 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Task Transformer with uncertainty modelling for Face Based Affective Computing
Aug 06, 2022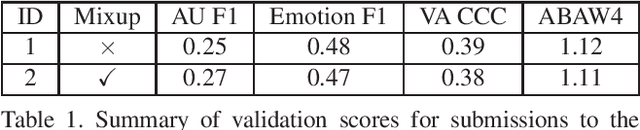
Face based affective computing consists in detecting emotions from face images. It is useful to unlock better automatic comprehension of human behaviours and could pave the way toward improved human-machines interactions. However it comes with the challenging task of designing a computational representation of emotions. So far, emotions have been represented either continuously in the 2D Valence/Arousal space or in a discrete manner with Ekman's 7 basic emotions. Alternatively, Ekman's Facial Action Unit (AU) system have also been used to caracterize emotions using a codebook of unitary muscular activations. ABAW3 and ABAW4 Multi-Task Challenges are the first work to provide a large scale database annotated with those three types of labels. In this paper we present a transformer based multi-task method for jointly learning to predict valence arousal, action units and basic emotions. From an architectural standpoint our method uses a taskwise token approach to efficiently model the similarities between the tasks. From a learning point of view we use an uncertainty weighted loss for modelling the difference of stochasticity between the three tasks annotations.
Privileged Attribution Constrained Deep Networks for Facial Expression Recognition
Mar 24, 2022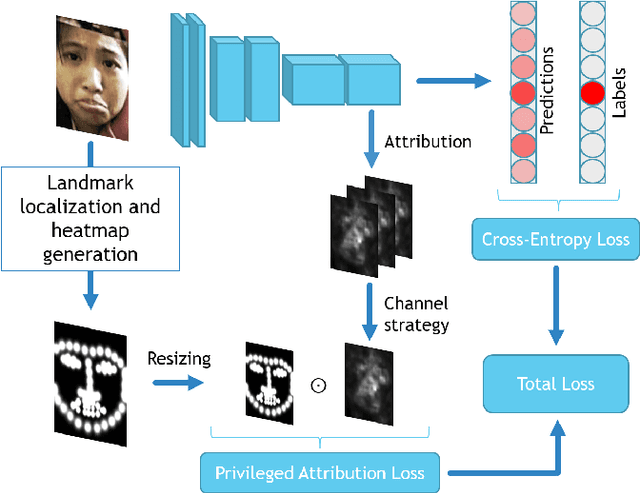

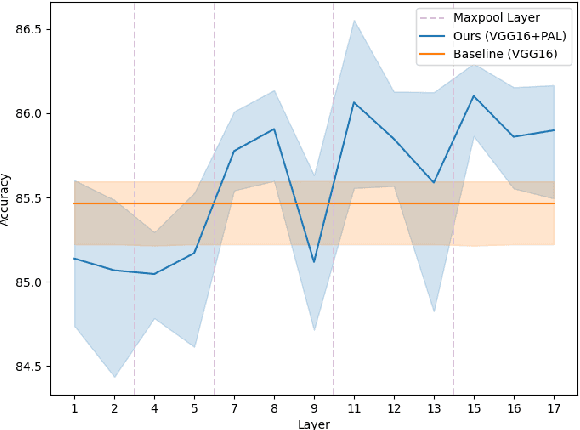
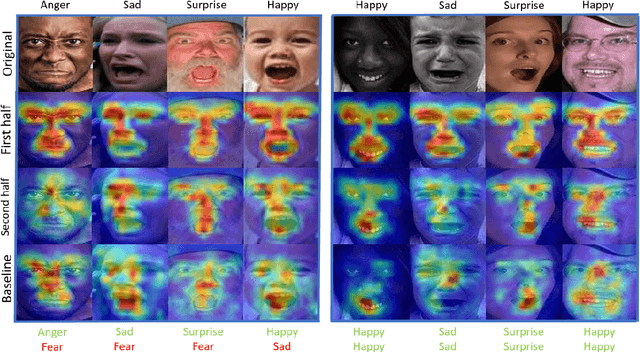
Facial Expression Recognition (FER) is crucial in many research domains because it enables machines to better understand human behaviours. FER methods face the problems of relatively small datasets and noisy data that don't allow classical networks to generalize well. To alleviate these issues, we guide the model to concentrate on specific facial areas like the eyes, the mouth or the eyebrows, which we argue are decisive to recognise facial expressions. We propose the Privileged Attribution Loss (PAL), a method that directs the attention of the model towards the most salient facial regions by encouraging its attribution maps to correspond to a heatmap formed by facial landmarks. Furthermore, we introduce several channel strategies that allow the model to have more degrees of freedom. The proposed method is independent of the backbone architecture and doesn't need additional semantic information at test time. Finally, experimental results show that the proposed PAL method outperforms current state-of-the-art methods on both RAF-DB and AffectNet.
DeeSCo: Deep heterogeneous ensemble with Stochastic Combinatory loss for gaze estimation
Apr 15, 2020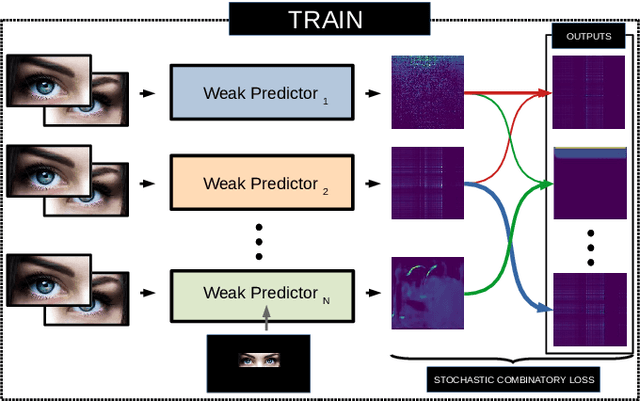
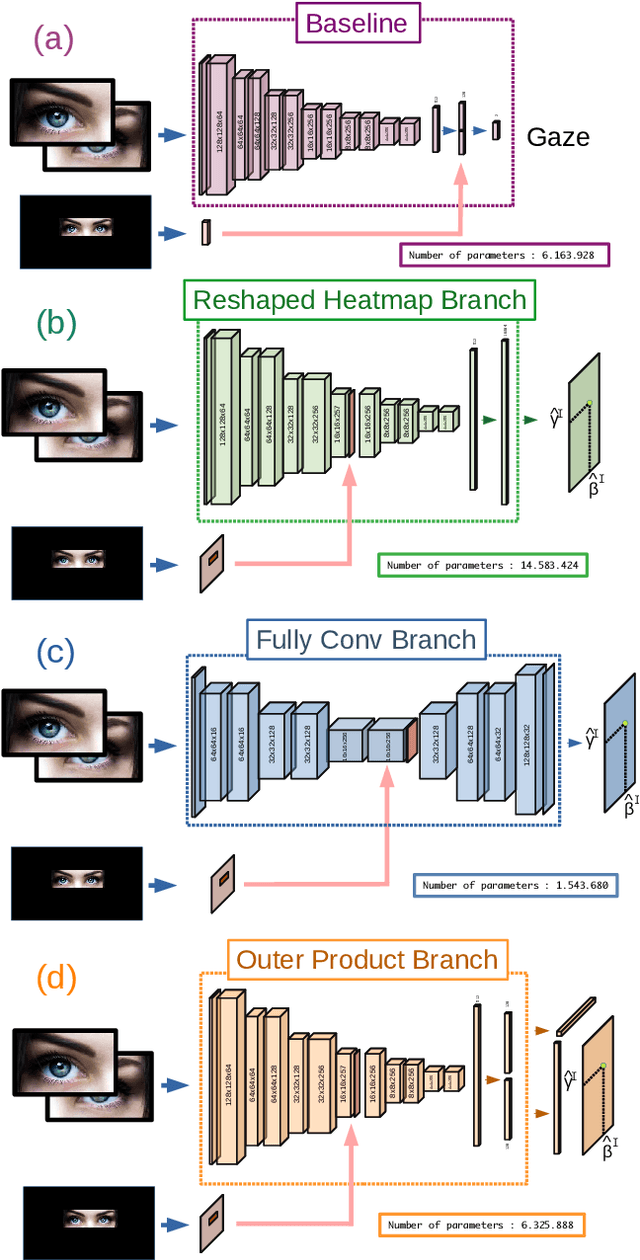
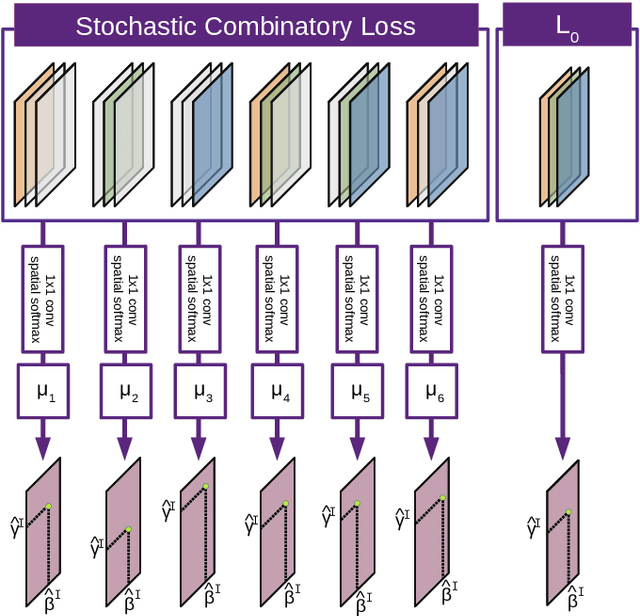
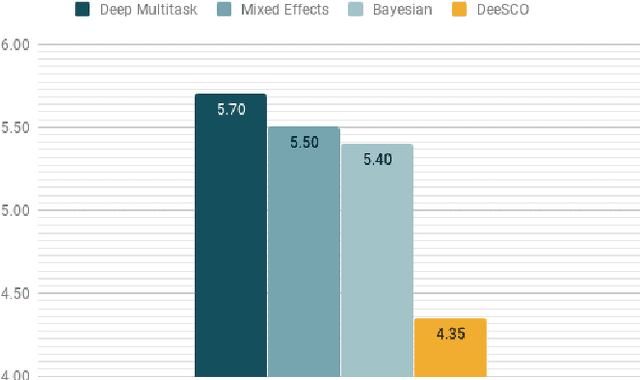
From medical research to gaming applications, gaze estimation is becoming a valuable tool. While there exists a number of hardware-based solutions, recent deep learning-based approaches, coupled with the availability of large-scale databases, have allowed to provide a precise gaze estimate using only consumer sensors. However, there remains a number of questions, regarding the problem formulation, architectural choices and learning paradigms for designing gaze estimation systems in order to bridge the gap between geometry-based systems involving specific hardware and approaches using consumer sensors only. In this paper, we introduce a deep, end-to-end trainable ensemble of heatmap-based weak predictors for 2D/3D gaze estimation. We show that, through heterogeneous architectural design of these weak predictors, we can improve the decorrelation between the latter predictors to design more robust deep ensemble models. Furthermore, we propose a stochastic combinatory loss that consists in randomly sampling combinations of weak predictors at train time. This allows to train better individual weak predictors, with lower correlation between them. This, in turns, allows to significantly enhance the performance of the deep ensemble. We show that our Deep heterogeneous ensemble with Stochastic Combinatory loss (DeeSCo) outperforms state-of-the-art approaches for 2D/3D gaze estimation on multiple datasets.
Deep Entwined Learning Head Pose and Face Alignment Inside an Attentional Cascade with Doubly-Conditional fusion
Apr 14, 2020
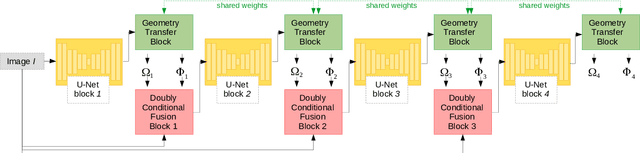

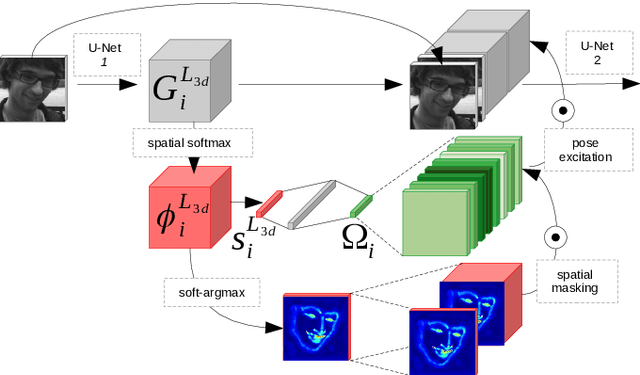
Head pose estimation and face alignment constitute a backbone preprocessing for many applications relying on face analysis. While both are closely related tasks, they are generally addressed separately, e.g. by deducing the head pose from the landmark locations. In this paper, we propose to entwine face alignment and head pose tasks inside an attentional cascade. This cascade uses a geometry transfer network for integrating heterogeneous annotations to enhance landmark localization accuracy. Furthermore, we propose a doubly-conditional fusion scheme to select relevant feature maps, and regions thereof, based on a current head pose and landmark localization estimate. We empirically show the benefit of entwining head pose and landmark localization objectives inside our architecture, and that the proposed AC-DC model enhances the state-of-the-art accuracy on multiple databases for both face alignment and head pose estimation tasks.
DeCaFA: Deep Convolutional Cascade for Face Alignment In The Wild
Apr 04, 2019
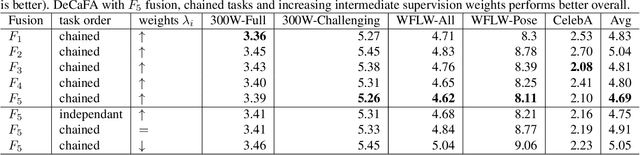
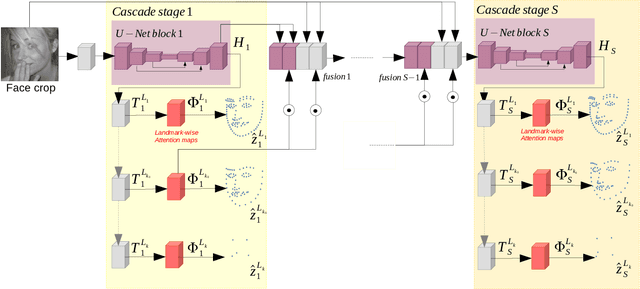
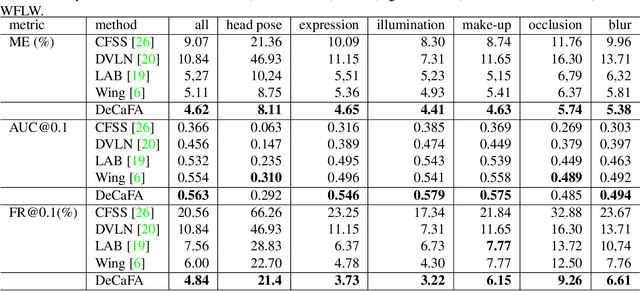
Face Alignment is an active computer vision domain, that consists in localizing a number of facial landmarks that vary across datasets. State-of-the-art face alignment methods either consist in end-to-end regression, or in refining the shape in a cascaded manner, starting from an initial guess. In this paper, we introduce DeCaFA, an end-to-end deep convolutional cascade architecture for face alignment. DeCaFA uses fully-convolutional stages to keep full spatial resolution throughout the cascade. Between each cascade stage, DeCaFA uses multiple chained transfer layers with spatial softmax to produce landmark-wise attention maps for each of several landmark alignment tasks. Weighted intermediate supervision, as well as efficient feature fusion between the stages allow to learn to progressively refine the attention maps in an end-to-end manner. We show experimentally that DeCaFA significantly outperforms existing approaches on 300W, CelebA and WFLW databases. In addition, we show that DeCaFA can learn fine alignment with reasonable accuracy from very few images using coarsely annotated data.
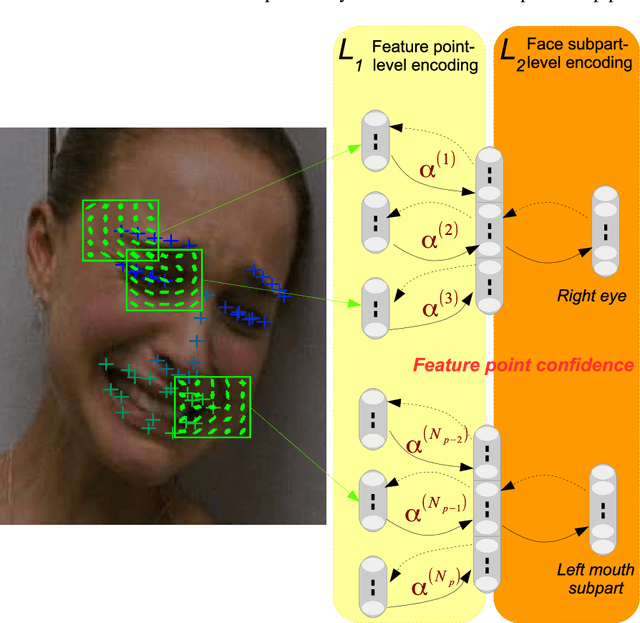
Face Alignment with Cascaded Semi-Parametric Deep Greedy Neural Forests
Mar 05, 2017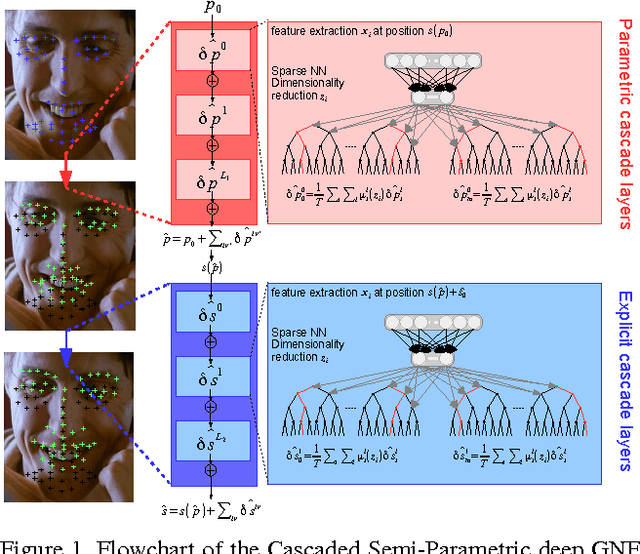
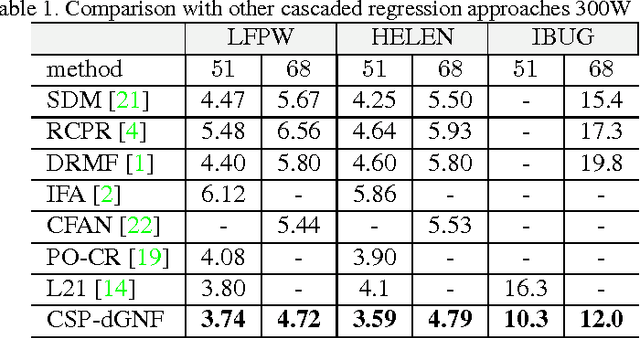
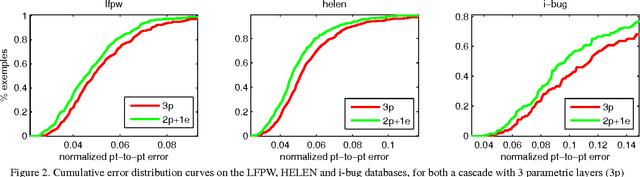
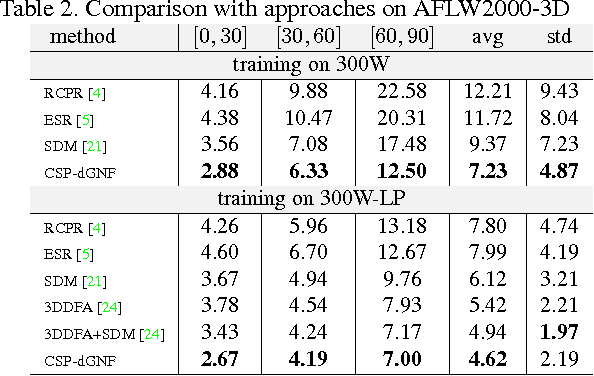
Face alignment is an active topic in computer vision, consisting in aligning a shape model on the face. To this end, most modern approaches refine the shape in a cascaded manner, starting from an initial guess. Those shape updates can either be applied in the feature point space (\textit{i.e.} explicit updates) or in a low-dimensional, parametric space. In this paper, we propose a semi-parametric cascade that first aligns a parametric shape, then captures more fine-grained deformations of an explicit shape. For the purpose of learning shape updates at each cascade stage, we introduce a deep greedy neural forest (GNF) model, which is an improved version of deep neural forest (NF). GNF appears as an ideal regressor for face alignment, as it combines differentiability, high expressivity and fast evaluation runtime. The proposed framework is very fast and achieves high accuracies on multiple challenging benchmarks, including small, medium and large pose experiments.
Confidence-Weighted Local Expression Predictions for Occlusion Handling in Expression Recognition and Action Unit detection
Jul 21, 2016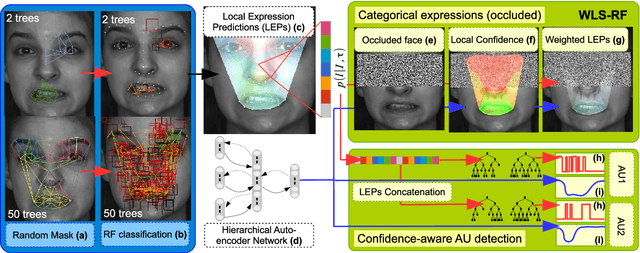
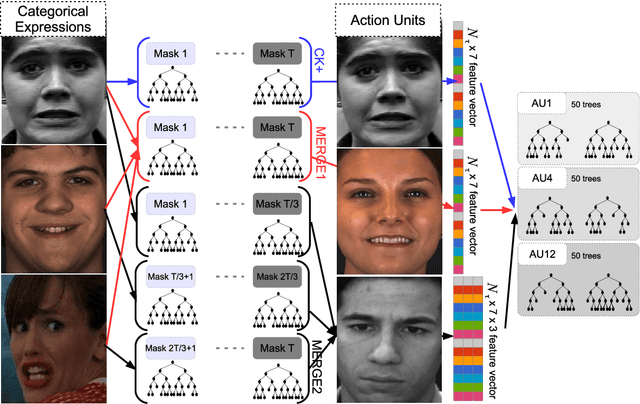

Fully-Automatic Facial Expression Recognition (FER) from still images is a challenging task as it involves handling large interpersonal morphological differences, and as partial occlusions can occasionally happen. Furthermore, labelling expressions is a time-consuming process that is prone to subjectivity, thus the variability may not be fully covered by the training data. In this work, we propose to train Random Forests upon spatially defined local subspaces of the face. The output local predictions form a categorical expression-driven high-level representation that we call Local Expression Predictions (LEPs). LEPs can be combined to describe categorical facial expressions as well as Action Units (AUs). Furthermore, LEPs can be weighted by confidence scores provided by an autoencoder network. Such network is trained to locally capture the manifold of the non-occluded training data in a hierarchical way. Extensive experiments show that the proposed LEP representation yields high descriptive power for categorical expressions and AU occurrence prediction, and leads to interesting perspectives towards the design of occlusion-robust and confidence-aware FER systems.
Dynamic Pose-Robust Facial Expression Recognition by Multi-View Pairwise Conditional Random Forests
Jul 21, 2016
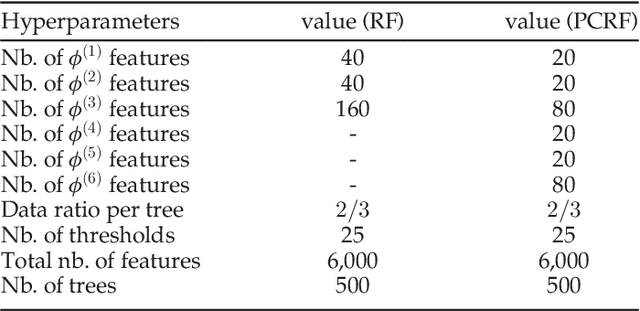
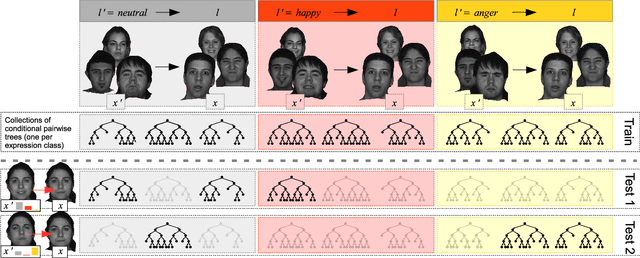
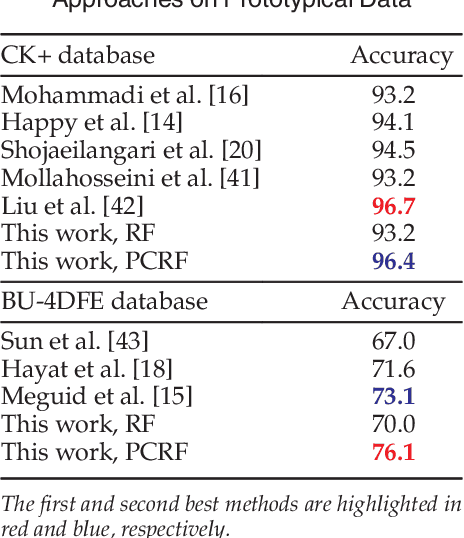
Automatic facial expression classification (FER) from videos is a critical problem for the development of intelligent human-computer interaction systems. Still, it is a challenging problem that involves capturing high-dimensional spatio-temporal patterns describing the variation of one's appearance over time. Such representation undergoes great variability of the facial morphology and environmental factors as well as head pose variations. In this paper, we use Conditional Random Forests to capture low-level expression transition patterns. More specifically, heterogeneous derivative features (e.g. feature point movements or texture variations) are evaluated upon pairs of images. When testing on a video frame, pairs are created between this current frame and previous ones and predictions for each previous frame are used to draw trees from Pairwise Conditional Random Forests (PCRF) whose pairwise outputs are averaged over time to produce robust estimates. Moreover, PCRF collections can also be conditioned on head pose estimation for multi-view dynamic FER. As such, our approach appears as a natural extension of Random Forests for learning spatio-temporal patterns, potentially from multiple viewpoints. Experiments on popular datasets show that our method leads to significant improvements over standard Random Forests as well as state-of-the-art approaches on several scenarios, including a novel multi-view video corpus generated from a publicly available database.