 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Meta-Measure for Model Performance
Paper and Code


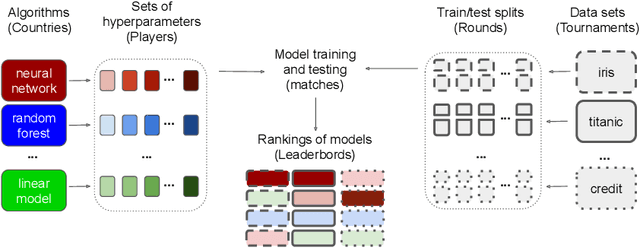

Measures for evaluation of model performance play an important role in Machine Learning. However, the most common performance measures share several limitations. The difference in performance for two models has no probabilistic interpretation and there is no reference point to indicate whether they represent a significant improvement. What is more, it makes no sense to compare such differences between data sets. In this article, we introduce a new meta-measure for performance assessment named Elo-based Predictive Power (EPP). The differences in EPP scores have probabilistic interpretation and can be directly compared between data sets. We prove the mathematical properties of EPP and support them with empirical results of a~large scale benchmark on 30 classification data sets. Finally, we show applications of EPP to the selected meta-learning problems and challenges beyond ML benchmarks.