 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlignment Reduces Expressed but Not Encoded Gender Bias: A Unified Framework and Study
Mar 25, 2026During training, Large Language Models (LLMs) learn social regularities that can lead to gender bias in downstream applications. Most mitigation efforts focus on reducing bias in generated outputs, typically evaluated on structured benchmarks, which raises two concerns: output-level evaluation does not reveal whether alignment modifies the model's underlying representations, and structured benchmarks may not reflect realistic usage scenarios. We propose a unified framework to jointly analyze intrinsic and extrinsic gender bias in LLMs using identical neutral prompts, enabling direct comparison between gender-related information encoded in internal representations and bias expressed in generated outputs. Contrary to prior work reporting weak or inconsistent correlations, we find a consistent association between latent gender information and expressed bias when measured under the unified protocol. We further examine the effect of alignment through supervised fine-tuning aimed at reducing gender bias. Our results suggest that while the latter indeed reduces expressed bias, measurable gender-related associations are still present in internal representations, and can be reactivated under adversarial prompting. Finally, we consider two realistic settings and show that debiasing effects observed on structured benchmarks do not necessarily generalize, e.g., to the case of story generation.
A Robust Autoencoder Ensemble-Based Approach for Anomaly Detection in Text
May 16, 2024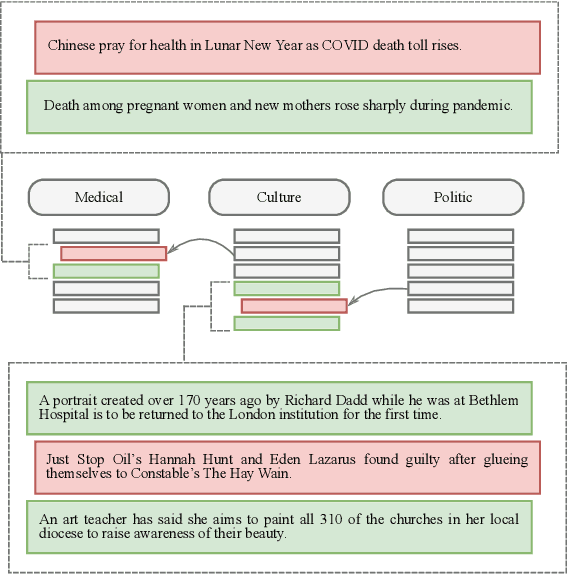
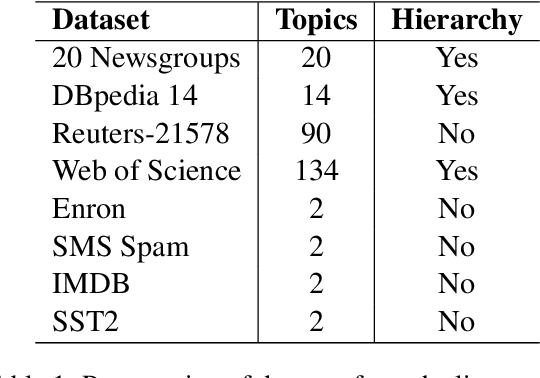
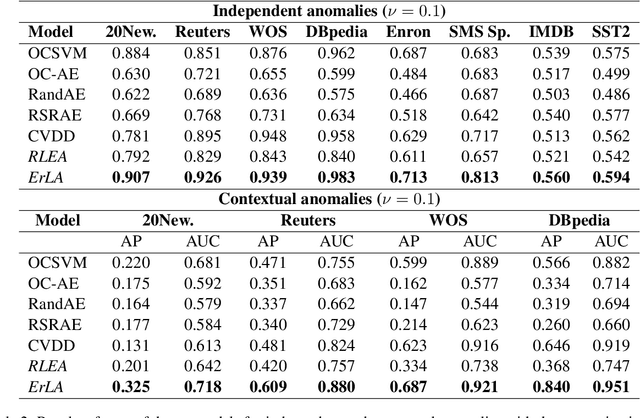
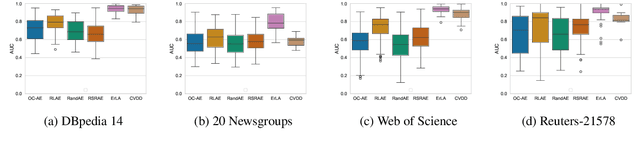
In this work, a robust autoencoder ensemble-based approach designed to address anomaly detection in text corpora is introduced. Each autoencoder within the ensemble incorporates a local robust subspace recovery projection of the original data in its encoding embedding, leveraging the geometric properties of the k-nearest neighbors to optimize subspace recovery and identify anomalous patterns in textual data. The evaluation of such an approach needs an experimental setting dedicated to the context of textual anomaly detection. Thus, beforehand, a comprehensive real-world taxonomy is introduced to distinguish between independent anomalies and contextual anomalies. Such a study to identify clearly the kinds of anomalies appearing in a textual context aims at addressing a critical gap in the existing literature. Then, extensive experiments on classical text corpora have been conducted and their results are presented that highlights the efficiency, both in robustness and in performance, of the robust autoencoder ensemble-based approach when detecting both independent and contextual anomalies. Diverse range of tasks, including classification, sentiment analysis, and spam detection, across eight different corpora, have been studied in these experiments.
Dynamic Interpretability for Model Comparison via Decision Rules
Sep 29, 2023Explainable AI (XAI) methods have mostly been built to investigate and shed light on single machine learning models and are not designed to capture and explain differences between multiple models effectively. This paper addresses the challenge of understanding and explaining differences between machine learning models, which is crucial for model selection, monitoring and lifecycle management in real-world applications. We propose DeltaXplainer, a model-agnostic method for generating rule-based explanations describing the differences between two binary classifiers. To assess the effectiveness of DeltaXplainer, we conduct experiments on synthetic and real-world datasets, covering various model comparison scenarios involving different types of concept drift.
Achieving Diversity in Counterfactual Explanations: a Review and Discussion
May 10, 2023In the field of Explainable Artificial Intelligence (XAI), counterfactual examples explain to a user the predictions of a trained decision model by indicating the modifications to be made to the instance so as to change its associated prediction. These counterfactual examples are generally defined as solutions to an optimization problem whose cost function combines several criteria that quantify desiderata for a good explanation meeting user needs. A large variety of such appropriate properties can be considered, as the user needs are generally unknown and differ from one user to another; their selection and formalization is difficult. To circumvent this issue, several approaches propose to generate, rather than a single one, a set of diverse counterfactual examples to explain a prediction. This paper proposes a review of the numerous, sometimes conflicting, definitions that have been proposed for this notion of diversity. It discusses their underlying principles as well as the hypotheses on the user needs they rely on and proposes to categorize them along several dimensions (explicit vs implicit, universe in which they are defined, level at which they apply), leading to the identification of further research challenges on this topic.
Integrating Prior Knowledge in Post-hoc Explanations
Apr 25, 2022
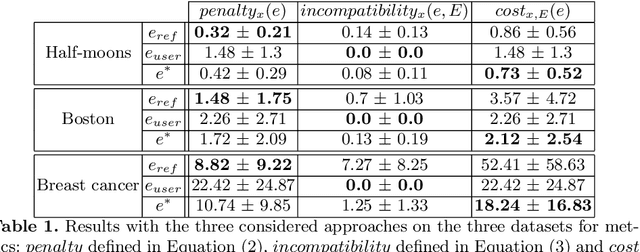
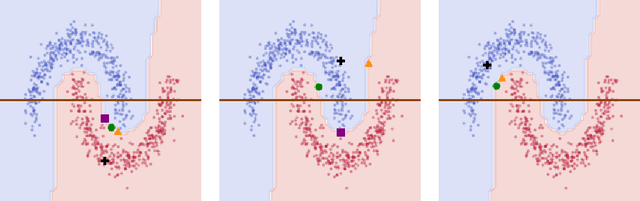
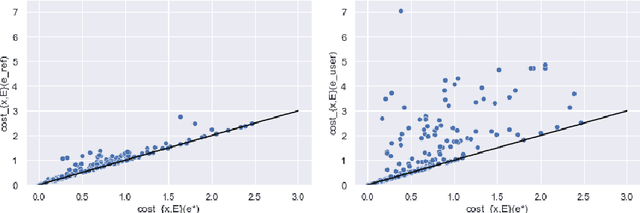
In the field of eXplainable Artificial Intelligence (XAI), post-hoc interpretability methods aim at explaining to a user the predictions of a trained decision model. Integrating prior knowledge into such interpretability methods aims at improving the explanation understandability and allowing for personalised explanations adapted to each user. In this paper, we propose to define a cost function that explicitly integrates prior knowledge into the interpretability objectives: we present a general framework for the optimization problem of post-hoc interpretability methods, and show that user knowledge can thus be integrated to any method by adding a compatibility term in the cost function. We instantiate the proposed formalization in the case of counterfactual explanations and propose a new interpretability method called Knowledge Integration in Counterfactual Explanation (KICE) to optimize it. The paper performs an experimental study on several benchmark data sets to characterize the counterfactual instances generated by KICE, as compared to reference methods.
The Dangers of Post-hoc Interpretability: Unjustified Counterfactual Explanations
Jul 22, 2019



Post-hoc interpretability approaches have been proven to be powerful tools to generate explanations for the predictions made by a trained black-box model. However, they create the risk of having explanations that are a result of some artifacts learned by the model instead of actual knowledge from the data. This paper focuses on the case of counterfactual explanations and asks whether the generated instances can be justified, i.e. continuously connected to some ground-truth data. We evaluate the risk of generating unjustified counterfactual examples by investigating the local neighborhoods of instances whose predictions are to be explained and show that this risk is quite high for several datasets. Furthermore, we show that most state of the art approaches do not differentiate justified from unjustified counterfactual examples, leading to less useful explanations.
Issues with post-hoc counterfactual explanations: a discussion
Jun 11, 2019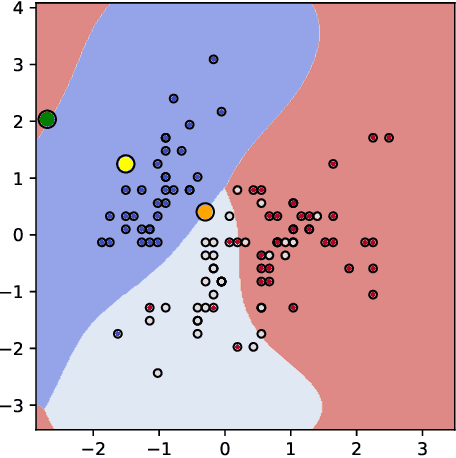
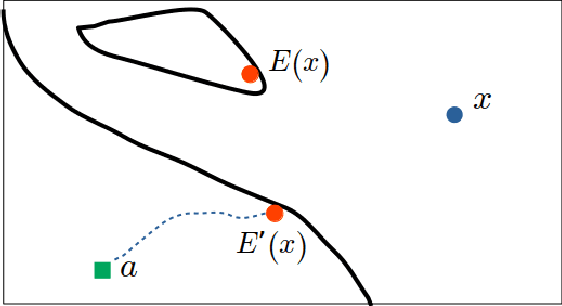
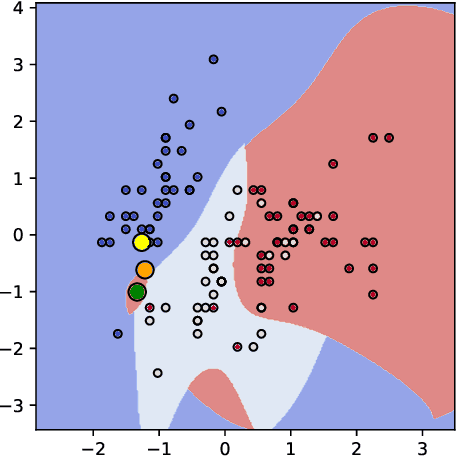
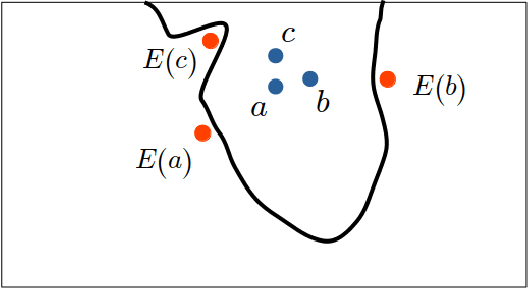
Counterfactual post-hoc interpretability approaches have been proven to be useful tools to generate explanations for the predictions of a trained blackbox classifier. However, the assumptions they make about the data and the classifier make them unreliable in many contexts. In this paper, we discuss three desirable properties and approaches to quantify them: proximity, connectedness and stability. In addition, we illustrate that there is a risk for post-hoc counterfactual approaches to not satisfy these properties.
Detecting Potential Local Adversarial Examples for Human-Interpretable Defense
Sep 07, 2018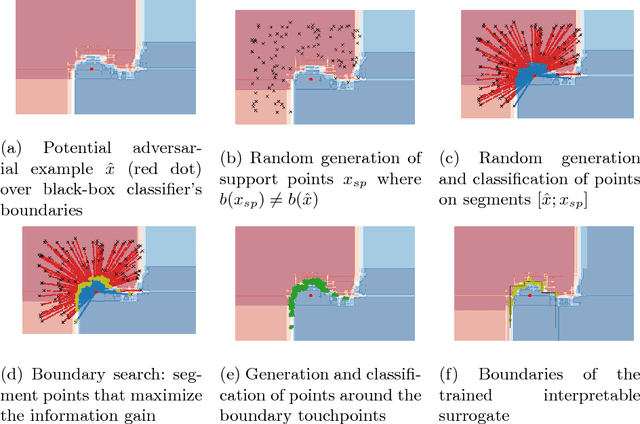
Machine learning models are increasingly used in the industry to make decisions such as credit insurance approval. Some people may be tempted to manipulate specific variables, such as the age or the salary, in order to get better chances of approval. In this ongoing work, we propose to discuss, with a first proposition, the issue of detecting a potential local adversarial example on classical tabular data by providing to a human expert the locally critical features for the classifier's decision, in order to control the provided information and avoid a fraud.
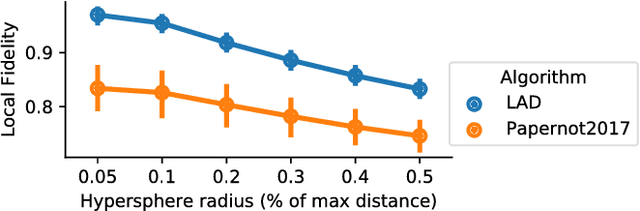
Defining Locality for Surrogates in Post-hoc Interpretablity
Jun 19, 2018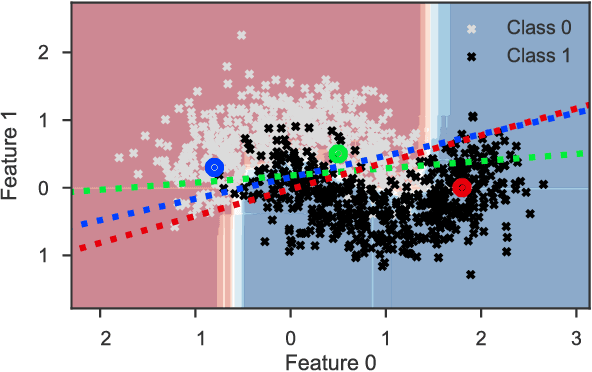
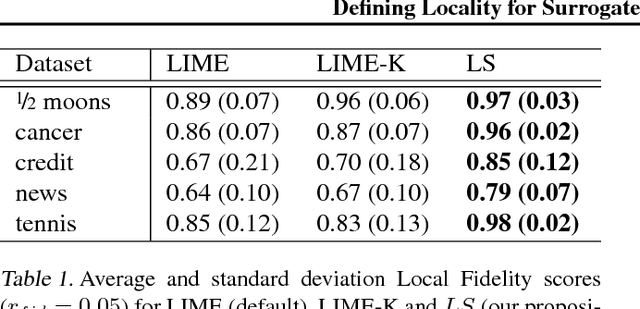
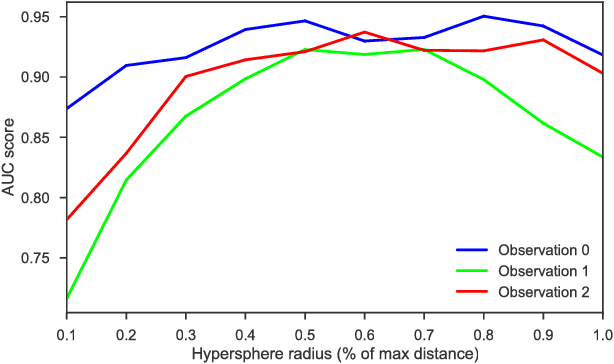
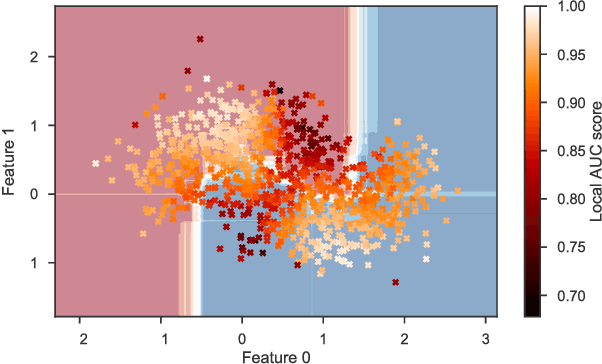
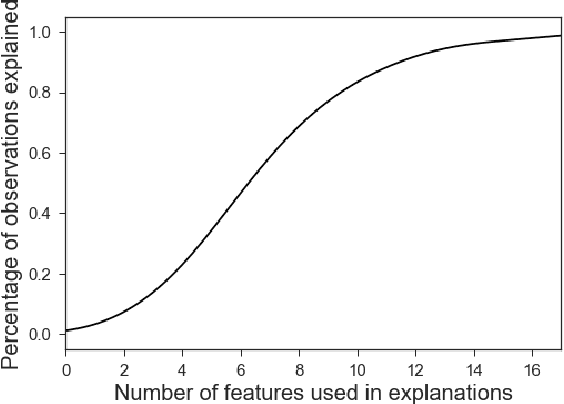
Local surrogate models, to approximate the local decision boundary of a black-box classifier, constitute one approach to generate explanations for the rationale behind an individual prediction made by the back-box. This paper highlights the importance of defining the right locality, the neighborhood on which a local surrogate is trained, in order to approximate accurately the local black-box decision boundary. Unfortunately, as shown in this paper, this issue is not only a parameter or sampling distribution challenge and has a major impact on the relevance and quality of the approximation of the local black-box decision boundary and thus on the meaning and accuracy of the generated explanation. To overcome the identified problems, quantified with an adapted measure and procedure, we propose to generate surrogate-based explanations for individual predictions based on a sampling centered on particular place of the decision boundary, relevant for the prediction to be explained, rather than on the prediction itself as it is classically done. We evaluate the novel approach compared to state-of-the-art methods and a straightforward improvement thereof on four UCI datasets.
Inverse Classification for Comparison-based Interpretability in Machine Learning
Dec 22, 2017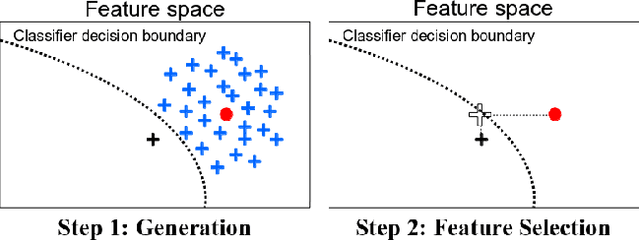


In the context of post-hoc interpretability, this paper addresses the task of explaining the prediction of a classifier, considering the case where no information is available, neither on the classifier itself, nor on the processed data (neither the training nor the test data). It proposes an instance-based approach whose principle consists in determining the minimal changes needed to alter a prediction: given a data point whose classification must be explained, the proposed method consists in identifying a close neighbour classified differently, where the closeness definition integrates a sparsity constraint. This principle is implemented using observation generation in the Growing Spheres algorithm. Experimental results on two datasets illustrate the relevance of the proposed approach that can be used to gain knowledge about the classifier.