 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReproducible evaluation of classification methods in Alzheimer's disease: framework and application to MRI and PET data
Aug 20, 2018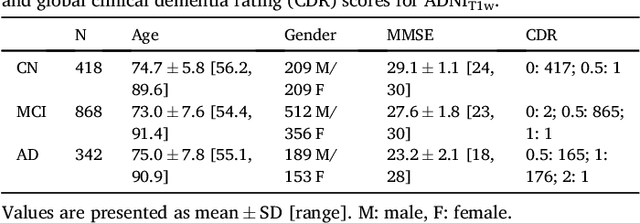
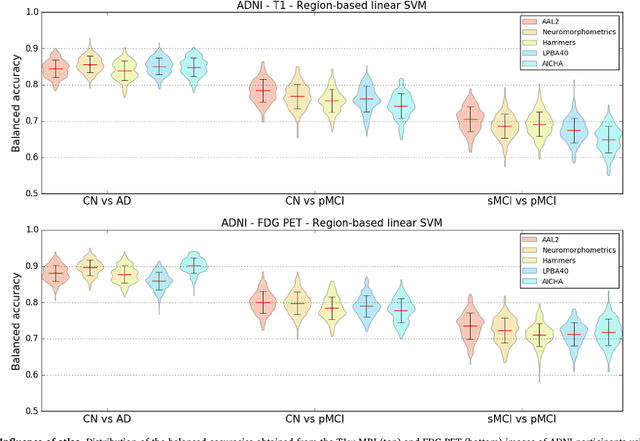
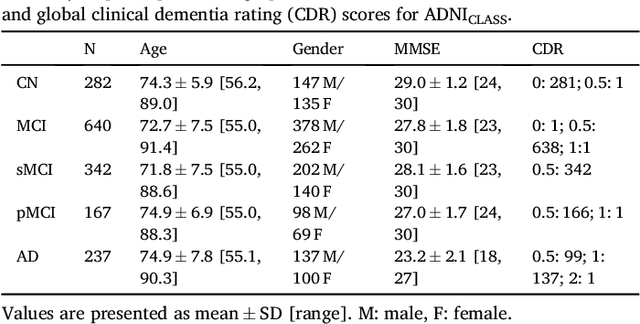
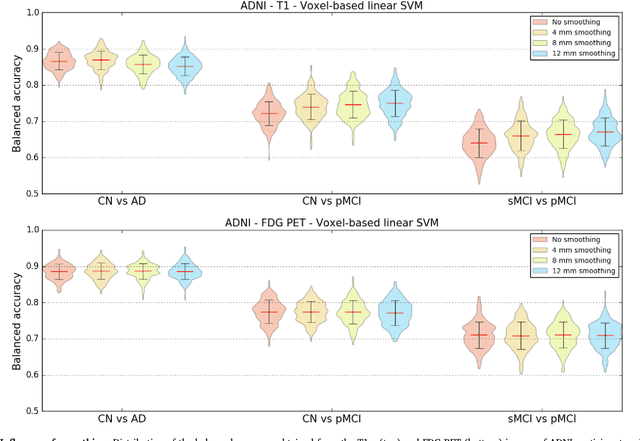
A large number of papers have introduced novel machine learning and feature extraction methods for automatic classification of AD. However, they are difficult to reproduce because key components of the validation are often not readily available. These components include selected participants and input data, image preprocessing and cross-validation procedures. The performance of the different approaches is also difficult to compare objectively. In particular, it is often difficult to assess which part of the method provides a real improvement, if any. We propose a framework for reproducible and objective classification experiments in AD using three publicly available datasets (ADNI, AIBL and OASIS). The framework comprises: i) automatic conversion of the three datasets into BIDS format, ii) a modular set of preprocessing pipelines, feature extraction and classification methods, together with an evaluation framework, that provide a baseline for benchmarking the different components. We demonstrate the use of the framework for a large-scale evaluation on 1960 participants using T1 MRI and FDG PET data. In this evaluation, we assess the influence of different modalities, preprocessing, feature types, classifiers, training set sizes and datasets. Performances were in line with the state-of-the-art. FDG PET outperformed T1 MRI for all classification tasks. No difference in performance was found for the use of different atlases, image smoothing, partial volume correction of FDG PET images, or feature type. Linear SVM and L2-logistic regression resulted in similar performance and both outperformed random forests. The classification performance increased along with the number of subjects used for training. Classifiers trained on ADNI generalized well to AIBL and OASIS. All the code of the framework and the experiments is publicly available at: https://gitlab.icm-institute.org/aramislab/AD-ML.
Yet Another ADNI Machine Learning Paper? Paving The Way Towards Fully-reproducible Research on Classification of Alzheimer's Disease
Sep 21, 2017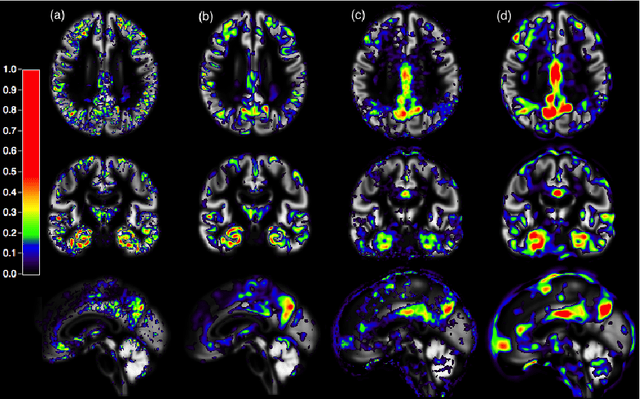
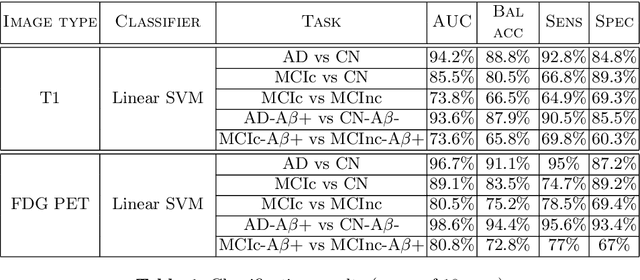
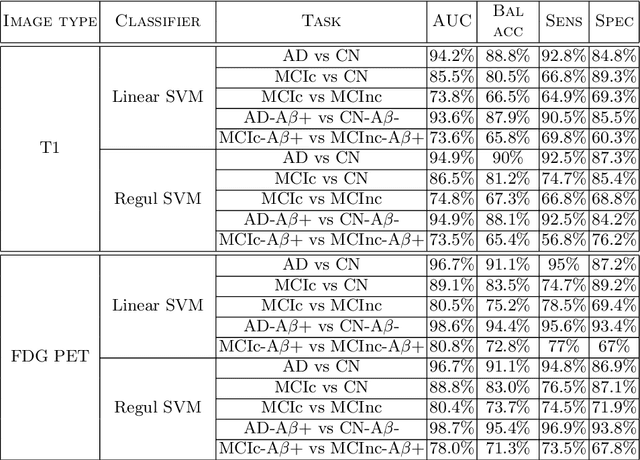
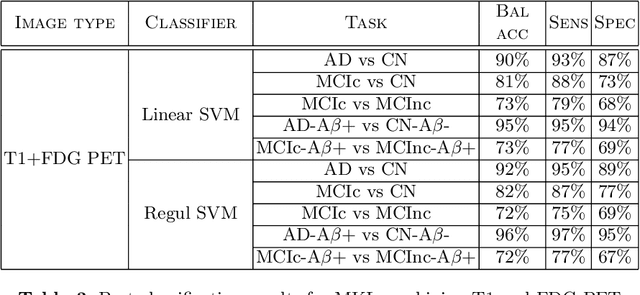
In recent years, the number of papers on Alzheimer's disease classification has increased dramatically, generating interesting methodological ideas on the use machine learning and feature extraction methods. However, practical impact is much more limited and, eventually, one could not tell which of these approaches are the most efficient. While over 90\% of these works make use of ADNI an objective comparison between approaches is impossible due to variations in the subjects included, image pre-processing, performance metrics and cross-validation procedures. In this paper, we propose a framework for reproducible classification experiments using multimodal MRI and PET data from ADNI. The core components are: 1) code to automatically convert the full ADNI database into BIDS format; 2) a modular architecture based on Nipype in order to easily plug-in different classification and feature extraction tools; 3) feature extraction pipelines for MRI and PET data; 4) baseline classification approaches for unimodal and multimodal features. This provides a flexible framework for benchmarking different feature extraction and classification tools in a reproducible manner. We demonstrate its use on all (1519) baseline T1 MR images and all (1102) baseline FDG PET images from ADNI 1, GO and 2 with SPM-based feature extraction pipelines and three different classification techniques (linear SVM, anatomically regularized SVM and multiple kernel learning SVM). The highest accuracies achieved were: 91% for AD vs CN, 83% for MCIc vs CN, 75% for MCIc vs MCInc, 94% for AD-A$\beta$+ vs CN-A$\beta$- and 72% for MCIc-A$\beta$+ vs MCInc-A$\beta$+. The code is publicly available at https://gitlab.icm-institute.org/aramislab/AD-ML (depends on the Clinica software platform, publicly available at http://www.clinica.run).