 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFighting over-fitting with quantization for learning deep neural networks on noisy labels
Mar 21, 2023



The rising performance of deep neural networks is often empirically attributed to an increase in the available computational power, which allows complex models to be trained upon large amounts of annotated data. However, increased model complexity leads to costly deployment of modern neural networks, while gathering such amounts of data requires huge costs to avoid label noise. In this work, we study the ability of compression methods to tackle both of these problems at once. We hypothesize that quantization-aware training, by restricting the expressivity of neural networks, behaves as a regularization. Thus, it may help fighting overfitting on noisy data while also allowing for the compression of the model at inference. We first validate this claim on a controlled test with manually introduced label noise. Furthermore, we also test the proposed method on Facial Action Unit detection, where labels are typically noisy due to the subtlety of the task. In all cases, our results suggests that quantization significantly improve the results compared with existing baselines, regularization as well as other compression methods.
Fighting noise and imbalance in Action Unit detection problems
Mar 06, 2023



Action Unit (AU) detection aims at automatically caracterizing facial expressions with the muscular activations they involve. Its main interest is to provide a low-level face representation that can be used to assist higher level affective computing tasks learning. Yet, it is a challenging task. Indeed, the available databases display limited face variability and are imbalanced toward neutral expressions. Furthermore, as AU involve subtle face movements they are difficult to annotate so that some of the few provided datapoints may be mislabeled. In this work, we aim at exploiting label smoothing ability to mitigate noisy examples impact by reducing confidence [1]. However, applying label smoothing as it is may aggravate imbalance-based pre-existing under-confidence issue and degrade performance. To circumvent this issue, we propose Robin Hood Label Smoothing (RHLS). RHLS principle is to restrain label smoothing confidence reduction to the majority class. In that extent, it alleviates both the imbalance-based over-confidence issue and the negative impact of noisy majority class examples. From an experimental standpoint, we show that RHLS provides a free performance improvement in AU detection. In particular, by applying it on top of a modern multi-task baseline we get promising results on BP4D and outperform state-of-the-art methods on DISFA.
Multi-Task Transformer with uncertainty modelling for Face Based Affective Computing
Aug 06, 2022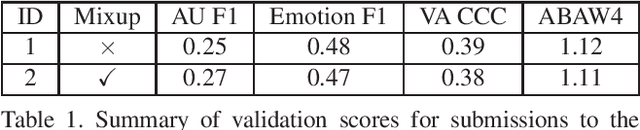
Face based affective computing consists in detecting emotions from face images. It is useful to unlock better automatic comprehension of human behaviours and could pave the way toward improved human-machines interactions. However it comes with the challenging task of designing a computational representation of emotions. So far, emotions have been represented either continuously in the 2D Valence/Arousal space or in a discrete manner with Ekman's 7 basic emotions. Alternatively, Ekman's Facial Action Unit (AU) system have also been used to caracterize emotions using a codebook of unitary muscular activations. ABAW3 and ABAW4 Multi-Task Challenges are the first work to provide a large scale database annotated with those three types of labels. In this paper we present a transformer based multi-task method for jointly learning to predict valence arousal, action units and basic emotions. From an architectural standpoint our method uses a taskwise token approach to efficiently model the similarities between the tasks. From a learning point of view we use an uncertainty weighted loss for modelling the difference of stochasticity between the three tasks annotations.
Multi-label Transformer for Action Unit Detection
Mar 28, 2022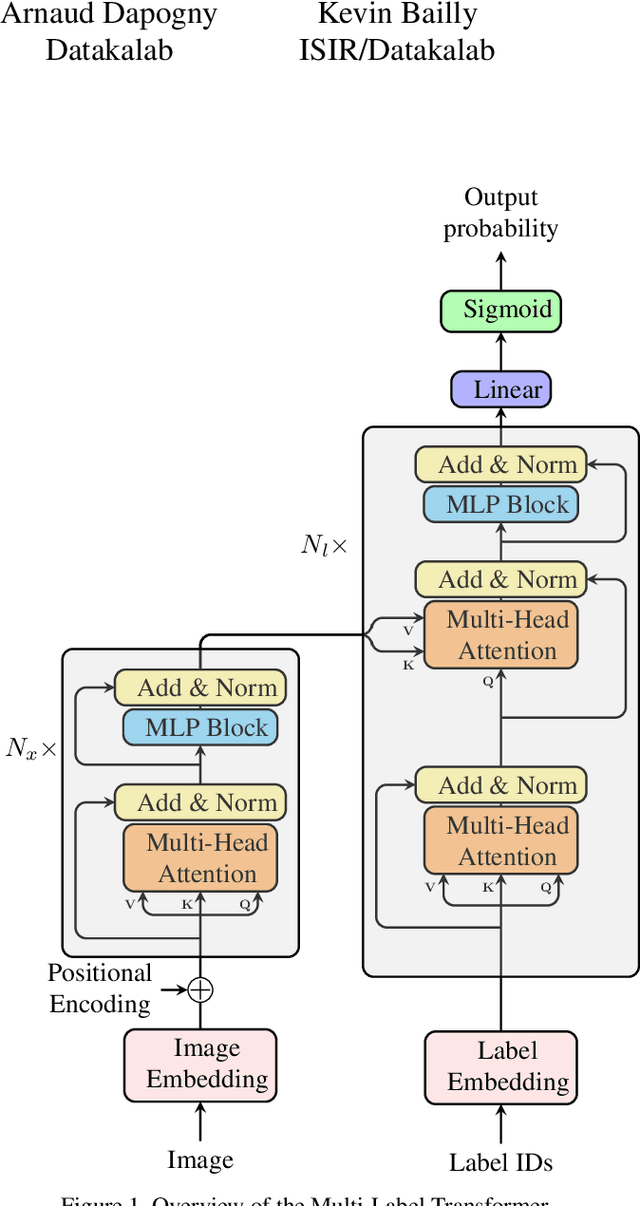

Action Unit (AU) Detection is the branch of affective computing that aims at recognizing unitary facial muscular movements. It is key to unlock unbiased computational face representations and has therefore aroused great interest in the past few years. One of the main obstacles toward building efficient deep learning based AU detection system is the lack of wide facial image databases annotated by AU experts. In that extent the ABAW challenge paves the way toward better AU detection as it involves a 2M frames AU annotated dataset. In this paper, we present our submission to the ABAW3 challenge. In a nutshell, we applied a multi-label detection transformer that leverage multi-head attention to learn which part of the face image is the most relevant to predict each AU.
Multi-Order Networks for Action Unit Detection
Feb 01, 2022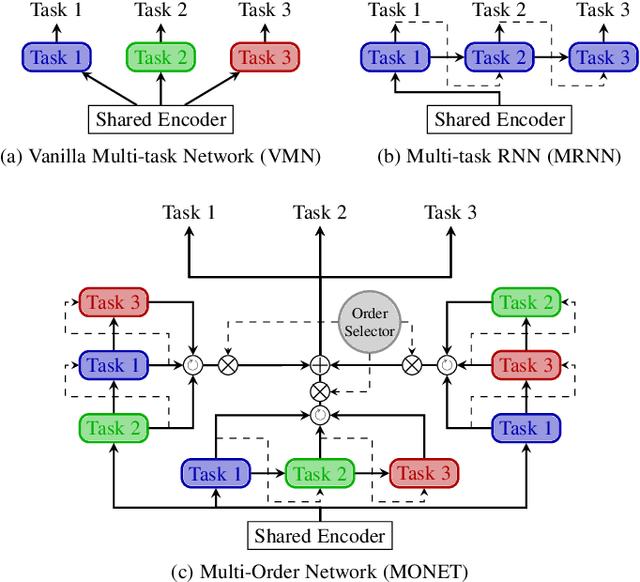
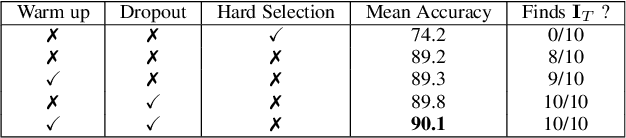
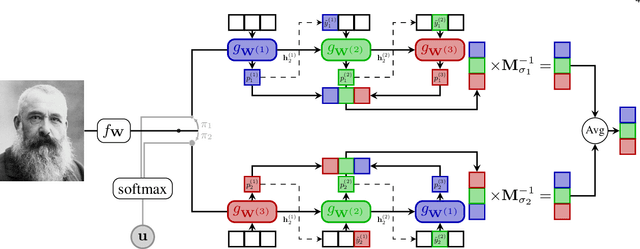
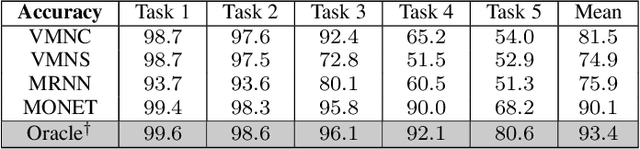
Deep multi-task methods, where several tasks are learned within a single network, have recently attracted increasing attention. Burning point of this attention is their capacity to capture inter-task relationships. Current approaches either only rely on weight sharing, or add explicit dependency modelling by decomposing the task joint distribution using Bayes chain rule. If the latter strategy yields comprehensive inter-task relationships modelling, it requires imposing an arbitrary order into an unordered task set. Most importantly, this sequence ordering choice has been identified as a critical source of performance variations. In this paper, we present Multi-Order Network (MONET), a multi-task learning method with joint task order optimization. MONET uses a differentiable order selection based on soft order modelling inside Birkhoff's polytope to jointly learn task-wise recurrent modules with their optimal chaining order. Furthermore, we introduce warm up and order dropout to enhance order selection by encouraging order exploration. Experimentally, we first validate MONET capacity to retrieve the optimal order in a toy environment. Second, we use an attribute detection scenario to show that MONET outperforms existing multi-task baselines on a wide range of dependency settings. Finally, we demonstrate that MONET significantly extends state-of-the-art performance in Facial Action Unit detection.