 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiBreakDown: Uncertainty of Model Explanations for Non-additive Predictive Models
Paper and Code

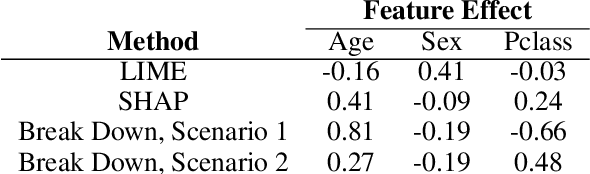
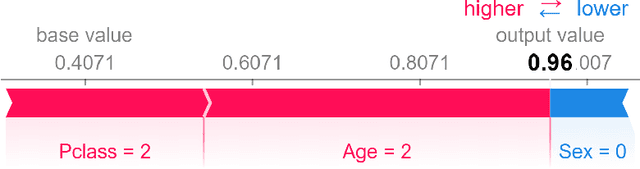
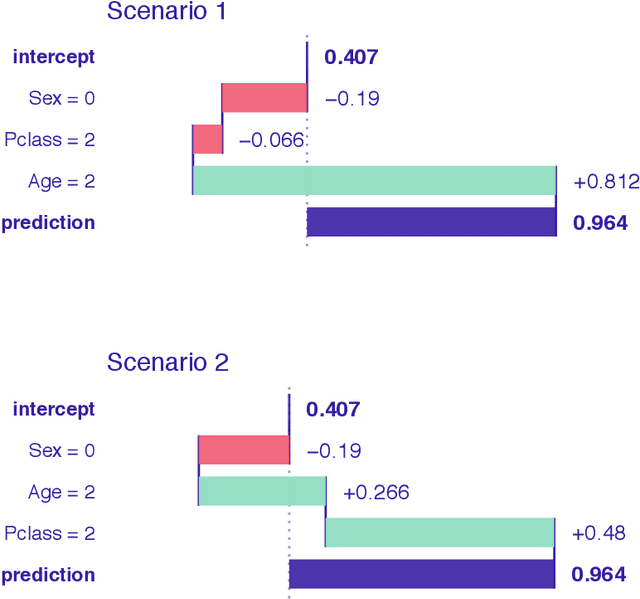
Explainable Artificial Intelligence (XAI) brings a lot of attention recently. Explainability is being presented as a remedy for lack of trust in model predictions. Model agnostic tools such as LIME, SHAP, or Break Down promise instance level interpretability for any complex machine learning model. But how certain are these explanations? Can we rely on additive explanations for non-additive models? In this paper, we examine the behavior of model explainers under the presence of interactions. We define two sources of uncertainty, model level uncertainty, and explanation level uncertainty. We show that adding interactions reduces explanation level uncertainty. We introduce a new method iBreakDown that generates non-additive explanations with local interaction.