 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving segmentation of retinal arteries and veins using cardiac signal in doppler holograms
Nov 18, 2025Doppler holography is an emerging retinal imaging technique that captures the dynamic behavior of blood flow with high temporal resolution, enabling quantitative assessment of retinal hemodynamics. This requires accurate segmentation of retinal arteries and veins, but traditional segmentation methods focus solely on spatial information and overlook the temporal richness of holographic data. In this work, we propose a simple yet effective approach for artery-vein segmentation in temporal Doppler holograms using standard segmentation architectures. By incorporating features derived from a dedicated pulse analysis pipeline, our method allows conventional U-Nets to exploit temporal dynamics and achieve performance comparable to more complex attention- or iteration-based models. These findings demonstrate that time-resolved preprocessing can unlock the full potential of deep learning for Doppler holography, opening new perspectives for quantitative exploration of retinal hemodynamics. The dataset is publicly available at https://huggingface.co/datasets/DigitalHolography/
Linear Object Detection in Document Images using Multiple Object Tracking
May 26, 2023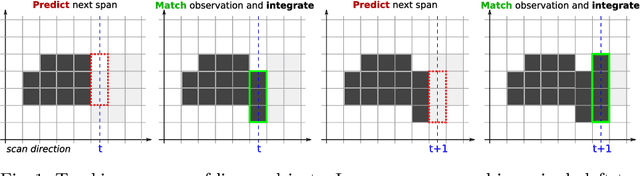
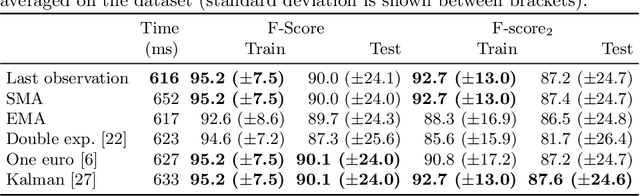

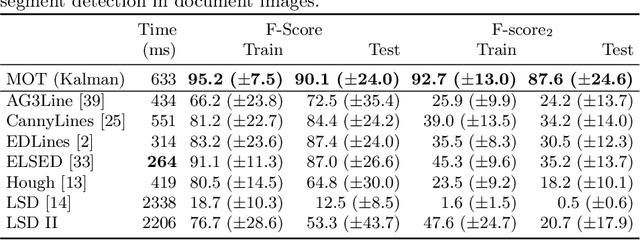
Linear objects convey substantial information about document structure, but are challenging to detect accurately because of degradation (curved, erased) or decoration (doubled, dashed). Many approaches can recover some vector representation, but only one closed-source technique introduced in 1994, based on Kalman filters (a particular case of Multiple Object Tracking algorithm), can perform a pixel-accurate instance segmentation of linear objects and enable to selectively remove them from the original image. We aim at re-popularizing this approach and propose: 1. a framework for accurate instance segmentation of linear objects in document images using Multiple Object Tracking (MOT); 2. document image datasets and metrics which enable both vector- and pixel-based evaluation of linear object detection; 3. performance measures of MOT approaches against modern segment detectors; 4. performance measures of various tracking strategies, exhibiting alternatives to the original Kalman filters approach; and 5. an open-source implementation of a detector which can discriminate instances of curved, erased, dashed, intersecting and/or overlapping linear objects.
A Benchmark of Nested Named Entity Recognition Approaches in Historical Structured Documents
Feb 20, 2023
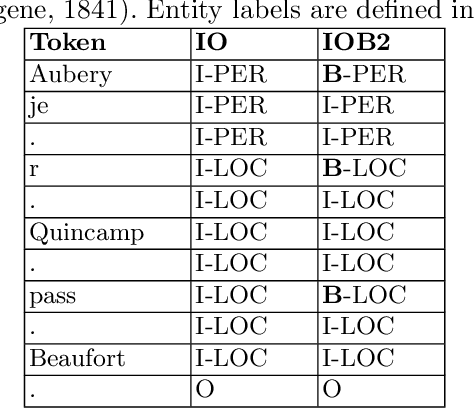

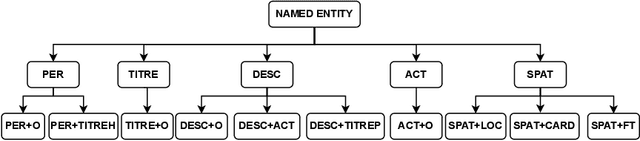
Named Entity Recognition (NER) is a key step in the creation of structured data from digitised historical documents. Traditional NER approaches deal with flat named entities, whereas entities often are nested. For example, a postal address might contain a street name and a number. This work compares three nested NER approaches, including two state-of-the-art approaches using Transformer-based architectures. We introduce a new Transformer-based approach based on joint labelling and semantic weighting of errors, evaluated on a collection of 19 th-century Paris trade directories. We evaluate approaches regarding the impact of supervised fine-tuning, unsupervised pre-training with noisy texts, and variation of IOB tagging formats. Our results show that while nested NER approaches enable extracting structured data directly, they do not benefit from the extra knowledge provided during training and reach a performance similar to the base approach on flat entities. Even though all 3 approaches perform well in terms of F1 scores, joint labelling is most suitable for hierarchically structured data. Finally, our experiments reveal the superiority of the IO tagging format on such data.
Entry Separation using a Mixed Visual and Textual Language Model: Application to 19th century French Trade Directories
Feb 17, 2023When extracting structured data from repetitively organized documents, such as dictionaries, directories, or even newspapers, a key challenge is to correctly segment what constitutes the basic text regions for the target database. Traditionally, such a problem was tackled as part of the layout analysis and was mostly based on visual clues for dividing (top-down) approaches. Some agglomerating (bottom-up) approaches started to consider textual information to link similar contents, but they required a proper over-segmentation of fine-grained units. In this work, we propose a new pragmatic approach whose efficiency is demonstrated on 19th century French Trade Directories. We propose to consider two sub-problems: coarse layout detection (text columns and reading order), which is assumed to be effective and not detailed here, and a fine-grained entry separation stage for which we propose to adapt a state-of-the-art Named Entity Recognition (NER) approach. By injecting special visual tokens, coding, for instance, indentation or breaks, into the token stream of the language model used for NER purpose, we can leverage both textual and visual knowledge simultaneously. Code, data, results and models are available at https://github.com/soduco/paper-entryseg-icdar23-code, https://huggingface.co/HueyNemud/ (icdar23-entrydetector* variants)
A Proof of the Tree of Shapes in n-D
Jun 10, 2022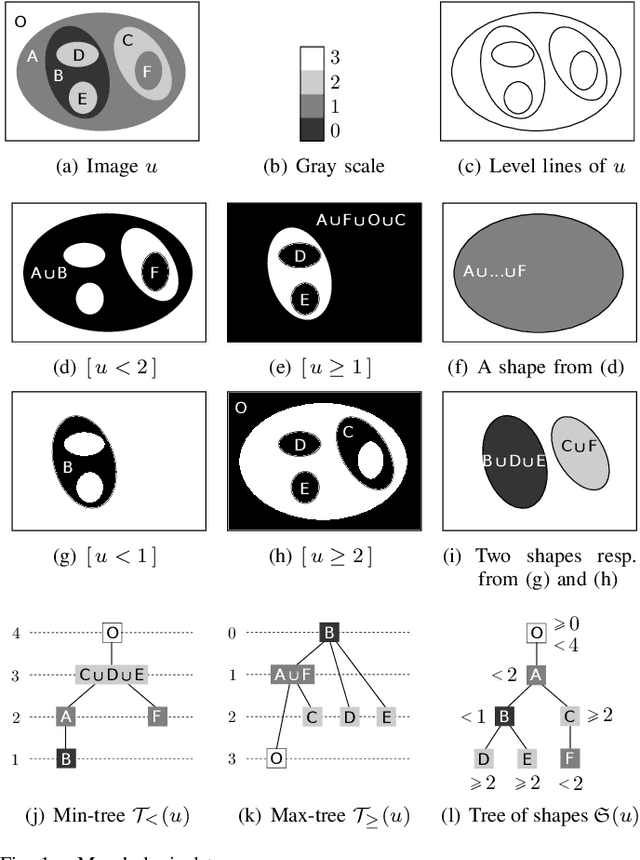
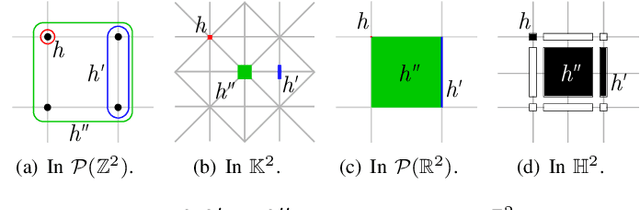
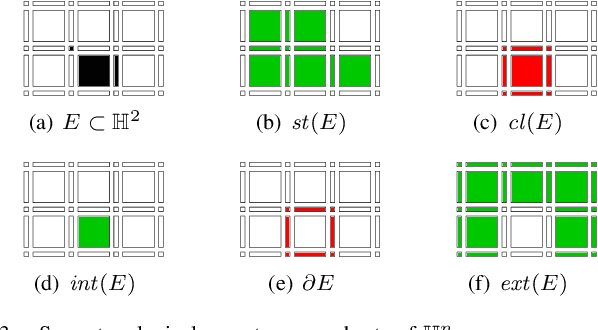
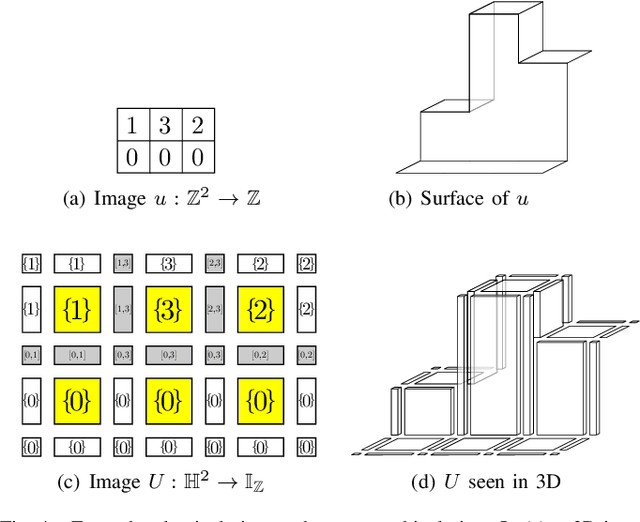
In this paper, we prove that the self-dual morphological hierarchical structure computed on a n-D gray-level wellcomposed image u by the algorithm of G{\'e}raud et al. [1] is exactly the mathematical structure defined to be the tree of shape of u in Najman et al [2]. We recall that this algorithm is in quasi-linear time and thus considered to be optimal. The tree of shapes leads to many applications in mathematical morphology and in image processing like grain filtering, shapings, image segmentation, and so on.
ICDAR 2021 Competition on Historical Map Segmentation
May 27, 2021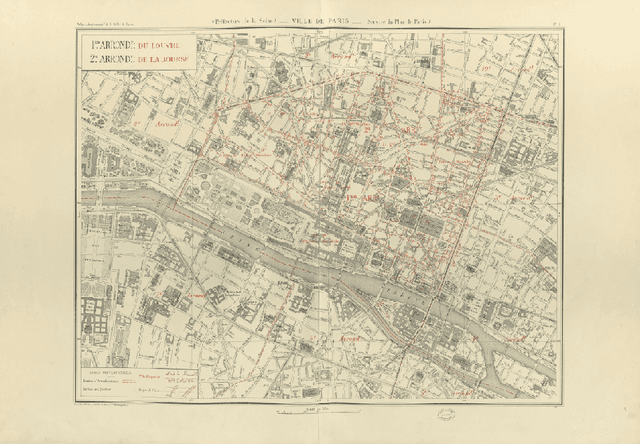
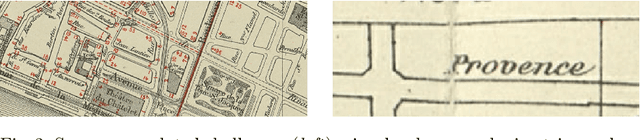
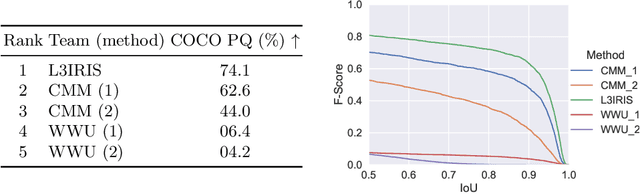
This paper presents the final results of the ICDAR 2021 Competition on Historical Map Segmentation (MapSeg), encouraging research on a series of historical atlases of Paris, France, drawn at 1/5000 scale between 1894 and 1937. The competition featured three tasks, awarded separately. Task~1 consists in detecting building blocks and was won by the L3IRIS team using a DenseNet-121 network trained in a weakly supervised fashion. This task is evaluated on 3 large images containing hundreds of shapes to detect. Task~2 consists in segmenting map content from the larger map sheet, and was won by the UWB team using a U-Net-like FCN combined with a binarization method to increase detection edge accuracy. Task~3 consists in locating intersection points of geo-referencing lines, and was also won by the UWB team who used a dedicated pipeline combining binarization, line detection with Hough transform, candidate filtering, and template matching for intersection refinement. Tasks~2 and~3 are evaluated on 95 map sheets with complex content. Dataset, evaluation tools and results are available under permissive licensing at \url{https://icdar21-mapseg.github.io/}.
Combining Deep Learning and Mathematical Morphology for Historical Map Segmentation
Jan 06, 2021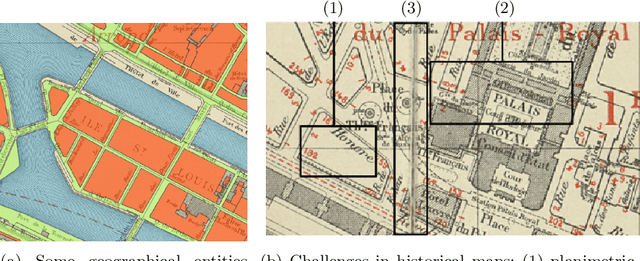
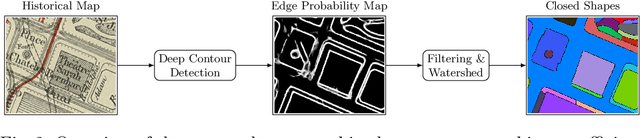


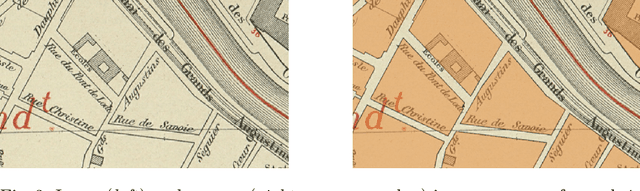
The digitization of historical maps enables the study of ancient, fragile, unique, and hardly accessible information sources. Main map features can be retrieved and tracked through the time for subsequent thematic analysis. The goal of this work is the vectorization step, i.e., the extraction of vector shapes of the objects of interest from raster images of maps. We are particularly interested in closed shape detection such as buildings, building blocks, gardens, rivers, etc. in order to monitor their temporal evolution. Historical map images present significant pattern recognition challenges. The extraction of closed shapes by using traditional Mathematical Morphology (MM) is highly challenging due to the overlapping of multiple map features and texts. Moreover, state-of-the-art Convolutional Neural Networks (CNN) are perfectly designed for content image filtering but provide no guarantee about closed shape detection. Also, the lack of textural and color information of historical maps makes it hard for CNN to detect shapes that are represented by only their boundaries. Our contribution is a pipeline that combines the strengths of CNN (efficient edge detection and filtering) and MM (guaranteed extraction of closed shapes) in order to achieve such a task. The evaluation of our approach on a public dataset shows its effectiveness for extracting the closed boundaries of objects in historical maps.
A fair comparison of many max-tree computation algorithms (Extended version of the paper submitted to ISMM 2013
Jan 10, 2013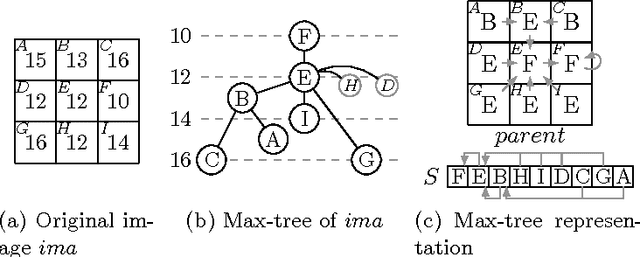



With the development of connected filters for the last decade, many algorithms have been proposed to compute the max-tree. Max-tree allows to compute the most advanced connected operators in a simple way. However, no fair comparison of algorithms has been proposed yet and the choice of an algorithm over an other depends on many parameters. Since the need of fast algorithms is obvious for production code, we present an in depth comparison of five algorithms and some variations of them in a unique framework. Finally, a decision tree will be proposed to help user in choosing the right algorithm with respect to their data.