 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Robust Autoencoder Ensemble-Based Approach for Anomaly Detection in Text
Paper and Code
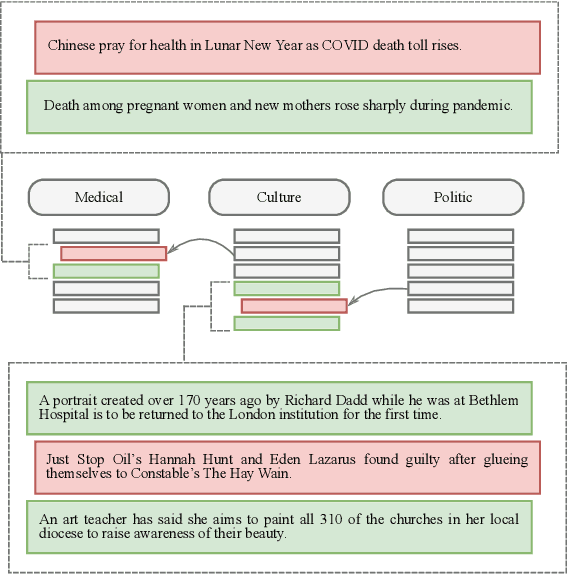
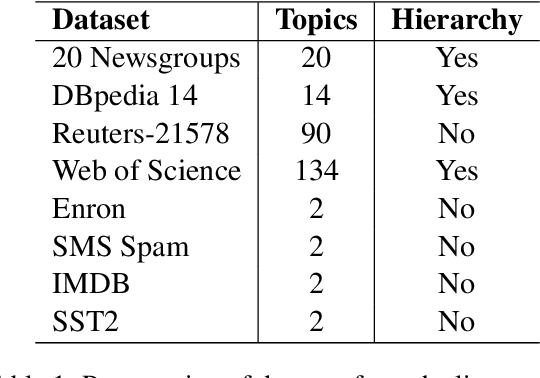
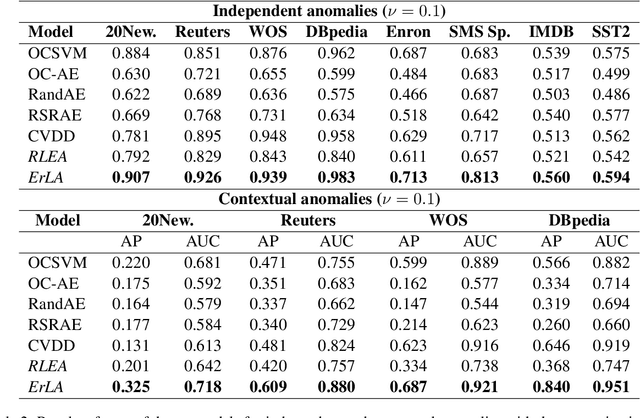
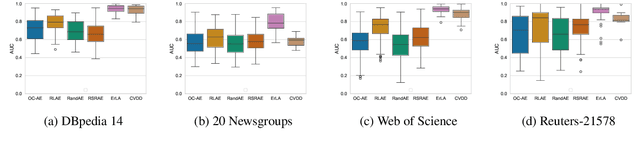
In this work, a robust autoencoder ensemble-based approach designed to address anomaly detection in text corpora is introduced. Each autoencoder within the ensemble incorporates a local robust subspace recovery projection of the original data in its encoding embedding, leveraging the geometric properties of the k-nearest neighbors to optimize subspace recovery and identify anomalous patterns in textual data. The evaluation of such an approach needs an experimental setting dedicated to the context of textual anomaly detection. Thus, beforehand, a comprehensive real-world taxonomy is introduced to distinguish between independent anomalies and contextual anomalies. Such a study to identify clearly the kinds of anomalies appearing in a textual context aims at addressing a critical gap in the existing literature. Then, extensive experiments on classical text corpora have been conducted and their results are presented that highlights the efficiency, both in robustness and in performance, of the robust autoencoder ensemble-based approach when detecting both independent and contextual anomalies. Diverse range of tasks, including classification, sentiment analysis, and spam detection, across eight different corpora, have been studied in these experiments.