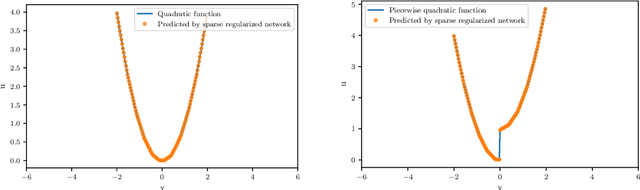


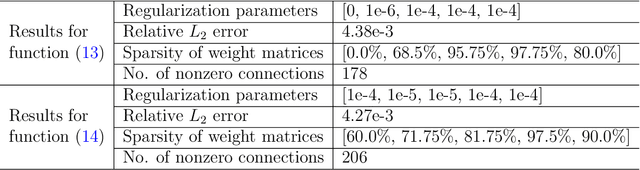
More competent learning models are demanded for data processing due to increasingly greater amounts of data available in applications. Data that we encounter often have certain embedded sparsity structures. That is, if they are represented in an appropriate basis, their energies can concentrate on a small number of basis functions. This paper is devoted to a numerical study of adaptive approximation of solutions of nonlinear partial differential equations whose solutions may have singularities, by deep neural networks (DNNs) with a sparse regularization with multiple parameters. Noting that DNNs have an intrinsic multi-scale structure which is favorable for adaptive representation of functions, by employing a penalty with multiple parameters, we develop DNNs with a multi-scale sparse regularization (SDNN) for effectively representing functions having certain singularities. We then apply the proposed SDNN to numerical solutions of the Burgers equation and the Schr\"odinger equation. Numerical examples confirm that solutions generated by the proposed SDNN are sparse and accurate.