 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImperceptible Adversarial Attacks on Tabular Data
Dec 13, 2019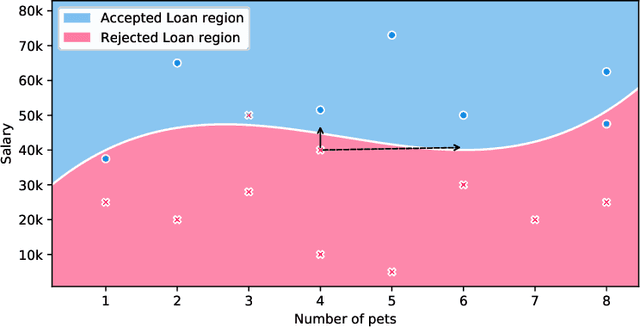
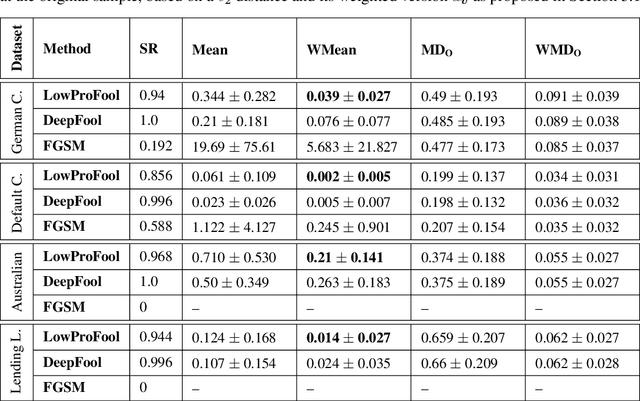
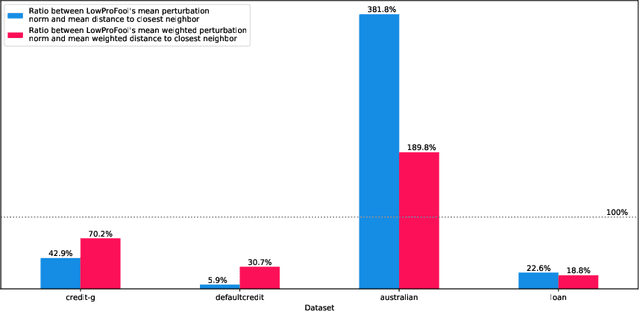
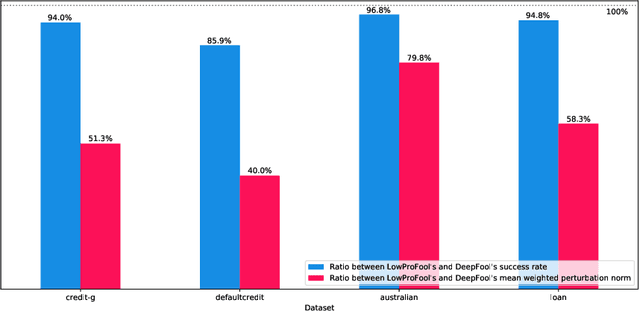
Security of machine learning models is a concern as they may face adversarial attacks for unwarranted advantageous decisions. While research on the topic has mainly been focusing on the image domain, numerous industrial applications, in particular in finance, rely on standard tabular data. In this paper, we discuss the notion of adversarial examples in the tabular domain. We propose a formalization based on the imperceptibility of attacks in the tabular domain leading to an approach to generate imperceptible adversarial examples. Experiments show that we can generate imperceptible adversarial examples with a high fooling rate.
Concept Tree: High-Level Representation of Variables for More Interpretable Surrogate Decision Trees
Jun 04, 2019



Interpretable surrogates of black-box predictors trained on high-dimensional tabular datasets can struggle to generate comprehensible explanations in the presence of correlated variables. We propose a model-agnostic interpretable surrogate that provides global and local explanations of black-box classifiers to address this issue. We introduce the idea of concepts as intuitive groupings of variables that are either defined by a domain expert or automatically discovered using correlation coefficients. Concepts are embedded in a surrogate decision tree to enhance its comprehensibility. First experiments on FRED-MD, a macroeconomic database with 134 variables, show improvement in human-interpretability while accuracy and fidelity of the surrogate model are preserved.
Detecting Adversarial Examples and Other Misclassifications in Neural Networks by Introspection
May 22, 2019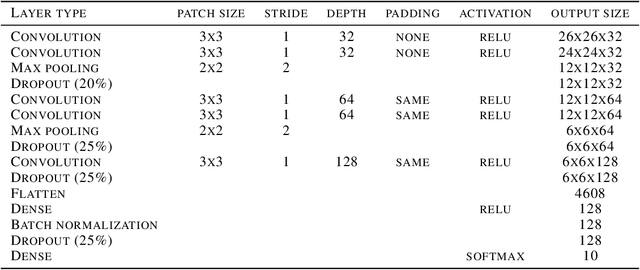
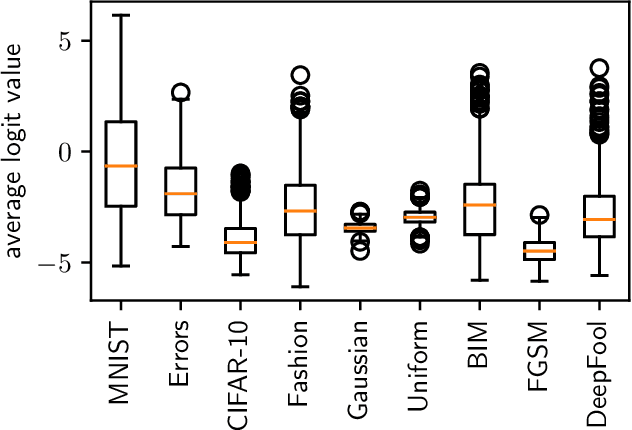
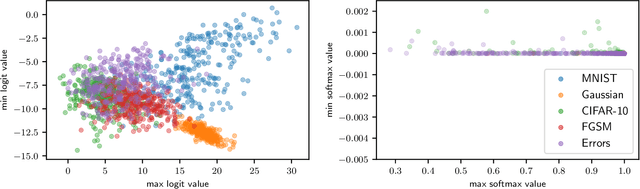
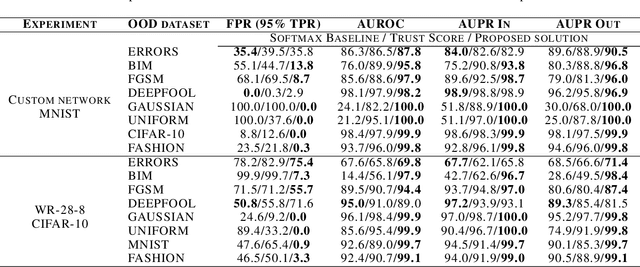
Despite having excellent performances for a wide variety of tasks, modern neural networks are unable to provide a reliable confidence value allowing to detect misclassifications. This limitation is at the heart of what is known as an adversarial example, where the network provides a wrong prediction associated with a strong confidence to a slightly modified image. Moreover, this overconfidence issue has also been observed for regular errors and out-of-distribution data. We tackle this problem by what we call introspection, i.e. using the information provided by the logits of an already pretrained neural network. We show that by training a simple 3-layers neural network on top of the logit activations, we are able to detect misclassifications at a competitive level.