 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Benchmark of Nested Named Entity Recognition Approaches in Historical Structured Documents
Feb 20, 2023
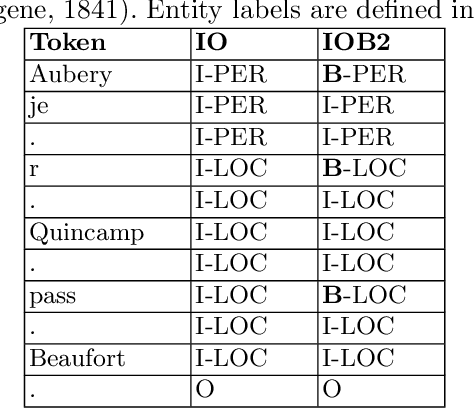

Named Entity Recognition (NER) is a key step in the creation of structured data from digitised historical documents. Traditional NER approaches deal with flat named entities, whereas entities often are nested. For example, a postal address might contain a street name and a number. This work compares three nested NER approaches, including two state-of-the-art approaches using Transformer-based architectures. We introduce a new Transformer-based approach based on joint labelling and semantic weighting of errors, evaluated on a collection of 19 th-century Paris trade directories. We evaluate approaches regarding the impact of supervised fine-tuning, unsupervised pre-training with noisy texts, and variation of IOB tagging formats. Our results show that while nested NER approaches enable extracting structured data directly, they do not benefit from the extra knowledge provided during training and reach a performance similar to the base approach on flat entities. Even though all 3 approaches perform well in terms of F1 scores, joint labelling is most suitable for hierarchically structured data. Finally, our experiments reveal the superiority of the IO tagging format on such data.
Entry Separation using a Mixed Visual and Textual Language Model: Application to 19th century French Trade Directories
Feb 17, 2023When extracting structured data from repetitively organized documents, such as dictionaries, directories, or even newspapers, a key challenge is to correctly segment what constitutes the basic text regions for the target database. Traditionally, such a problem was tackled as part of the layout analysis and was mostly based on visual clues for dividing (top-down) approaches. Some agglomerating (bottom-up) approaches started to consider textual information to link similar contents, but they required a proper over-segmentation of fine-grained units. In this work, we propose a new pragmatic approach whose efficiency is demonstrated on 19th century French Trade Directories. We propose to consider two sub-problems: coarse layout detection (text columns and reading order), which is assumed to be effective and not detailed here, and a fine-grained entry separation stage for which we propose to adapt a state-of-the-art Named Entity Recognition (NER) approach. By injecting special visual tokens, coding, for instance, indentation or breaks, into the token stream of the language model used for NER purpose, we can leverage both textual and visual knowledge simultaneously. Code, data, results and models are available at https://github.com/soduco/paper-entryseg-icdar23-code, https://huggingface.co/HueyNemud/ (icdar23-entrydetector* variants)
GeomRDF: A Geodata Converter with a Fine-Grained Structured Representation of Geometry in the Web
Mar 16, 2015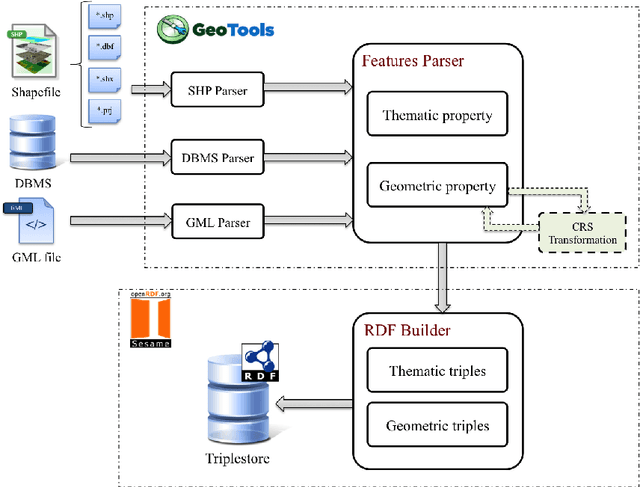

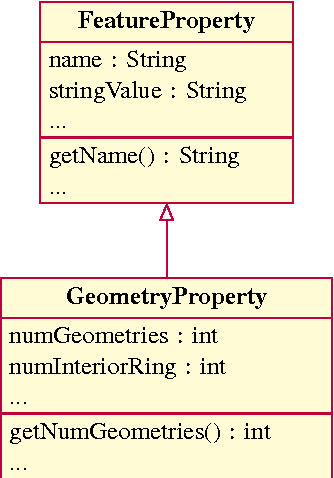
In recent years, with the advent of the web of data, a growing number of national mapping agencies tend to publish their geospatial data as Linked Data. However, differences between traditional GIS data models and Linked Data model can make the publication process more complicated. Besides, it may require, to be done, the setting of several parameters and some expertise in the semantic web technologies. In addition, the use of standards like GeoSPARQL (or ad hoc predicates) is mandatory to perform spatial queries on published geospatial data. In this paper, we present GeomRDF, a tool that helps users to convert spatial data from traditional GIS formats to RDF model easily. It generates geometries represented as GeoSPARQL WKT literal but also as structured geometries that can be exploited by using only the RDF query language, SPARQL. GeomRDF was implemented as a module in the RDF publication platform Datalift. A validation of GeomRDF has been realized against the French administrative units dataset (provided by IGN France).