 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransparency, Auditability and eXplainability of Machine Learning Models in Credit Scoring
Paper and Code
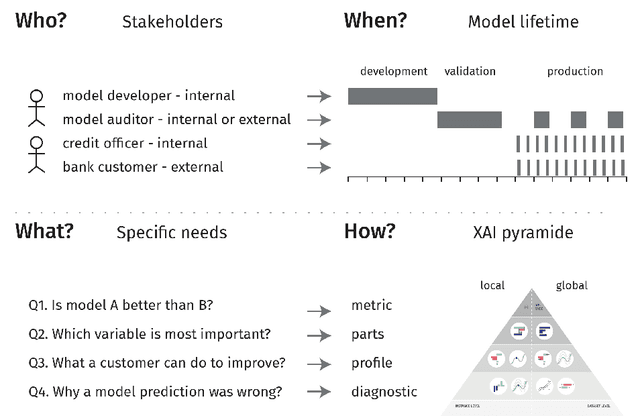
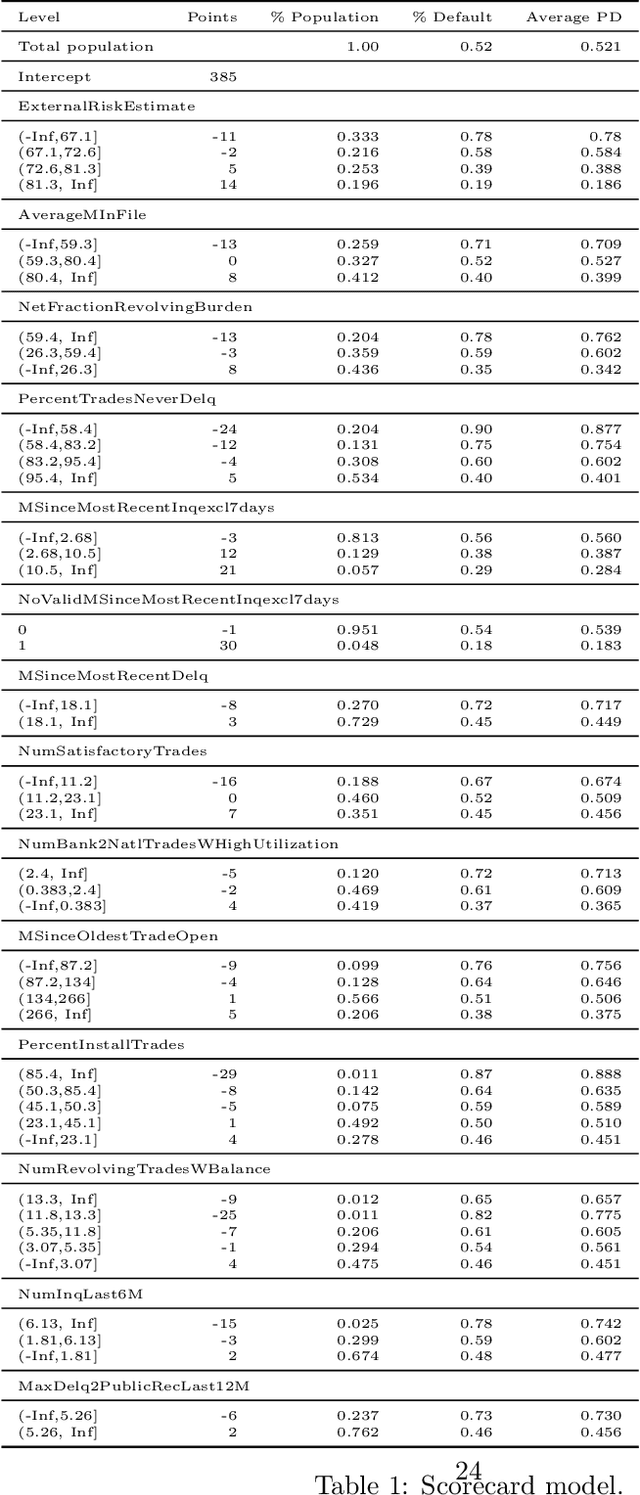
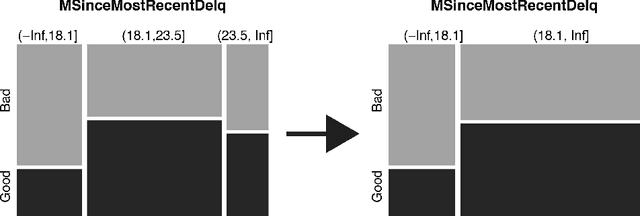
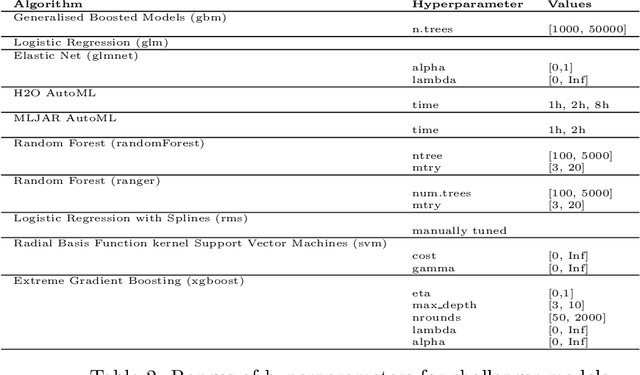
A major requirement for credit scoring models is to provide a maximally accurate risk prediction. Additionally, regulators demand these models to be transparent and auditable. Thus, in credit scoring, very simple predictive models such as logistic regression or decision trees are still widely used and the superior predictive power of modern machine learning algorithms cannot be fully leveraged. Significant potential is therefore missed, leading to higher reserves or more credit defaults. This paper works out different dimensions that have to be considered for making credit scoring models understandable and presents a framework for making ``black box'' machine learning models transparent, auditable and explainable. Following this framework, we present an overview of techniques, demonstrate how they can be applied in credit scoring and how results compare to the interpretability of score cards. A real world case study shows that a comparable degree of interpretability can be achieved while machine learning techniques keep their ability to improve predictive power.