 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriplot: model agnostic measures and visualisations for variable importance in predictive models that take into account the hierarchical correlation structure
Apr 07, 2021
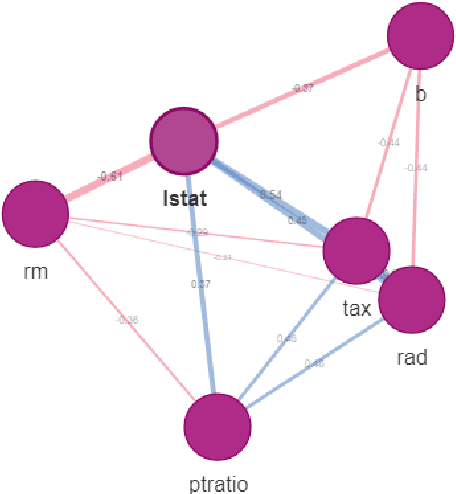

One of the key elements of explanatory analysis of a predictive model is to assess the importance of individual variables. Rapid development of the area of predictive model exploration (also called explainable artificial intelligence or interpretable machine learning) has led to the popularization of methods for local (instance level) and global (dataset level) methods, such as Permutational Variable Importance, Shapley Values (SHAP), Local Interpretable Model Explanations (LIME), Break Down and so on. However, these methods do not use information about the correlation between features which significantly reduce the explainability of the model behaviour. In this work, we propose new methods to support model analysis by exploiting the information about the correlation between variables. The dataset level aspect importance measure is inspired by the block permutations procedure, while the instance level aspect importance measure is inspired by the LIME method. We show how to analyze groups of variables (aspects) both when they are proposed by the user and when they should be determined automatically based on the hierarchical structure of correlations between variables. Additionally, we present the new type of model visualisation, triplot, which exploits a hierarchical structure of variable grouping to produce a high information density model visualisation. This visualisation provides a consistent illustration for either local or global model and data exploration. We also show an example of real-world data with 5k instances and 37 features in which a significant correlation between variables affects the interpretation of the effect of variable importance. The proposed method is, to our knowledge, the first to allow direct use of the correlation between variables in exploratory model analysis.
Interpretable Meta-Measure for Model Performance
Jun 02, 2020

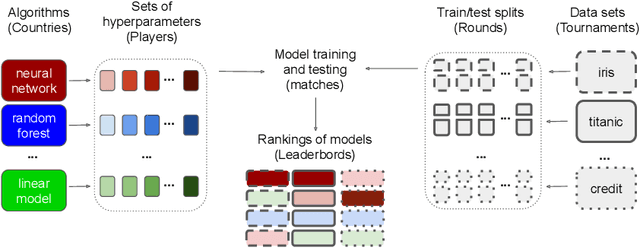

Measures for evaluation of model performance play an important role in Machine Learning. However, the most common performance measures share several limitations. The difference in performance for two models has no probabilistic interpretation and there is no reference point to indicate whether they represent a significant improvement. What is more, it makes no sense to compare such differences between data sets. In this article, we introduce a new meta-measure for performance assessment named Elo-based Predictive Power (EPP). The differences in EPP scores have probabilistic interpretation and can be directly compared between data sets. We prove the mathematical properties of EPP and support them with empirical results of a~large scale benchmark on 30 classification data sets. Finally, we show applications of EPP to the selected meta-learning problems and challenges beyond ML benchmarks.
EPP: interpretable score of model predictive power
Aug 24, 2019



The most important part of model selection and hyperparameter tuning is the evaluation of model performance. The most popular measures, such as AUC, F1, ACC for binary classification, or RMSE, MAD for regression, or cross-entropy for multilabel classification share two common weaknesses. First is, that they are not on an interval scale. It means that the difference in performance for the two models has no direct interpretation. It makes no sense to compare such differences between datasets. Second is, that for k-fold cross-validation, the model performance is in most cases calculated as an average performance from particular folds, which neglects the information how stable is the performance for different folds. In this talk, we introduce a new EPP rating system for predictive models. We also demonstrate numerous advantages for this system, First, differences in EPP scores have probabilistic interpretation. Based on it we can assess the probability that one model will achieve better performance than another. Second, EPP scores can be directly compared between datasets. Third, they can be used for navigated hyperparameter tuning and model selection. Forth, we can create embeddings for datasets based on EPP scores.