 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDid I Faithfully Say What I Thought? Bridging the Gap Between Neural Activity and Self-Explanations in Large Language Models
Jun 12, 2025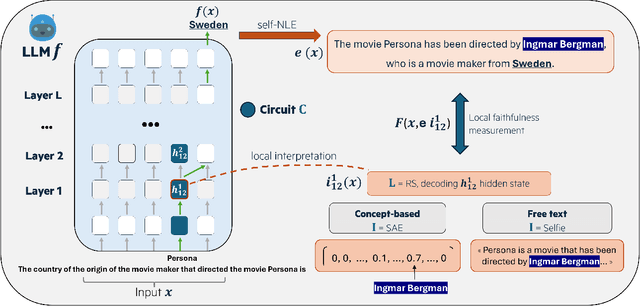
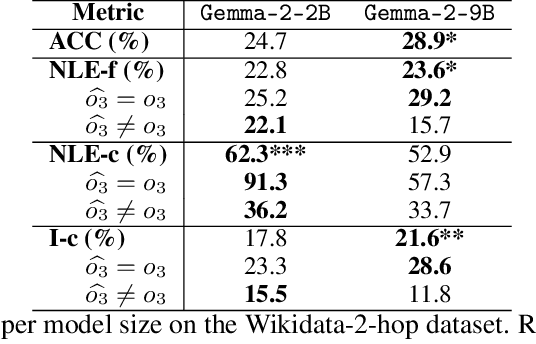
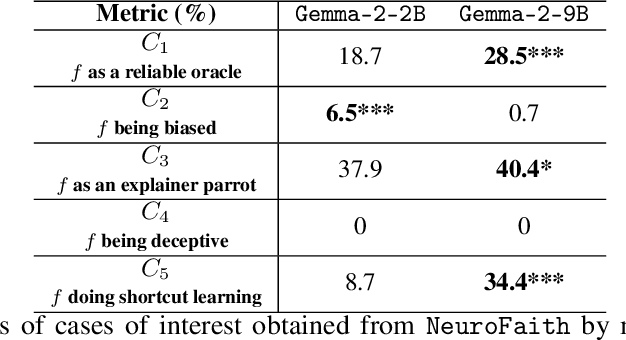

Large Language Models (LLM) have demonstrated the capability of generating free text self Natural Language Explanation (self-NLE) to justify their answers. Despite their logical appearance, self-NLE do not necessarily reflect the LLM actual decision-making process, making such explanations unfaithful. While existing methods for measuring self-NLE faithfulness mostly rely on behavioral tests or computational block identification, none of them examines the neural activity underlying the model's reasoning. This work introduces a novel flexible framework for quantitatively measuring the faithfulness of LLM-generated self-NLE by directly comparing the latter with interpretations of the model's internal hidden states. The proposed framework is versatile and provides deep insights into self-NLE faithfulness by establishing a direct connection between self-NLE and model reasoning. This approach advances the understanding of self-NLE faithfulness and provides building blocks for generating more faithful self-NLE.
Mitigating Text Toxicity with Counterfactual Generation
May 16, 2024



Toxicity mitigation consists in rephrasing text in order to remove offensive or harmful meaning. Neural natural language processing (NLP) models have been widely used to target and mitigate textual toxicity. However, existing methods fail to detoxify text while preserving the initial non-toxic meaning at the same time. In this work, we propose to apply counterfactual generation methods from the eXplainable AI (XAI) field to target and mitigate textual toxicity. In particular, we perform text detoxification by applying local feature importance and counterfactual generation methods to a toxicity classifier distinguishing between toxic and non-toxic texts. We carry out text detoxification through counterfactual generation on three datasets and compare our approach to three competitors. Automatic and human evaluations show that recently developed NLP counterfactual generators can mitigate toxicity accurately while better preserving the meaning of the initial text as compared to classical detoxification methods. Finally, we take a step back from using automated detoxification tools, and discuss how to manage the polysemous nature of toxicity and the risk of malicious use of detoxification tools. This work is the first to bridge the gap between counterfactual generation and text detoxification and paves the way towards more practical application of XAI methods.
Self-AMPLIFY: Improving Small Language Models with Self Post Hoc Explanations
Feb 19, 2024Incorporating natural language rationales in the prompt and In-Context Learning (ICL) has led to a significant improvement of Large Language Models (LLMs) performance. However, rationales currently require human-annotation or the use of auxiliary proxy models to target promising samples or generate high-quality rationales. In this work, we propose Self-AMPLIFY to generate automatically rationales from post hoc explanation methods applied to Small Language Models (SLMs) to improve their own performance. Self-AMPLIFY is a 3-step method that targets samples, generates rationales and builds a final prompt to leverage ICL. Self-AMPLIFY performance is evaluated on two SLMs and two datasets requiring reasoning abilities: these experiments show that Self-AMPLIFY achieves good results against competitors. Self-AMPLIFY is the first method to apply post hoc explanation methods to SLM to generate rationales to improve their own performance in a fully automated manner.
TIGTEC : Token Importance Guided TExt Counterfactuals
Apr 24, 2023
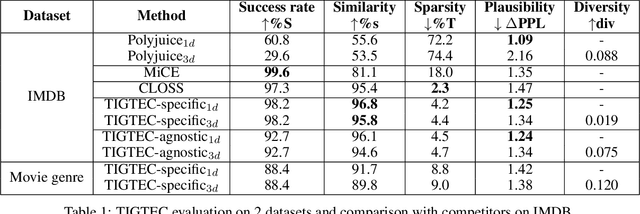
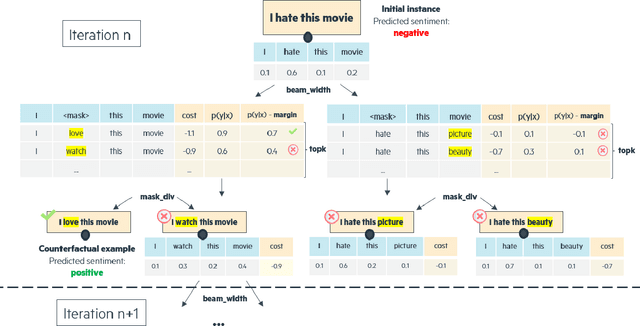
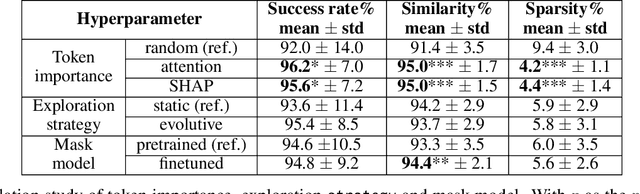
Counterfactual examples explain a prediction by highlighting changes of instance that flip the outcome of a classifier. This paper proposes TIGTEC, an efficient and modular method for generating sparse, plausible and diverse counterfactual explanations for textual data. TIGTEC is a text editing heuristic that targets and modifies words with high contribution using local feature importance. A new attention-based local feature importance is proposed. Counterfactual candidates are generated and assessed with a cost function integrating semantic distance, while the solution space is efficiently explored in a beam search fashion. The conducted experiments show the relevance of TIGTEC in terms of success rate, sparsity, diversity and plausibility. This method can be used in both model-specific or model-agnostic way, which makes it very convenient for generating counterfactual explanations.
Evaluating self-attention interpretability through human-grounded experimental protocol
Mar 27, 2023Attention mechanisms have played a crucial role in the development of complex architectures such as Transformers in natural language processing. However, Transformers remain hard to interpret and are considered as black-boxes. This paper aims to assess how attention coefficients from Transformers can help in providing interpretability. A new attention-based interpretability method called CLaSsification-Attention (CLS-A) is proposed. CLS-A computes an interpretability score for each word based on the attention coefficient distribution related to the part specific to the classification task within the Transformer architecture. A human-grounded experiment is conducted to evaluate and compare CLS-A to other interpretability methods. The experimental protocol relies on the capacity of an interpretability method to provide explanation in line with human reasoning. Experiment design includes measuring reaction times and correct response rates by human subjects. CLS-A performs comparably to usual interpretability methods regarding average participant reaction time and accuracy. The lower computational cost of CLS-A compared to other interpretability methods and its availability by design within the classifier make it particularly interesting. Data analysis also highlights the link between the probability score of a classifier prediction and adequate explanations. Finally, our work confirms the relevancy of the use of CLS-A and shows to which extent self-attention contains rich information to explain Transformer classifiers.