 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Black Box: Do More Complex Models Provide Superior XAI Explanations?
May 14, 2024The increasing complexity of Artificial Intelligence models poses challenges to interpretability, particularly in the healthcare sector. This study investigates the impact of deep learning model complexity and Explainable AI (XAI) efficacy, utilizing four ResNet architectures (ResNet-18, 34, 50, 101). Through methodical experimentation on 4,369 lung X-ray images of COVID-19-infected and healthy patients, the research evaluates models' classification performance and the relevance of corresponding XAI explanations with respect to the ground-truth disease masks. Results indicate that the increase in model complexity is associated with a decrease in classification accuracy and AUC-ROC scores (ResNet-18: 98.4%, 0.997; ResNet-101: 95.9%, 0.988). Notably, in eleven out of twelve statistical tests performed, no statistically significant differences occurred between XAI quantitative metrics - Relevance Rank Accuracy and the proposed Positive Attribution Ratio - across trained models. These results suggest that increased model complexity does not consistently lead to higher performance or relevance of explanations for models' decision-making processes.
Enabling Machine Learning Algorithms for Credit Scoring -- Explainable Artificial Intelligence (XAI) methods for clear understanding complex predictive models
Apr 14, 2021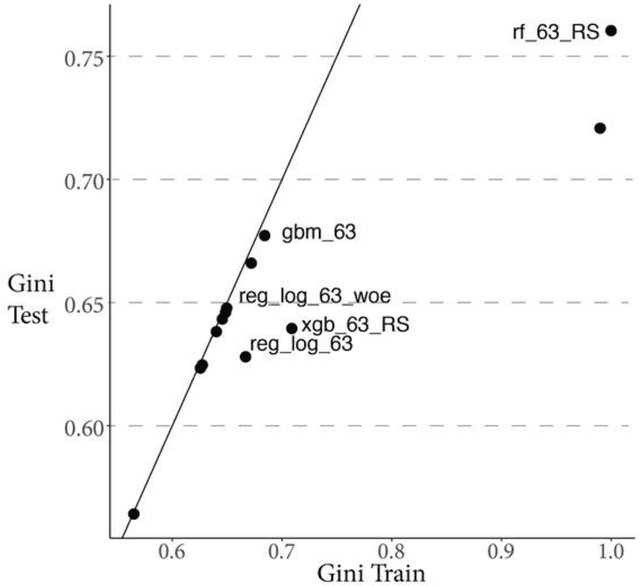
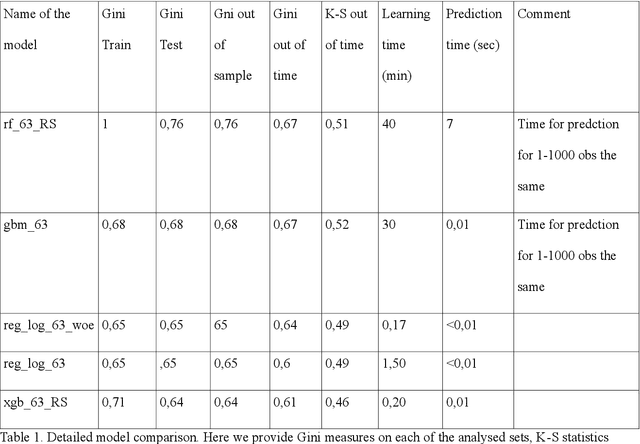
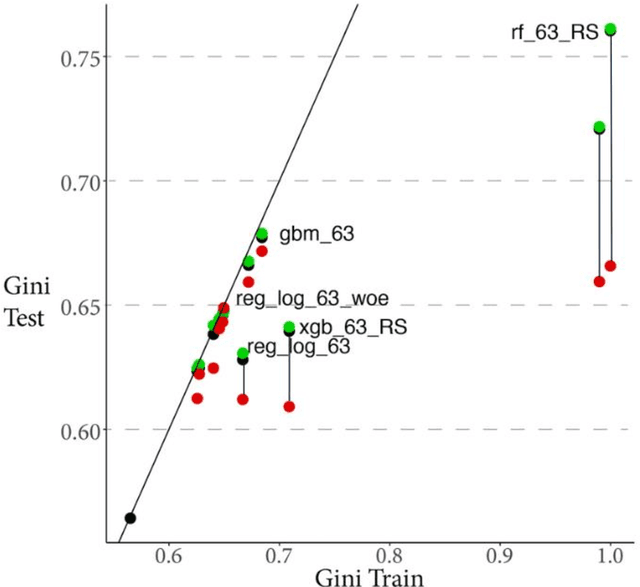
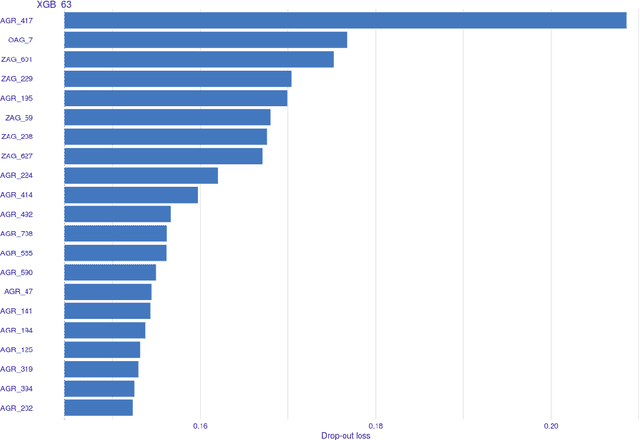
Rapid development of advanced modelling techniques gives an opportunity to develop tools that are more and more accurate. However as usually, everything comes with a price and in this case, the price to pay is to loose interpretability of a model while gaining on its accuracy and precision. For managers to control and effectively manage credit risk and for regulators to be convinced with model quality the price to pay is too high. In this paper, we show how to take credit scoring analytics in to the next level, namely we present comparison of various predictive models (logistic regression, logistic regression with weight of evidence transformations and modern artificial intelligence algorithms) and show that advanced tree based models give best results in prediction of client default. What is even more important and valuable we also show how to boost advanced models using techniques which allow to interpret them and made them more accessible for credit risk practitioners, resolving the crucial obstacle in widespread deployment of more complex, 'black box' models like random forests, gradient boosted or extreme gradient boosted trees. All this will be shown on the large dataset obtained from the Polish Credit Bureau to which all the banks and most of the lending companies in the country do report the credit files. In this paper the data from lending companies were used. The paper then compares state of the art best practices in credit risk modelling with new advanced modern statistical tools boosted by the latest developments in the field of interpretability and explainability of artificial intelligence algorithms. We believe that this is a valuable contribution when it comes to presentation of different modelling tools but what is even more important it is showing which methods might be used to get insight and understanding of AI methods in credit risk context.