 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking SAM2-based Trackers on FMOX
Dec 10, 2025



Several object tracking pipelines extending Segment Anything Model 2 (SAM2) have been proposed in the past year, where the approach is to follow and segment the object from a single exemplar template provided by the user on a initialization frame. We propose to benchmark these high performing trackers (SAM2, EfficientTAM, DAM4SAM and SAMURAI) on datasets containing fast moving objects (FMO) specifically designed to be challenging for tracking approaches. The goal is to understand better current limitations in state-of-the-art trackers by providing more detailed insights on the behavior of these trackers. We show that overall the trackers DAM4SAM and SAMURAI perform well on more challenging sequences.
Performance of Gaussian Mixture Model Classifiers on Embedded Feature Spaces
Oct 17, 2024



Data embeddings with CLIP and ImageBind provide powerful features for the analysis of multimedia and/or multimodal data. We assess their performance here for classification using a Gaussian Mixture models (GMMs) based layer as an alternative to the standard Softmax layer. GMMs based classifiers have recently been shown to have interesting performances as part of deep learning pipelines trained end-to-end. Our first contribution is to investigate GMM based classification performance taking advantage of the embedded spaces CLIP and ImageBind. Our second contribution is in proposing our own GMM based classifier with a lower parameters count than previously proposed. Our findings are, that in most cases, on these tested embedded spaces, one gaussian component in the GMMs is often enough for capturing each class, and we hypothesize that this may be due to the contrastive loss used for training these embedded spaces that naturally concentrates features together for each class. We also observed that ImageBind often provides better performance than CLIP for classification of image datasets even when these embedded spaces are compressed using PCA.
Combining geolocation and height estimation of objects from street level imagery
May 14, 2023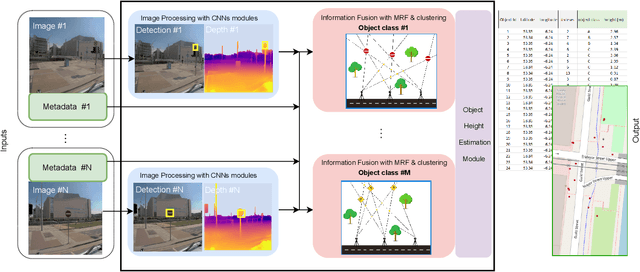
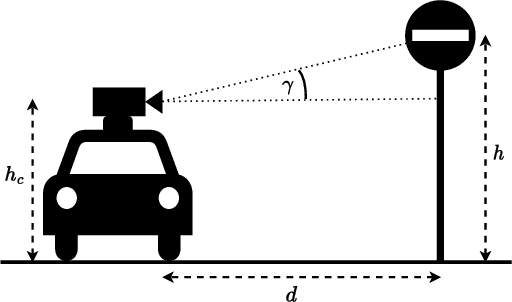
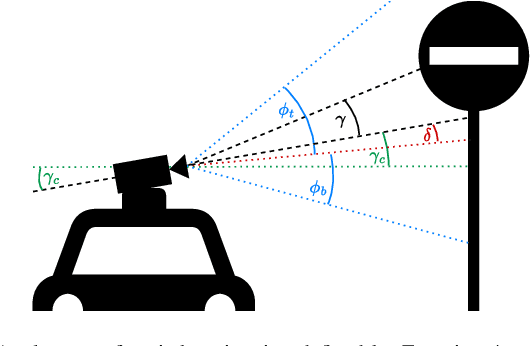
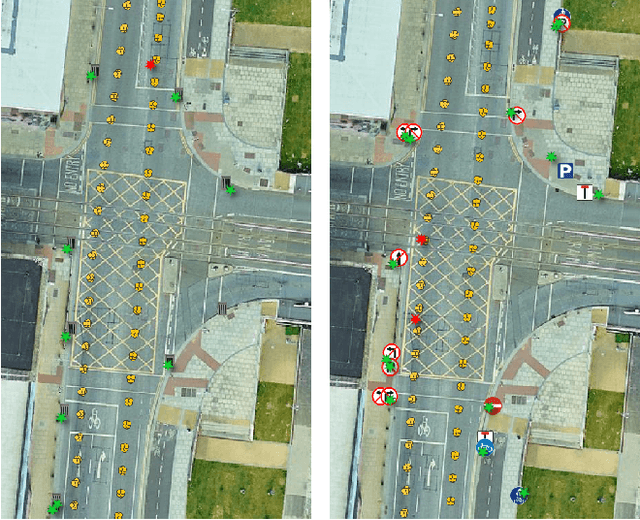
We propose a pipeline for combined multi-class object geolocation and height estimation from street level RGB imagery, which is considered as a single available input data modality. Our solution is formulated via Markov Random Field optimization with deterministic output. The proposed technique uses image metadata along with coordinates of objects detected in the image plane as found by a custom-trained Convolutional Neural Network. Computing the object height using our methodology, in addition to object geolocation, has negligible effect on the overall computational cost. Accuracy is demonstrated experimentally for water drains and road signs on which we achieve average elevation estimation error lower than 20cm.
Model-based inexact graph matching on top of CNNs for semantic scene understanding
Jan 18, 2023



Deep learning based pipelines for semantic segmentation often ignore structural information available on annotated images used for training. We propose a novel post-processing module enforcing structural knowledge about the objects of interest to improve segmentation results provided by deep learning. This module corresponds to a "many-to-one-or-none" inexact graph matching approach, and is formulated as a quadratic assignment problem. Our approach is compared to a CNN-based segmentation (for various CNN backbones) on two public datasets, one for face segmentation from 2D RGB images (FASSEG), and the other for brain segmentation from 3D MRIs (IBSR). Evaluations are performed using two types of structural information (distances and directional relations, , this choice being a hyper-parameter of our generic framework). On FASSEG data, results show that our module improves accuracy of the CNN by about 6.3% (the Hausdorff distance decreases from 22.11 to 20.71). On IBSR data, the improvement is of 51% (the Hausdorff distance decreases from 11.01 to 5.4). In addition, our approach is shown to be resilient to small training datasets that often limit the performance of deep learning methods: the improvement increases as the size of the training dataset decreases.
Principal Component Classification
Oct 26, 2022We propose to directly compute classification estimates by learning features encoded with their class scores using PCA. Our resulting model has a encoder-decoder structure suitable for supervised learning, it is computationally efficient and performs well for classification on several datasets.
DR-VNet: Retinal Vessel Segmentation via Dense Residual UNet
Nov 08, 2021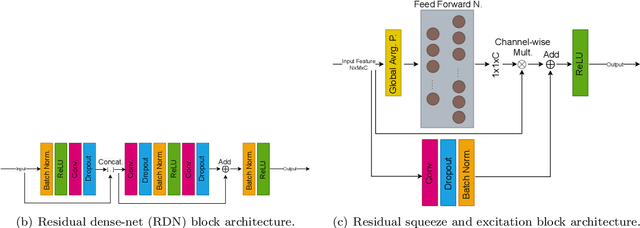

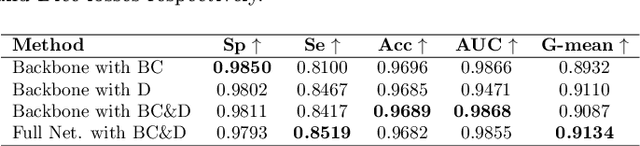
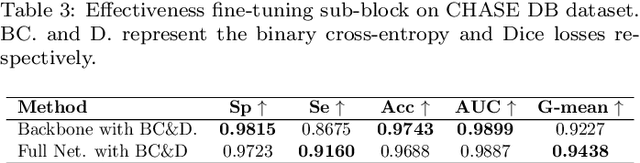
Accurate retinal vessel segmentation is an important task for many computer-aided diagnosis systems. Yet, it is still a challenging problem due to the complex vessel structures of an eye. Numerous vessel segmentation methods have been proposed recently, however more research is needed to deal with poor segmentation of thin and tiny vessels. To address this, we propose a new deep learning pipeline combining the efficiency of residual dense net blocks and, residual squeeze and excitation blocks. We validate experimentally our approach on three datasets and show that our pipeline outperforms current state of the art techniques on the sensitivity metric relevant to assess capture of small vessels.
3D point cloud segmentation using GIS
Aug 13, 2021

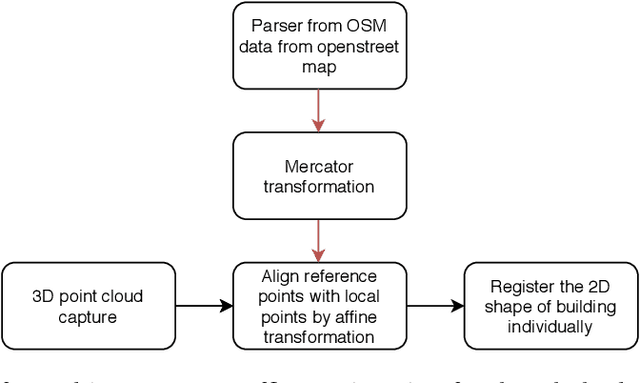
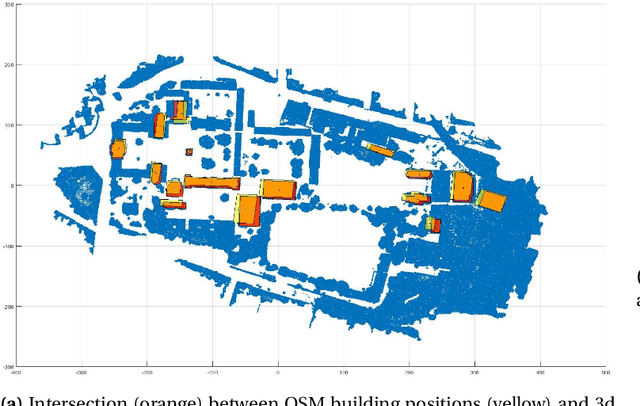
In this paper we propose an approach to perform semantic segmentation of 3D point cloud data by importing the geographic information from a 2D GIS layer (OpenStreetMap). The proposed automatic procedure identifies meaningful units such as buildings and adjusts their locations to achieve best fit between the GIS polygonal perimeters and the point cloud. Our processing pipeline is presented and illustrated by segmenting point cloud data of Trinity College Dublin (Ireland) campus constructed from optical imagery collected by a drone.
* 8 pages
Context Aware Object Geotagging
Aug 13, 2021
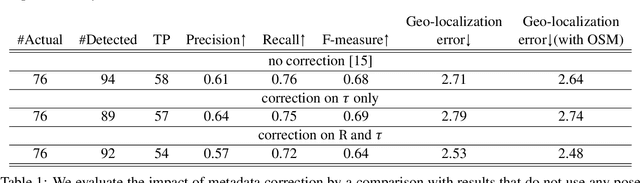
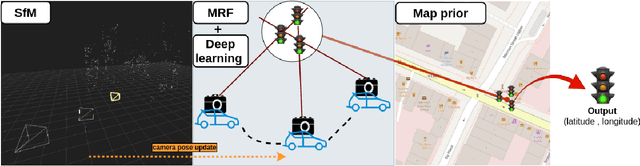

Localization of street objects from images has gained a lot of attention in recent years. We propose an approach to improve asset geolocation from street view imagery by enhancing the quality of the metadata associated with the images using Structure from Motion. The predicted object geolocation is further refined by imposing contextual geographic information extracted from OpenStreetMap. Our pipeline is validated experimentally against the state of the art approaches for geotagging traffic lights.
* 8 pages
Sliced $\mathcal{L}_2$ Distance for Colour Grading
Feb 18, 2021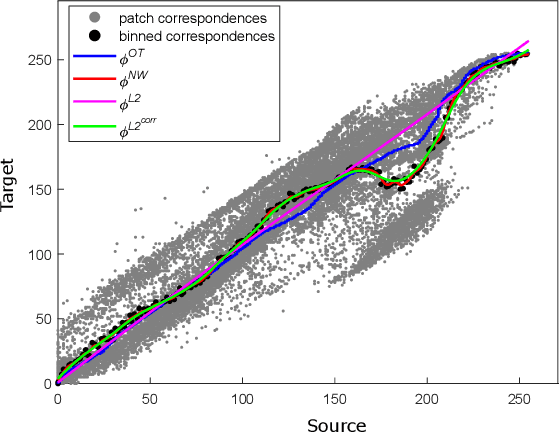
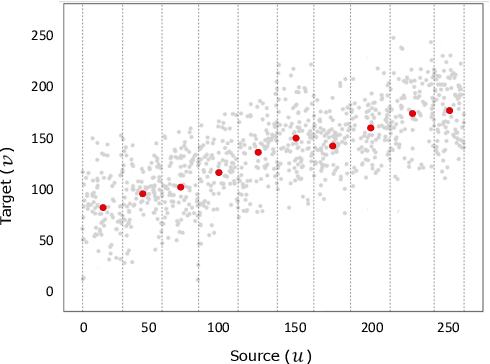
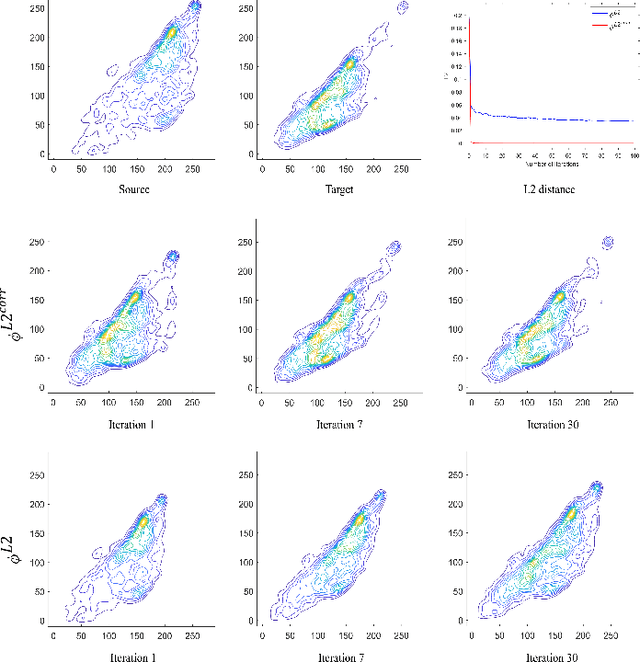
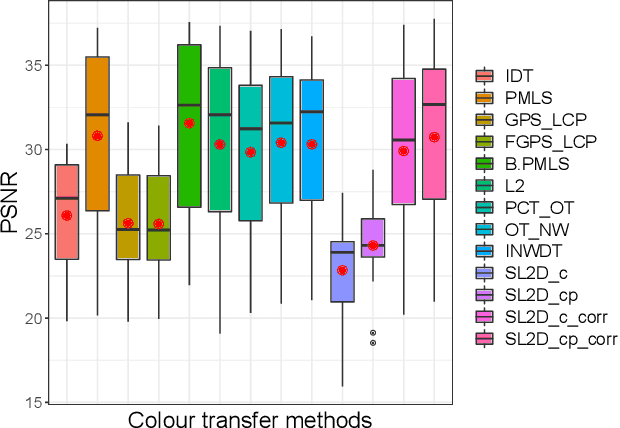
We propose a new method with $\mathcal{L}_2$ distance that maps one $N$-dimensional distribution to another, taking into account available information about correspondences. We solve the high-dimensional problem in 1D space using an iterative projection approach. To show the potentials of this mapping, we apply it to colour transfer between two images that exhibit overlapped scenes. Experiments show quantitative and qualitative competitive results as compared with the state of the art colour transfer methods.
Tensor Reordering for CNN Compression
Oct 22, 2020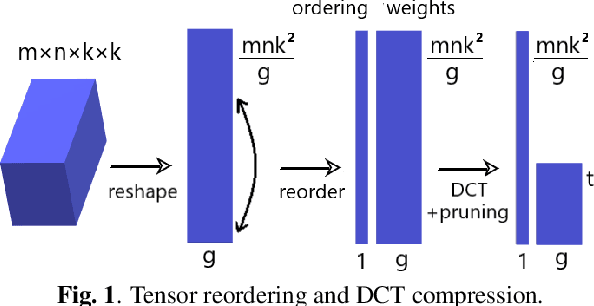

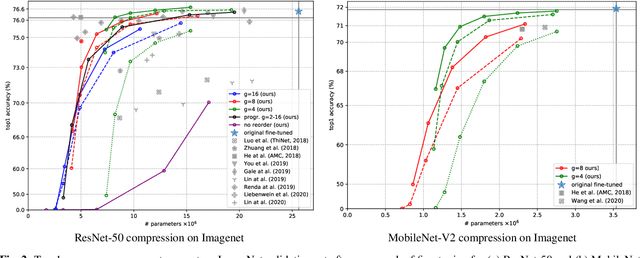
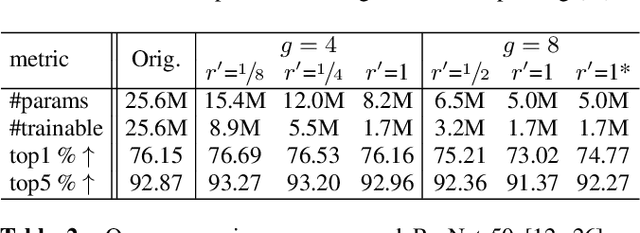
We show how parameter redundancy in Convolutional Neural Network (CNN) filters can be effectively reduced by pruning in spectral domain. Specifically, the representation extracted via Discrete Cosine Transform (DCT) is more conducive for pruning than the original space. By relying on a combination of weight tensor reshaping and reordering we achieve high levels of layer compression with just minor accuracy loss. Our approach is applied to compress pretrained CNNs and we show that minor additional fine-tuning allows our method to recover the original model performance after a significant parameter reduction. We validate our approach on ResNet-50 and MobileNet-V2 architectures for ImageNet classification task.