 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransparency, Auditability and eXplainability of Machine Learning Models in Credit Scoring
Sep 28, 2020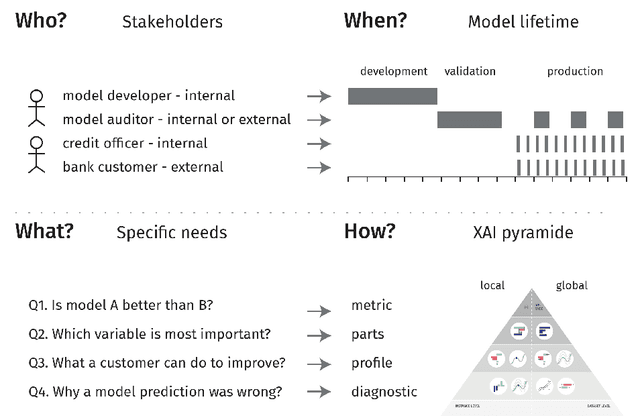
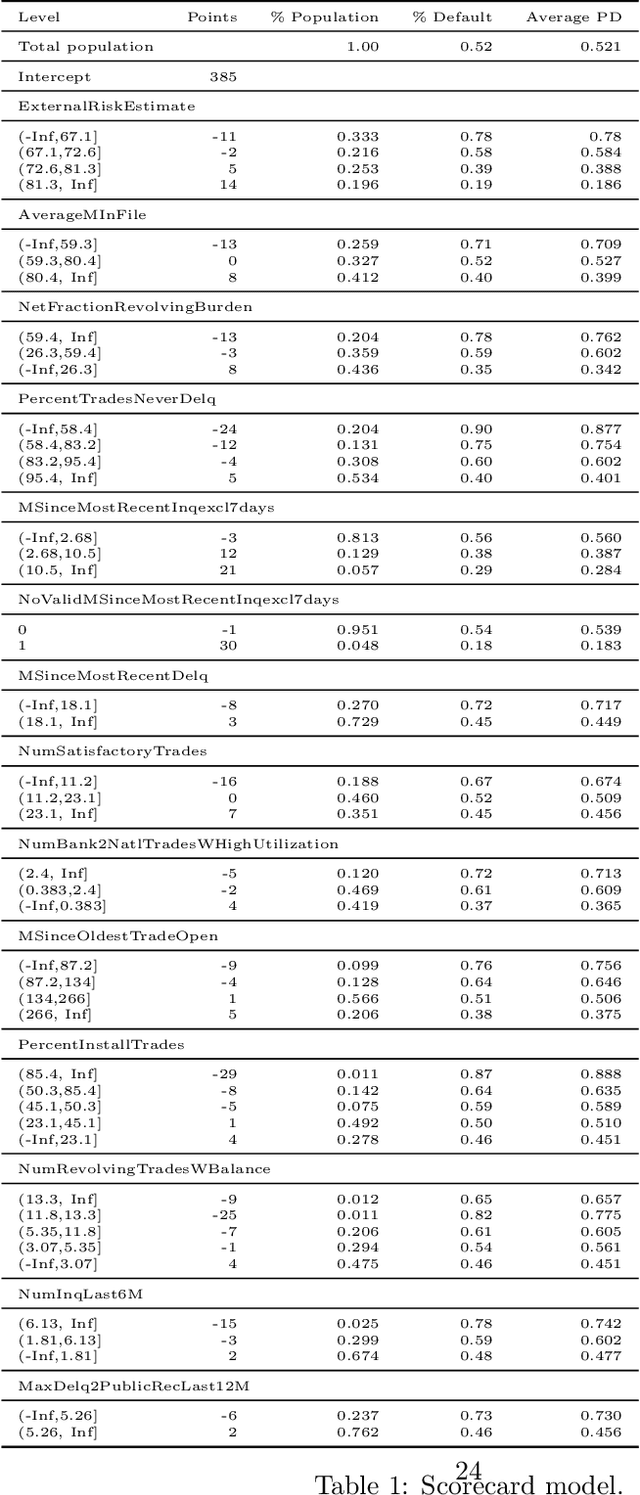
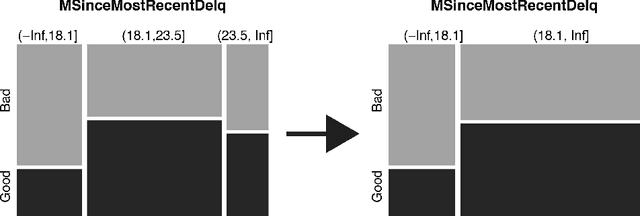
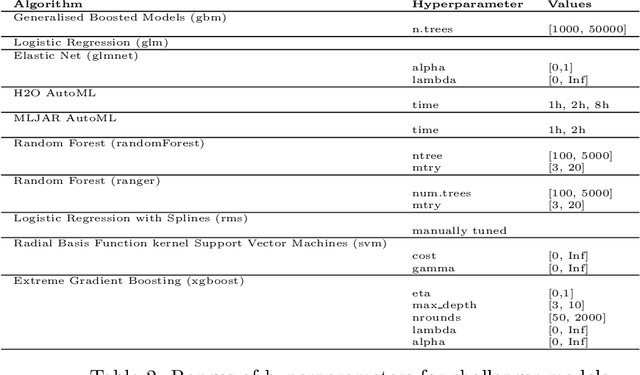
A major requirement for credit scoring models is to provide a maximally accurate risk prediction. Additionally, regulators demand these models to be transparent and auditable. Thus, in credit scoring, very simple predictive models such as logistic regression or decision trees are still widely used and the superior predictive power of modern machine learning algorithms cannot be fully leveraged. Significant potential is therefore missed, leading to higher reserves or more credit defaults. This paper works out different dimensions that have to be considered for making credit scoring models understandable and presents a framework for making ``black box'' machine learning models transparent, auditable and explainable. Following this framework, we present an overview of techniques, demonstrate how they can be applied in credit scoring and how results compare to the interpretability of score cards. A real world case study shows that a comparable degree of interpretability can be achieved while machine learning techniques keep their ability to improve predictive power.
An Overview on the Landscape of R Packages for Credit Scoring
Jul 02, 2020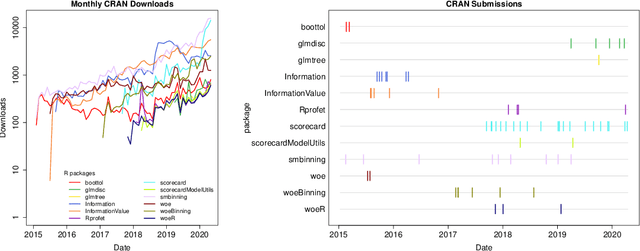

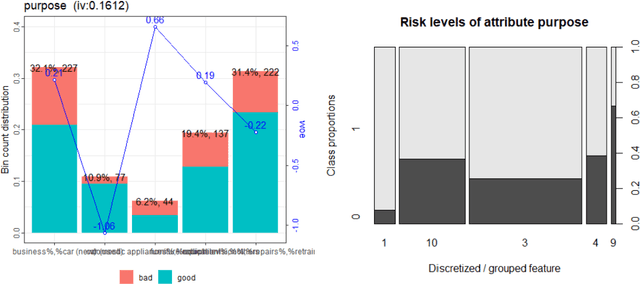

The credit scoring industry has a long tradition of using statistical tools for loan default probability prediction and domain specific standards have been established long before the hype of machine learning. Although several commercial software companies offer specific solutions for credit scorecard modelling in R explicit packages for this purpose have been missing long time. In the recent years this has changed and several packages have been developed which are dedicated to credit scoring. The aim of this paper is to give a structured overview on these packages. This may guide users to select the appropriate functions for a desired purpose and further hopefully will contribute to directing future development activities. The paper is guided by the chain of subsequent modelling steps as they are forming the typical scorecard development process.
How Much Can We See? A Note on Quantifying Explainability of Machine Learning Models
Oct 29, 2019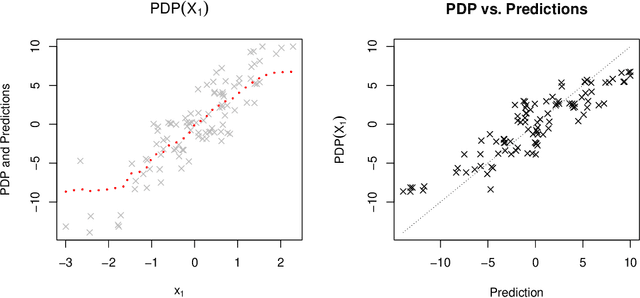
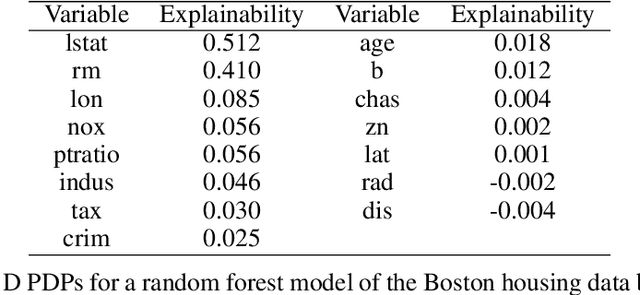
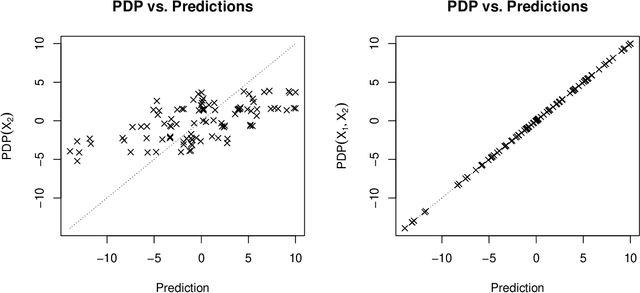
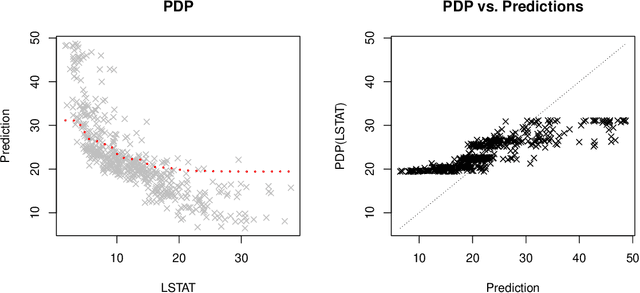
One of the most popular approaches to understanding feature effects of modern black box machine learning models are partial dependence plots (PDP). These plots are easy to understand but only able to visualize low order dependencies. The paper is about the question 'How much can we see?': A framework is developed to quantify the explainability of arbitrary machine learning models, i.e. up to what degree the visualization as given by a PDP is able to explain the predictions of the model. The result allows for a judgement whether an attempt to explain a black box model is sufficient or not.