Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQUACKIE: A NLP Classification Task With Ground Truth Explanations
Paper and Code

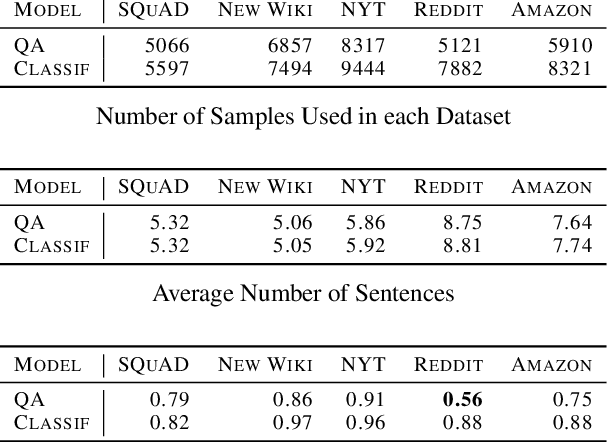
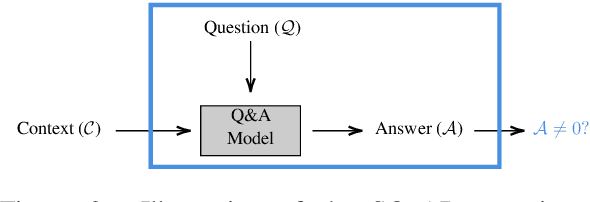

NLP Interpretability aims to increase trust in model predictions. This makes evaluating interpretability approaches a pressing issue. There are multiple datasets for evaluating NLP Interpretability, but their dependence on human provided ground truths raises questions about their unbiasedness. In this work, we take a different approach and formulate a specific classification task by diverting question-answering datasets. For this custom classification task, the interpretability ground-truth arises directly from the definition of the classification problem. We use this method to propose a benchmark and lay the groundwork for future research in NLP interpretability by evaluating a wide range of current state of the art methods.
View paper on