 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Discriminative Text Representations via Agreement and Label Disentanglement
May 20, 2026Interpretable text representations should expose coordinates that are not only predictive, but also meaningful enough for independent auditors to apply. Existing discriminative representations often use anonymous embedding directions, while concept-bottleneck and LLM-assisted methods attach natural-language names to features without ensuring that those definitions are reproducible or distinct from the target label. We propose an operational criterion for interpretable discriminative text representations: each coordinate should satisfy conceptual clarity, measured by chance-adjusted agreement between independent annotators applying the feature definition, and label disentanglement, meaning the feature should not merely paraphrase the prediction target. We instantiate this criterion in LLM-assisted Feature Discovery (LFD), an iterative method that proposes lexical and semantic features from contrastive outcome-opposed text pairs, screens candidates using cross-LLM Cohen's $κ$, and selects features by residual held-out predictive gain. A stylized analysis connects the $κ$ screen to a per-feature annotation-noise bound, formalizing agreement as a reliability check. Across ten text-classification tasks spanning seven corpora, LFD matches the predictive performance of a strong text bottleneck baseline while producing substantially clearer and less label-entangled features. Human audits with 232 raters show that LFD features achieve higher human--human and human--LLM agreement than baseline concepts, and raters consistently judge them as less label-leaking. These results suggest that agreement-tested, label-disentangled coordinates provide a practical auditability standard for interpretable text classification.
VLS: Steering Pretrained Robot Policies via Vision-Language Models
Feb 03, 2026Why do pretrained diffusion or flow-matching policies fail when the same task is performed near an obstacle, on a shifted support surface, or amid mild clutter? Such failures rarely reflect missing motor skills; instead, they expose a limitation of imitation learning under train-test shifts, where action generation is tightly coupled to training-specific spatial configurations and task specifications. Retraining or fine-tuning to address these failures is costly and conceptually misaligned, as the required behaviors already exist but cannot be selectively adapted at test time. We propose Vision-Language Steering (VLS), a training-free framework for inference-time adaptation of frozen generative robot policies. VLS treats adaptation as an inference-time control problem, steering the sampling process of a pretrained diffusion or flow-matching policy in response to out-of-distribution observation-language inputs without modifying policy parameters. By leveraging vision-language models to synthesize trajectory-differentiable reward functions, VLS guides denoising toward action trajectories that satisfy test-time spatial and task requirements. Across simulation and real-world evaluations, VLS consistently outperforms prior steering methods, achieving a 31% improvement on CALVIN and a 13% gain on LIBERO-PRO. Real-world deployment on a Franka robot further demonstrates robust inference-time adaptation under test-time spatial and semantic shifts. Project page: https://vision-language-steering.github.io/webpage/
MovSAM: A Single-image Moving Object Segmentation Framework Based on Deep Thinking
Apr 09, 2025Moving object segmentation plays a vital role in understanding dynamic visual environments. While existing methods rely on multi-frame image sequences to identify moving objects, single-image MOS is critical for applications like motion intention prediction and handling camera frame drops. However, segmenting moving objects from a single image remains challenging for existing methods due to the absence of temporal cues. To address this gap, we propose MovSAM, the first framework for single-image moving object segmentation. MovSAM leverages a Multimodal Large Language Model (MLLM) enhanced with Chain-of-Thought (CoT) prompting to search the moving object and generate text prompts based on deep thinking for segmentation. These prompts are cross-fused with visual features from the Segment Anything Model (SAM) and a Vision-Language Model (VLM), enabling logic-driven moving object segmentation. The segmentation results then undergo a deep thinking refinement loop, allowing MovSAM to iteratively improve its understanding of the scene context and inter-object relationships with logical reasoning. This innovative approach enables MovSAM to segment moving objects in single images by considering scene understanding. We implement MovSAM in the real world to validate its practical application and effectiveness for autonomous driving scenarios where the multi-frame methods fail. Furthermore, despite the inherent advantage of multi-frame methods in utilizing temporal information, MovSAM achieves state-of-the-art performance across public MOS benchmarks, reaching 92.5\% on J\&F. Our implementation will be available at https://github.com/IRMVLab/MovSAM.
"Set It Up!": Functional Object Arrangement with Compositional Generative Models
May 20, 2024



This paper studies the challenge of developing robots capable of understanding under-specified instructions for creating functional object arrangements, such as "set up a dining table for two"; previous arrangement approaches have focused on much more explicit instructions, such as "put object A on the table." We introduce a framework, SetItUp, for learning to interpret under-specified instructions. SetItUp takes a small number of training examples and a human-crafted program sketch to uncover arrangement rules for specific scene types. By leveraging an intermediate graph-like representation of abstract spatial relationships among objects, SetItUp decomposes the arrangement problem into two subproblems: i) learning the arrangement patterns from limited data and ii) grounding these abstract relationships into object poses. SetItUp leverages large language models (LLMs) to propose the abstract spatial relationships among objects in novel scenes as the constraints to be satisfied; then, it composes a library of diffusion models associated with these abstract relationships to find object poses that satisfy the constraints. We validate our framework on a dataset comprising study desks, dining tables, and coffee tables, with the results showing superior performance in generating physically plausible, functional, and aesthetically pleasing object arrangements compared to existing models.
Differentiable Particles for General-Purpose Deformable Object Manipulation
May 02, 2024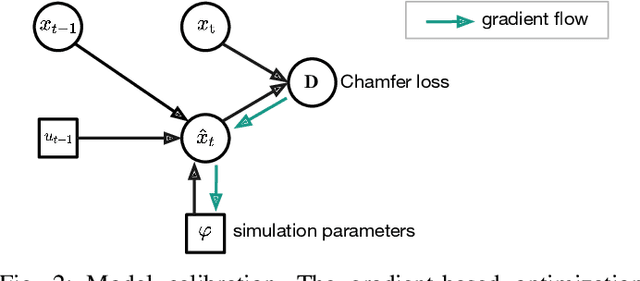
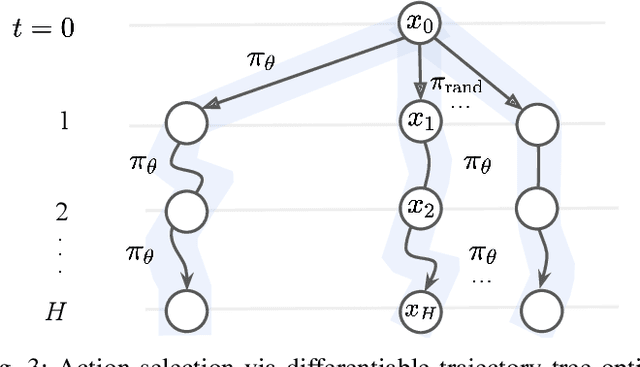

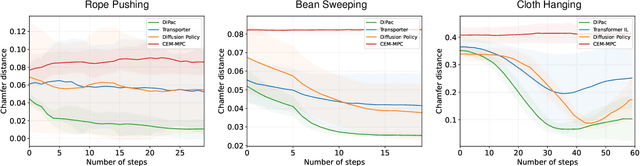
Deformable object manipulation is a long-standing challenge in robotics. While existing approaches often focus narrowly on a specific type of object, we seek a general-purpose algorithm, capable of manipulating many different types of objects: beans, rope, cloth, liquid, . . . . One key difficulty is a suitable representation, rich enough to capture object shape, dynamics for manipulation and yet simple enough to be acquired effectively from sensor data. Specifically, we propose Differentiable Particles (DiPac), a new algorithm for deformable object manipulation. DiPac represents a deformable object as a set of particles and uses a differentiable particle dynamics simulator to reason about robot manipulation. To find the best manipulation action, DiPac combines learning, planning, and trajectory optimization through differentiable trajectory tree optimization. Differentiable dynamics provides significant benefits and enable DiPac to (i) estimate the dynamics parameters efficiently, thereby narrowing the sim-to-real gap, and (ii) choose the best action by backpropagating the gradient along sampled trajectories. Both simulation and real-robot experiments show promising results. DiPac handles a variety of object types. By combining planning and learning, DiPac outperforms both pure model-based planning methods and pure data-driven learning methods. In addition, DiPac is robust and adapts to changes in dynamics, thereby enabling the transfer of an expert policy from one object to another with different physical properties, e.g., from a rigid rod to a deformable rope.
LLMs for Robotic Object Disambiguation
Jan 07, 2024



The advantages of pre-trained large language models (LLMs) are apparent in a variety of language processing tasks. But can a language model's knowledge be further harnessed to effectively disambiguate objects and navigate decision-making challenges within the realm of robotics? Our study reveals the LLM's aptitude for solving complex decision making challenges that are often previously modeled by Partially Observable Markov Decision Processes (POMDPs). A pivotal focus of our research is the object disambiguation capability of LLMs. We detail the integration of an LLM into a tabletop environment disambiguation task, a decision making problem where the robot's task is to discern and retrieve a user's desired object from an arbitrarily large and complex cluster of objects. Despite multiple query attempts with zero-shot prompt engineering (details can be found in the Appendix), the LLM struggled to inquire about features not explicitly provided in the scene description. In response, we have developed a few-shot prompt engineering system to improve the LLM's ability to pose disambiguating queries. The result is a model capable of both using given features when they are available and inferring new relevant features when necessary, to successfully generate and navigate down a precise decision tree to the correct object--even when faced with identical options.
Learning Reward for Physical Skills using Large Language Model
Oct 21, 2023



Learning reward functions for physical skills are challenging due to the vast spectrum of skills, the high-dimensionality of state and action space, and nuanced sensory feedback. The complexity of these tasks makes acquiring expert demonstration data both costly and time-consuming. Large Language Models (LLMs) contain valuable task-related knowledge that can aid in learning these reward functions. However, the direct application of LLMs for proposing reward functions has its limitations such as numerical instability and inability to incorporate the environment feedback. We aim to extract task knowledge from LLMs using environment feedback to create efficient reward functions for physical skills. Our approach consists of two components. We first use the LLM to propose features and parameterization of the reward function. Next, we update the parameters of this proposed reward function through an iterative self-alignment process. In particular, this process minimizes the ranking inconsistency between the LLM and our learned reward functions based on the new observations. We validated our method by testing it on three simulated physical skill learning tasks, demonstrating effective support for our design choices.
How to Tidy Up a Table: Fusing Visual and Semantic Commonsense Reasoning for Robotic Tasks with Vague Objectives
Jul 21, 2023


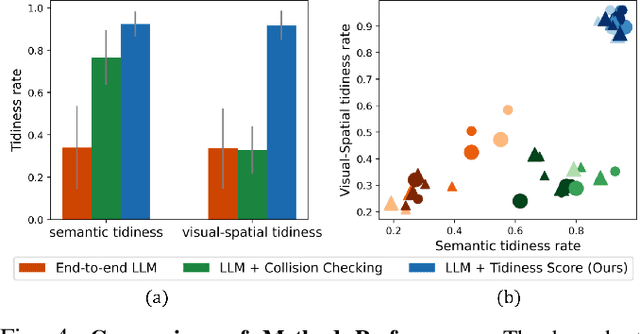
Vague objectives in many real-life scenarios pose long-standing challenges for robotics, as defining rules, rewards, or constraints for optimization is difficult. Tasks like tidying a messy table may appear simple for humans, but articulating the criteria for tidiness is complex due to the ambiguity and flexibility in commonsense reasoning. Recent advancement in Large Language Models (LLMs) offers us an opportunity to reason over these vague objectives: learned from extensive human data, LLMs capture meaningful common sense about human behavior. However, as LLMs are trained solely on language input, they may struggle with robotic tasks due to their limited capacity to account for perception and low-level controls. In this work, we propose a simple approach to solve the task of table tidying, an example of robotic tasks with vague objectives. Specifically, the task of tidying a table involves not just clustering objects by type and functionality for semantic tidiness but also considering spatial-visual relations of objects for a visually pleasing arrangement, termed as visual tidiness. We propose to learn a lightweight, image-based tidiness score function to ground the semantically tidy policy of LLMs to achieve visual tidiness. We innovatively train the tidiness score using synthetic data gathered using random walks from a few tidy configurations. Such trajectories naturally encode the order of tidiness, thereby eliminating the need for laborious and expensive human demonstrations. Our empirical results show that our pipeline can be applied to unseen objects and complex 3D arrangements.
On the Effective Horizon of Inverse Reinforcement Learning
Jul 13, 2023



Inverse reinforcement learning (IRL) algorithms often rely on (forward) reinforcement learning or planning over a given time horizon to compute an approximately optimal policy for a hypothesized reward function and then match this policy with expert demonstrations. The time horizon plays a critical role in determining both the accuracy of reward estimate and the computational efficiency of IRL algorithms. Interestingly, an effective time horizon shorter than the ground-truth value often produces better results faster. This work formally analyzes this phenomenon and provides an explanation: the time horizon controls the complexity of an induced policy class and mitigates overfitting with limited data. This analysis leads to a principled choice of the effective horizon for IRL. It also prompts us to reexamine the classic IRL formulation: it is more natural to learn jointly the reward and the effective horizon together rather than the reward alone with a given horizon. Our experimental results confirm the theoretical analysis.
COACH: Cooperative Robot Teaching
Feb 13, 2023



Knowledge and skills can transfer from human teachers to human students. However, such direct transfer is often not scalable for physical tasks, as they require one-to-one interaction, and human teachers are not available in sufficient numbers. Machine learning enables robots to become experts and play the role of teachers to help in this situation. In this work, we formalize cooperative robot teaching as a Markov game, consisting of four key elements: the target task, the student model, the teacher model, and the interactive teaching-learning process. Under a moderate assumption, the Markov game reduces to a partially observable Markov decision process, with an efficient approximate solution. We illustrate our approach on two cooperative tasks, one in a simulated video game and one with a real robot.