 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Sparsity Inducing Regularization Methods for Machine Learning
Mar 25, 2013During the past years there has been an explosion of interest in learning methods based on sparsity regularization. In this paper, we discuss a general class of such methods, in which the regularizer can be expressed as the composition of a convex function $\omega$ with a linear function. This setting includes several methods such the group Lasso, the Fused Lasso, multi-task learning and many more. We present a general approach for solving regularization problems of this kind, under the assumption that the proximity operator of the function $\omega$ is available. Furthermore, we comment on the application of this approach to support vector machines, a technique pioneered by the groundbreaking work of Vladimir Vapnik.
Efficient First Order Methods for Linear Composite Regularizers
Apr 07, 2011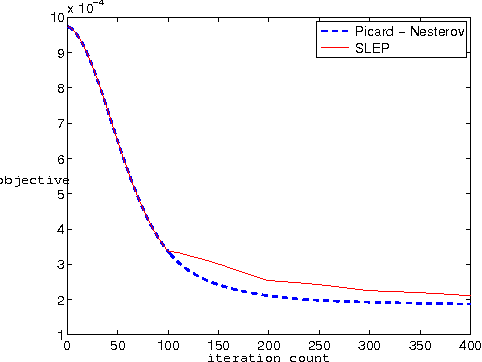
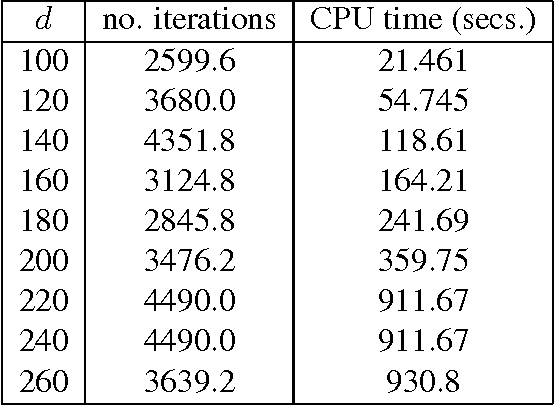
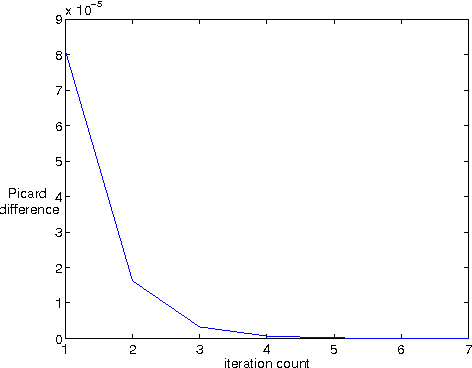
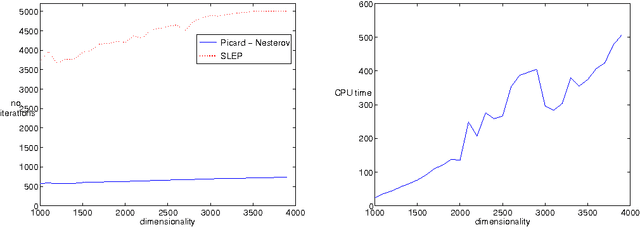
A wide class of regularization problems in machine learning and statistics employ a regularization term which is obtained by composing a simple convex function \omega with a linear transformation. This setting includes Group Lasso methods, the Fused Lasso and other total variation methods, multi-task learning methods and many more. In this paper, we present a general approach for computing the proximity operator of this class of regularizers, under the assumption that the proximity operator of the function \omega is known in advance. Our approach builds on a recent line of research on optimal first order optimization methods and uses fixed point iterations for numerically computing the proximity operator. It is more general than current approaches and, as we show with numerical simulations, computationally more efficient than available first order methods which do not achieve the optimal rate. In particular, our method outperforms state of the art O(1/T) methods for overlapping Group Lasso and matches optimal O(1/T^2) methods for the Fused Lasso and tree structured Group Lasso.
Regularizers for Structured Sparsity
Mar 30, 2011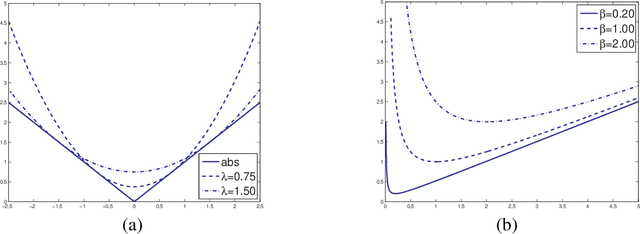



We study the problem of learning a sparse linear regression vector under additional conditions on the structure of its sparsity pattern. This problem is relevant in machine learning, statistics and signal processing. It is well known that a linear regression can benefit from knowledge that the underlying regression vector is sparse. The combinatorial problem of selecting the nonzero components of this vector can be "relaxed" by regularizing the squared error with a convex penalty function like the $\ell_1$ norm. However, in many applications, additional conditions on the structure of the regression vector and its sparsity pattern are available. Incorporating this information into the learning method may lead to a significant decrease of the estimation error. In this paper, we present a family of convex penalty functions, which encode prior knowledge on the structure of the vector formed by the absolute values of the regression coefficients. This family subsumes the $\ell_1$ norm and is flexible enough to include different models of sparsity patterns, which are of practical and theoretical importance. We establish the basic properties of these penalty functions and discuss some examples where they can be computed explicitly. Moreover, we present a convergent optimization algorithm for solving regularized least squares with these penalty functions. Numerical simulations highlight the benefit of structured sparsity and the advantage offered by our approach over the Lasso method and other related methods.