 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphXAIN: Narratives to Explain Graph Neural Networks
Nov 04, 2024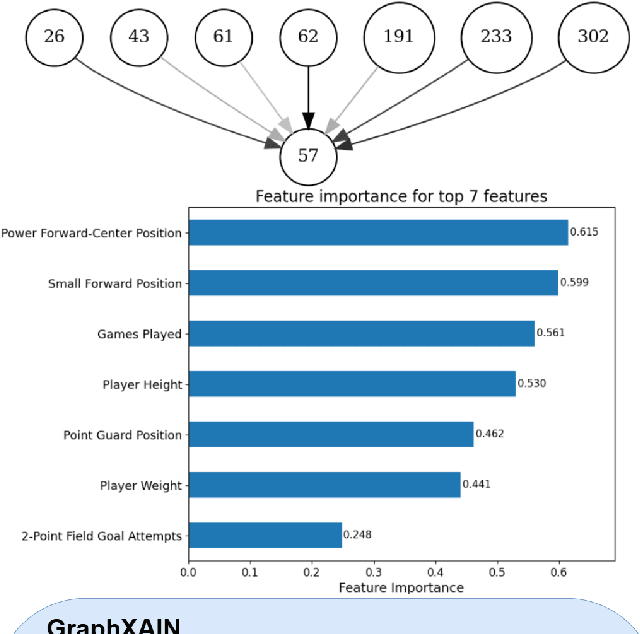
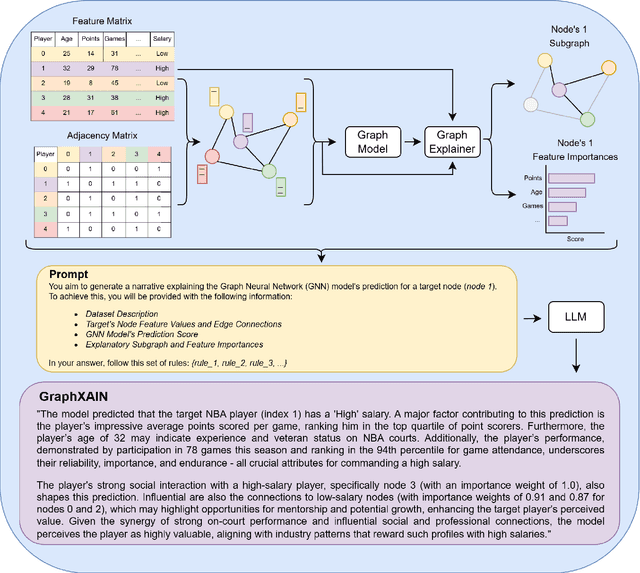
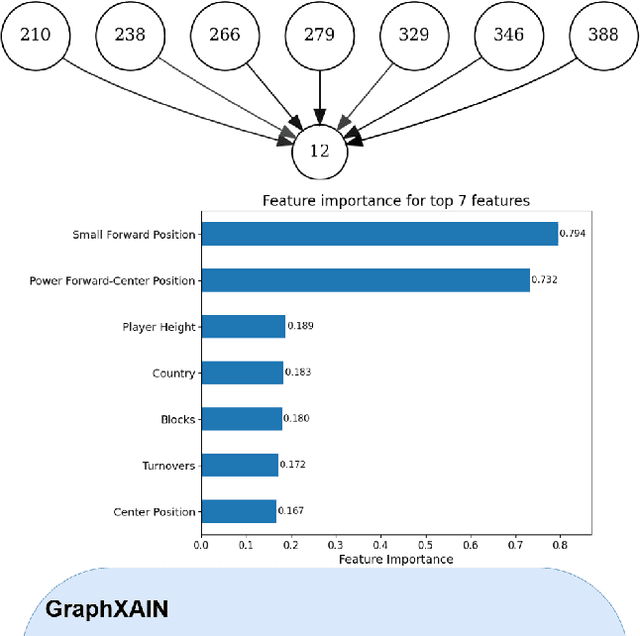
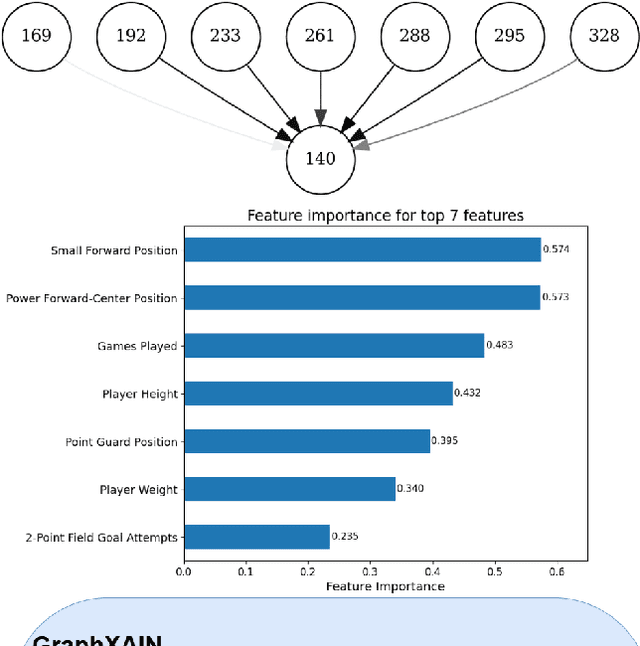
Graph Neural Networks (GNNs) are a powerful technique for machine learning on graph-structured data, yet they pose interpretability challenges, especially for non-expert users. Existing GNN explanation methods often yield technical outputs such as subgraphs and feature importance scores, which are not easily understood. Building on recent insights from social science and other Explainable AI (XAI) methods, we propose GraphXAIN, a natural language narrative that explains individual predictions made by GNNs. We present a model-agnostic and explainer-agnostic XAI approach that complements graph explainers by generating GraphXAINs, using Large Language Models (LLMs) and integrating graph data, individual predictions from GNNs, explanatory subgraphs, and feature importances. We define XAI Narratives and XAI Descriptions, highlighting their distinctions and emphasizing the importance of narrative principles in effective explanations. By incorporating natural language narratives, our approach supports graph practitioners and non-expert users, aligning with social science research on explainability and enhancing user understanding and trust in complex GNN models. We demonstrate GraphXAIN's capabilities on a real-world graph dataset, illustrating how its generated narratives can aid understanding compared to traditional graph explainer outputs or other descriptive explanation methods.
Beyond the Black Box: Do More Complex Models Provide Superior XAI Explanations?
May 14, 2024The increasing complexity of Artificial Intelligence models poses challenges to interpretability, particularly in the healthcare sector. This study investigates the impact of deep learning model complexity and Explainable AI (XAI) efficacy, utilizing four ResNet architectures (ResNet-18, 34, 50, 101). Through methodical experimentation on 4,369 lung X-ray images of COVID-19-infected and healthy patients, the research evaluates models' classification performance and the relevance of corresponding XAI explanations with respect to the ground-truth disease masks. Results indicate that the increase in model complexity is associated with a decrease in classification accuracy and AUC-ROC scores (ResNet-18: 98.4%, 0.997; ResNet-101: 95.9%, 0.988). Notably, in eleven out of twelve statistical tests performed, no statistically significant differences occurred between XAI quantitative metrics - Relevance Rank Accuracy and the proposed Positive Attribution Ratio - across trained models. These results suggest that increased model complexity does not consistently lead to higher performance or relevance of explanations for models' decision-making processes.