 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Machine Learning Algorithms for Credit Scoring -- Explainable Artificial Intelligence (XAI) methods for clear understanding complex predictive models
Apr 14, 2021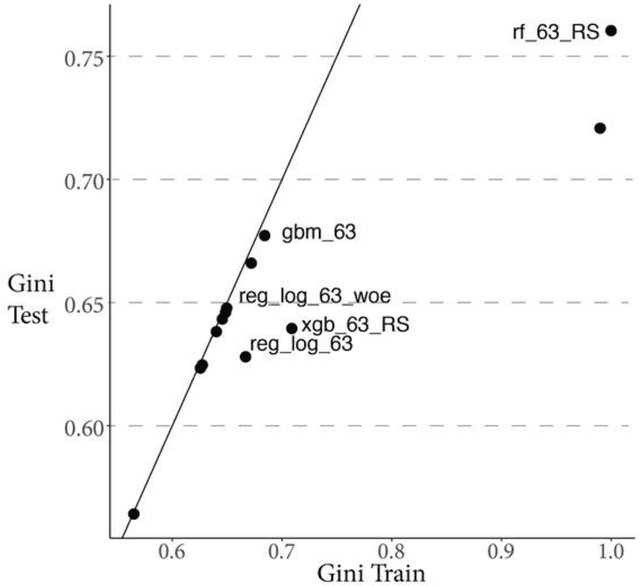
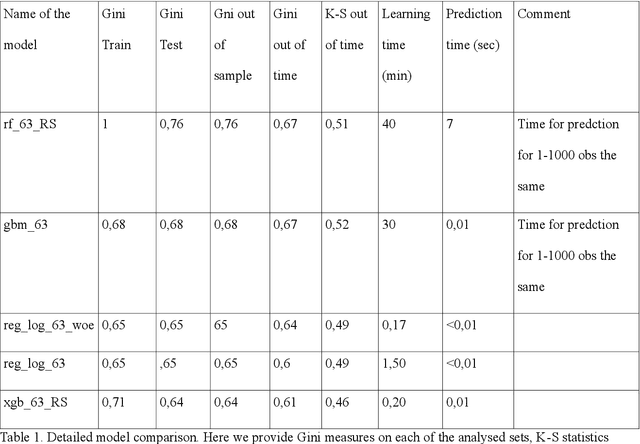
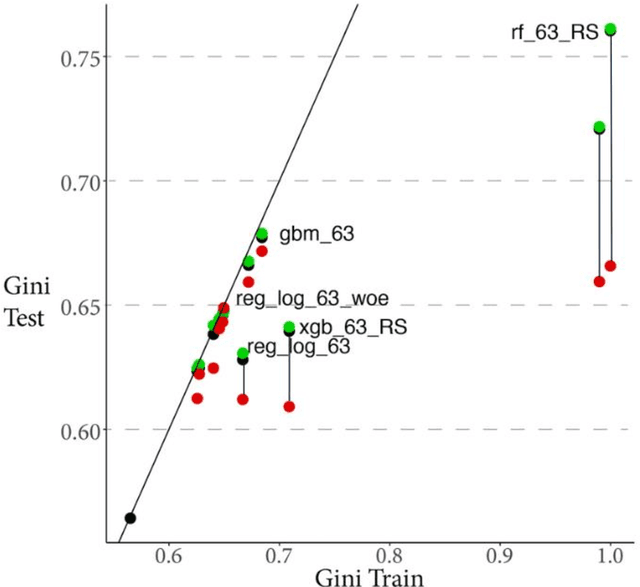
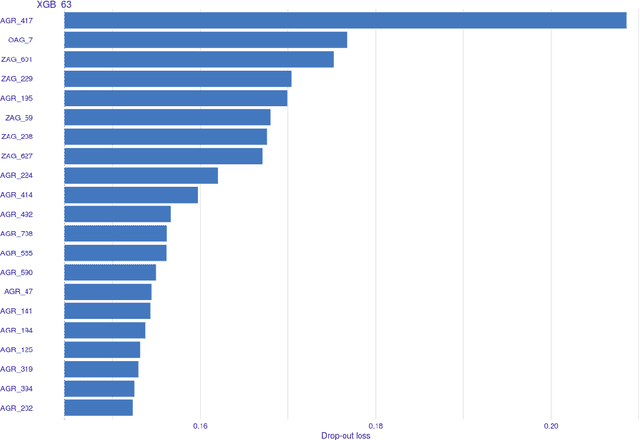
Rapid development of advanced modelling techniques gives an opportunity to develop tools that are more and more accurate. However as usually, everything comes with a price and in this case, the price to pay is to loose interpretability of a model while gaining on its accuracy and precision. For managers to control and effectively manage credit risk and for regulators to be convinced with model quality the price to pay is too high. In this paper, we show how to take credit scoring analytics in to the next level, namely we present comparison of various predictive models (logistic regression, logistic regression with weight of evidence transformations and modern artificial intelligence algorithms) and show that advanced tree based models give best results in prediction of client default. What is even more important and valuable we also show how to boost advanced models using techniques which allow to interpret them and made them more accessible for credit risk practitioners, resolving the crucial obstacle in widespread deployment of more complex, 'black box' models like random forests, gradient boosted or extreme gradient boosted trees. All this will be shown on the large dataset obtained from the Polish Credit Bureau to which all the banks and most of the lending companies in the country do report the credit files. In this paper the data from lending companies were used. The paper then compares state of the art best practices in credit risk modelling with new advanced modern statistical tools boosted by the latest developments in the field of interpretability and explainability of artificial intelligence algorithms. We believe that this is a valuable contribution when it comes to presentation of different modelling tools but what is even more important it is showing which methods might be used to get insight and understanding of AI methods in credit risk context.
Transparency, Auditability and eXplainability of Machine Learning Models in Credit Scoring
Sep 28, 2020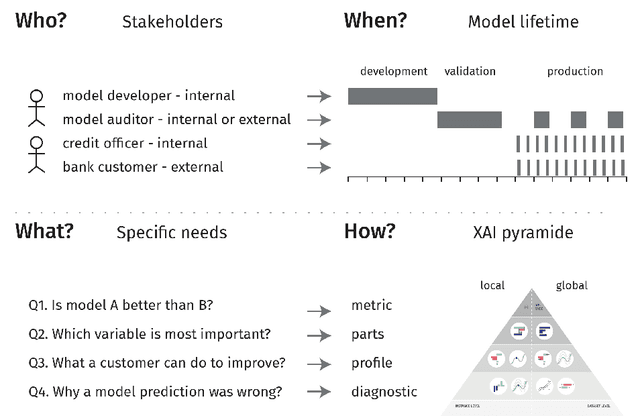
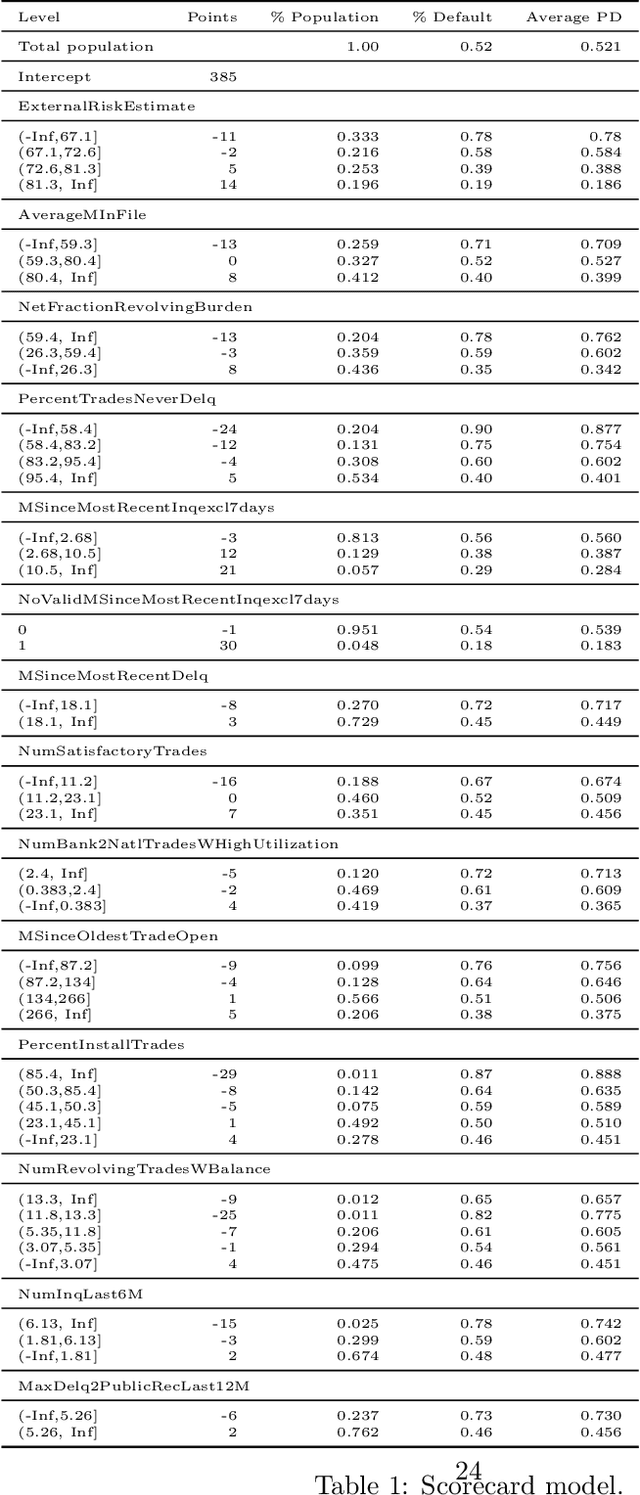
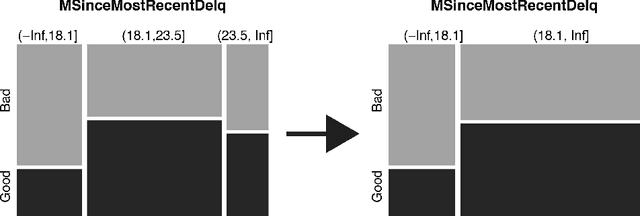
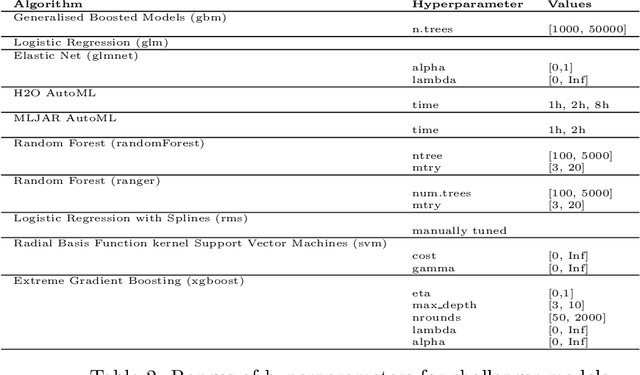
A major requirement for credit scoring models is to provide a maximally accurate risk prediction. Additionally, regulators demand these models to be transparent and auditable. Thus, in credit scoring, very simple predictive models such as logistic regression or decision trees are still widely used and the superior predictive power of modern machine learning algorithms cannot be fully leveraged. Significant potential is therefore missed, leading to higher reserves or more credit defaults. This paper works out different dimensions that have to be considered for making credit scoring models understandable and presents a framework for making ``black box'' machine learning models transparent, auditable and explainable. Following this framework, we present an overview of techniques, demonstrate how they can be applied in credit scoring and how results compare to the interpretability of score cards. A real world case study shows that a comparable degree of interpretability can be achieved while machine learning techniques keep their ability to improve predictive power.
Landscape of R packages for eXplainable Artificial Intelligence
Sep 24, 2020



The growing availability of data and computing power fuels the development of predictive models. In order to ensure the safe and effective functioning of such models, we need methods for exploration, debugging, and validation. New methods and tools for this purpose are being developed within the eXplainable Artificial Intelligence (XAI) subdomain of machine learning. In this work (1) we present the taxonomy of methods for model explanations, (2) we identify and compare 27 packages available in R to perform XAI analysis, (3) we present an example of an application of particular packages, (4) we acknowledge recent trends in XAI. The article is primarily devoted to the tools available in R, but since it is easy to integrate the Python code, we will also show examples for the most popular libraries from Python.
Interpretable Meta-Measure for Model Performance
Jun 02, 2020

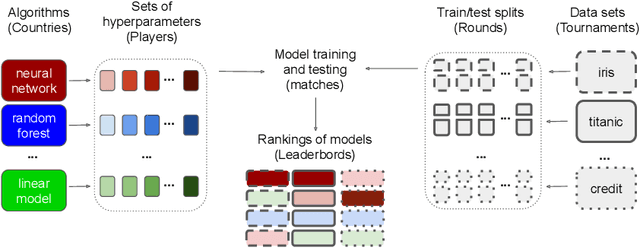

Measures for evaluation of model performance play an important role in Machine Learning. However, the most common performance measures share several limitations. The difference in performance for two models has no probabilistic interpretation and there is no reference point to indicate whether they represent a significant improvement. What is more, it makes no sense to compare such differences between data sets. In this article, we introduce a new meta-measure for performance assessment named Elo-based Predictive Power (EPP). The differences in EPP scores have probabilistic interpretation and can be directly compared between data sets. We prove the mathematical properties of EPP and support them with empirical results of a~large scale benchmark on 30 classification data sets. Finally, we show applications of EPP to the selected meta-learning problems and challenges beyond ML benchmarks.
Lifting Interpretability-Performance Trade-off via Automated Feature Engineering
Feb 11, 2020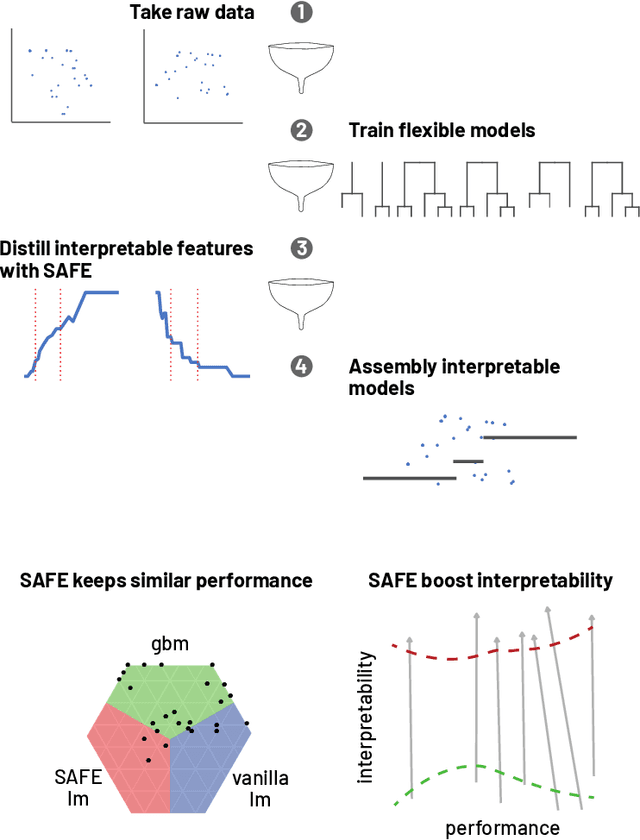

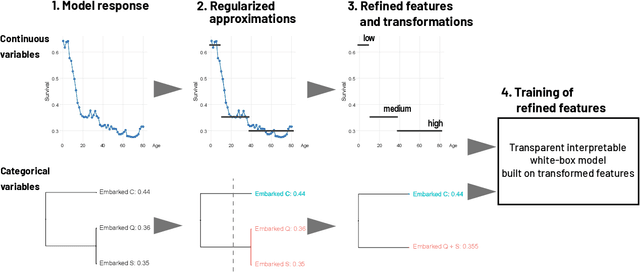

Complex black-box predictive models may have high performance, but lack of interpretability causes problems like lack of trust, lack of stability, sensitivity to concept drift. On the other hand, achieving satisfactory accuracy of interpretable models require more time-consuming work related to feature engineering. Can we train interpretable and accurate models, without timeless feature engineering? We propose a method that uses elastic black-boxes as surrogate models to create a simpler, less opaque, yet still accurate and interpretable glass-box models. New models are created on newly engineered features extracted with the help of a surrogate model. We supply the analysis by a large-scale benchmark on several tabular data sets from the OpenML database. There are two results 1) extracting information from complex models may improve the performance of linear models, 2) questioning a common myth that complex machine learning models outperform linear models.
EPP: interpretable score of model predictive power
Aug 24, 2019



The most important part of model selection and hyperparameter tuning is the evaluation of model performance. The most popular measures, such as AUC, F1, ACC for binary classification, or RMSE, MAD for regression, or cross-entropy for multilabel classification share two common weaknesses. First is, that they are not on an interval scale. It means that the difference in performance for the two models has no direct interpretation. It makes no sense to compare such differences between datasets. Second is, that for k-fold cross-validation, the model performance is in most cases calculated as an average performance from particular folds, which neglects the information how stable is the performance for different folds. In this talk, we introduce a new EPP rating system for predictive models. We also demonstrate numerous advantages for this system, First, differences in EPP scores have probabilistic interpretation. Based on it we can assess the probability that one model will achieve better performance than another. Second, EPP scores can be directly compared between datasets. Third, they can be used for navigated hyperparameter tuning and model selection. Forth, we can create embeddings for datasets based on EPP scores.
iBreakDown: Uncertainty of Model Explanations for Non-additive Predictive Models
Mar 27, 2019
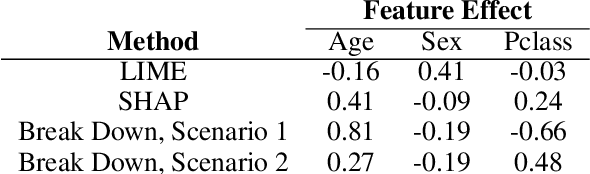
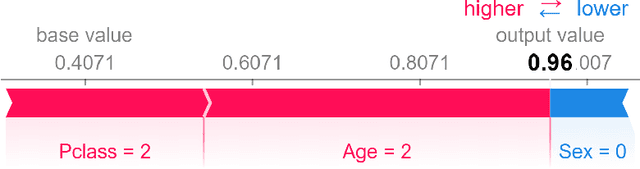
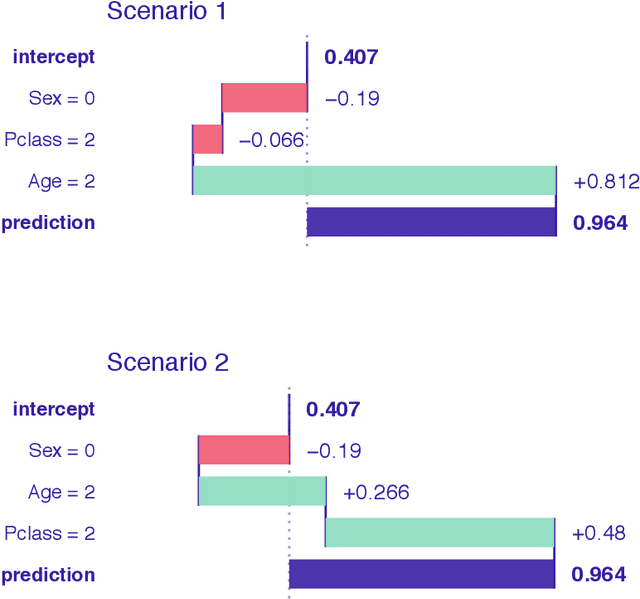
Explainable Artificial Intelligence (XAI) brings a lot of attention recently. Explainability is being presented as a remedy for lack of trust in model predictions. Model agnostic tools such as LIME, SHAP, or Break Down promise instance level interpretability for any complex machine learning model. But how certain are these explanations? Can we rely on additive explanations for non-additive models? In this paper, we examine the behavior of model explainers under the presence of interactions. We define two sources of uncertainty, model level uncertainty, and explanation level uncertainty. We show that adding interactions reduces explanation level uncertainty. We introduce a new method iBreakDown that generates non-additive explanations with local interaction.
SAFE ML: Surrogate Assisted Feature Extraction for Model Learning
Feb 28, 2019

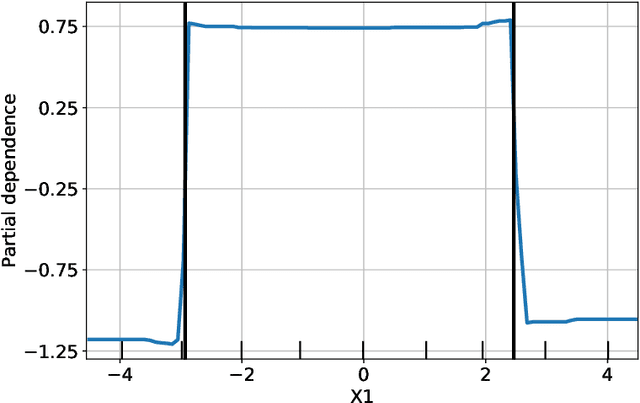
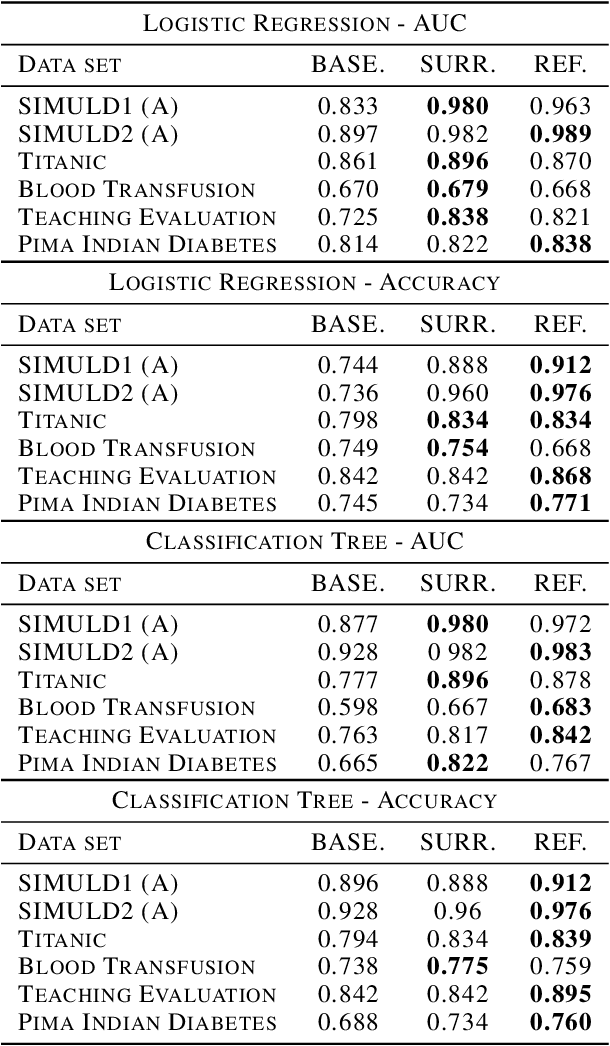
Complex black-box predictive models may have high accuracy, but opacity causes problems like lack of trust, lack of stability, sensitivity to concept drift. On the other hand, interpretable models require more work related to feature engineering, which is very time consuming. Can we train interpretable and accurate models, without timeless feature engineering? In this article, we show a method that uses elastic black-boxes as surrogate models to create a simpler, less opaque, yet still accurate and interpretable glass-box models. New models are created on newly engineered features extracted/learned with the help of a surrogate model. We show applications of this method for model level explanations and possible extensions for instance level explanations. We also present an example implementation in Python and benchmark this method on a number of tabular data sets.
auditor: an R Package for Model-Agnostic Visual Validation and Diagnostic
Oct 03, 2018


Machine learning has spread to almost every area of life. It is successfully applied in biology, medicine, finance, physics, and other fields. The problem arises if models fail when confronted with the real-world data. Therefore, there is a need for validation methods. This paper describes methodology and tools for model-agnostic audit. Introduced techniques facilitate assessing and comparing the goodness of fit and performance of models. In addition, they may be used for analysis of the similarity of residuals and for the identification of outliers and influential observations. The examination is carried out by diagnostic scores and visual verification. Presented methods are implemented in the auditor package for R. Due to the flexible and consistent grammar, it is simple to validate models of any classes.