 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Prediction Discrepancies in Machine Learning Classifiers
Paper and Code


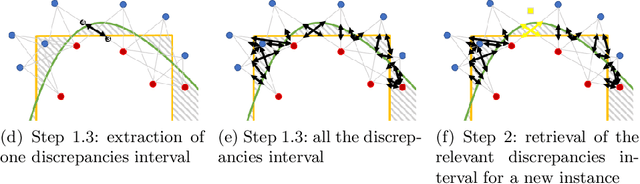

A multitude of classifiers can be trained on the same data to achieve similar performances during test time, while having learned significantly different classification patterns. This phenomenon, which we call prediction discrepancies, is often associated with the blind selection of one model instead of another with similar performances. When making a choice, the machine learning practitioner has no understanding on the differences between models, their limits, where they agree and where they don't. But his/her choice will result in concrete consequences for instances to be classified in the discrepancy zone, since the final decision will be based on the selected classification pattern. Besides the arbitrary nature of the result, a bad choice could have further negative consequences such as loss of opportunity or lack of fairness. This paper proposes to address this question by analyzing the prediction discrepancies in a pool of best-performing models trained on the same data. A model-agnostic algorithm, DIG, is proposed to capture and explain discrepancies locally, to enable the practitioner to make the best educated decision when selecting a model by anticipating its potential undesired consequences. All the code to reproduce the experiments is available.