Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIssues with post-hoc counterfactual explanations: a discussion
Paper and Code
Jun 11, 2019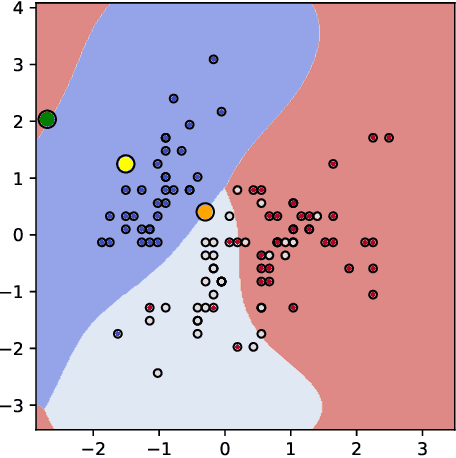
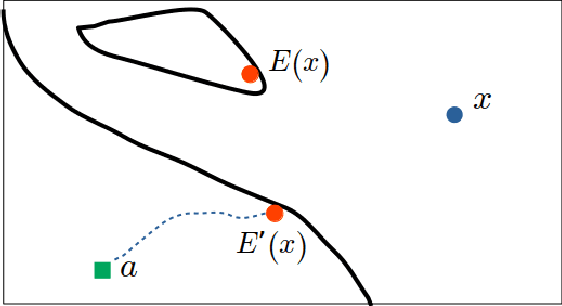
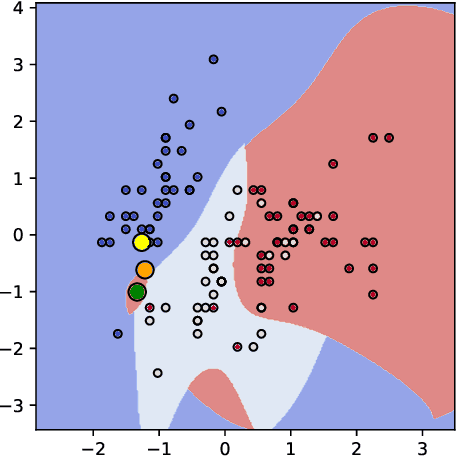
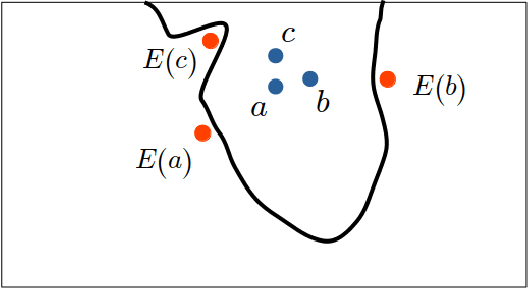
Counterfactual post-hoc interpretability approaches have been proven to be useful tools to generate explanations for the predictions of a trained blackbox classifier. However, the assumptions they make about the data and the classifier make them unreliable in many contexts. In this paper, we discuss three desirable properties and approaches to quantify them: proximity, connectedness and stability. In addition, we illustrate that there is a risk for post-hoc counterfactual approaches to not satisfy these properties.
* presented at 2019 ICML Workshop on Human in the Loop Learning (HILL
2019), Long Beach, USA
View paper on