 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards the Vision-Sound-Language-Action Paradigm: The HEAR Framework for Sound-Centric Manipulation
Mar 17, 2026While recent Vision-Language-Action (VLA) models have begun to incorporate audio, they typically treat sound as static pre-execution prompts or focus exclusively on human speech. This leaves a significant gap in real-time, sound-centric manipulation where fleeting environmental acoustics provide critical state verification during task execution. Consequently, key sounds are easily missed due to low-frequency updates or system latency. This problem is exacerbated by action chunking with open-loop execution, which creates a Blind Execution Interval where acoustic events are lost between discrete audio observation windows. Recognizing the necessity of continuous auditory awareness, we formalize Vision-Sound-Language-Action (VSLA) as a continuous control paradigm conditioned on vision, streaming audio, language, and proprioception under delayed decision loops. As an instantiation, we introduce HEAR, a VSLA framework integrating four components: (i) a streaming Historizer to maintain a compact, causal audio context across execution gaps; (ii) an Envisioner adapted from omni foundation models to reason over multi-sensory inputs; (iii) an Advancer, formulated as an audio world model, to learn temporal dynamics by predicting near-future audio codes; and (iv) a flow-matching Realizer policy to generate smooth action chunks. To address the scarcity of pretraining data and evaluations for VSLA, we construct OpenX-Sound for pretraining, alongside HEAR-Bench, the first sound-centric manipulation benchmark with strict causal timing rules. Our results suggest that robust sound-centric manipulation necessitates causal persistence and explicit temporal learning. This framework provides a practical step toward multi-sensory foundation models for embodied agents, enabling robots to perceive and interact with dynamic environments. Code and videos are available at https://hear.irmv.top.
ERMV: Editing 4D Robotic Multi-view images to enhance embodied agents
Jul 23, 2025Robot imitation learning relies on 4D multi-view sequential images. However, the high cost of data collection and the scarcity of high-quality data severely constrain the generalization and application of embodied intelligence policies like Vision-Language-Action (VLA) models. Data augmentation is a powerful strategy to overcome data scarcity, but methods for editing 4D multi-view sequential images for manipulation tasks are currently lacking. Thus, we propose ERMV (Editing Robotic Multi-View 4D data), a novel data augmentation framework that efficiently edits an entire multi-view sequence based on single-frame editing and robot state conditions. This task presents three core challenges: (1) maintaining geometric and appearance consistency across dynamic views and long time horizons; (2) expanding the working window with low computational costs; and (3) ensuring the semantic integrity of critical objects like the robot arm. ERMV addresses these challenges through a series of innovations. First, to ensure spatio-temporal consistency in motion blur, we introduce a novel Epipolar Motion-Aware Attention (EMA-Attn) mechanism that learns pixel shift caused by movement before applying geometric constraints. Second, to maximize the editing working window, ERMV pioneers a Sparse Spatio-Temporal (STT) module, which decouples the temporal and spatial views and remodels a single-frame multi-view problem through sparse sampling of the views to reduce computational demands. Third, to alleviate error accumulation, we incorporate a feedback intervention Mechanism, which uses a Multimodal Large Language Model (MLLM) to check editing inconsistencies and request targeted expert guidance only when necessary. Extensive experiments demonstrate that ERMV-augmented data significantly boosts the robustness and generalization of VLA models in both simulated and real-world environments.
MovSAM: A Single-image Moving Object Segmentation Framework Based on Deep Thinking
Apr 09, 2025Moving object segmentation plays a vital role in understanding dynamic visual environments. While existing methods rely on multi-frame image sequences to identify moving objects, single-image MOS is critical for applications like motion intention prediction and handling camera frame drops. However, segmenting moving objects from a single image remains challenging for existing methods due to the absence of temporal cues. To address this gap, we propose MovSAM, the first framework for single-image moving object segmentation. MovSAM leverages a Multimodal Large Language Model (MLLM) enhanced with Chain-of-Thought (CoT) prompting to search the moving object and generate text prompts based on deep thinking for segmentation. These prompts are cross-fused with visual features from the Segment Anything Model (SAM) and a Vision-Language Model (VLM), enabling logic-driven moving object segmentation. The segmentation results then undergo a deep thinking refinement loop, allowing MovSAM to iteratively improve its understanding of the scene context and inter-object relationships with logical reasoning. This innovative approach enables MovSAM to segment moving objects in single images by considering scene understanding. We implement MovSAM in the real world to validate its practical application and effectiveness for autonomous driving scenarios where the multi-frame methods fail. Furthermore, despite the inherent advantage of multi-frame methods in utilizing temporal information, MovSAM achieves state-of-the-art performance across public MOS benchmarks, reaching 92.5\% on J\&F. Our implementation will be available at https://github.com/IRMVLab/MovSAM.
RLSAC: Reinforcement Learning enhanced Sample Consensus for End-to-End Robust Estimation
Aug 10, 2023Robust estimation is a crucial and still challenging task, which involves estimating model parameters in noisy environments. Although conventional sampling consensus-based algorithms sample several times to achieve robustness, these algorithms cannot use data features and historical information effectively. In this paper, we propose RLSAC, a novel Reinforcement Learning enhanced SAmple Consensus framework for end-to-end robust estimation. RLSAC employs a graph neural network to utilize both data and memory features to guide exploring directions for sampling the next minimum set. The feedback of downstream tasks serves as the reward for unsupervised training. Therefore, RLSAC can avoid differentiating to learn the features and the feedback of downstream tasks for end-to-end robust estimation. In addition, RLSAC integrates a state transition module that encodes both data and memory features. Our experimental results demonstrate that RLSAC can learn from features to gradually explore a better hypothesis. Through analysis, it is apparent that RLSAC can be easily transferred to other sampling consensus-based robust estimation tasks. To the best of our knowledge, RLSAC is also the first method that uses reinforcement learning to sample consensus for end-to-end robust estimation. We release our codes at https://github.com/IRMVLab/RLSAC.
ABC: Attention with Bilinear Correlation for Infrared Small Target Detection
Mar 18, 2023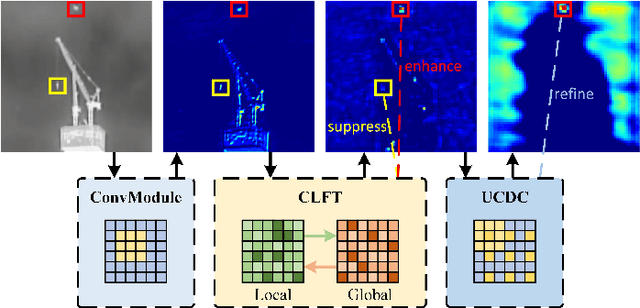
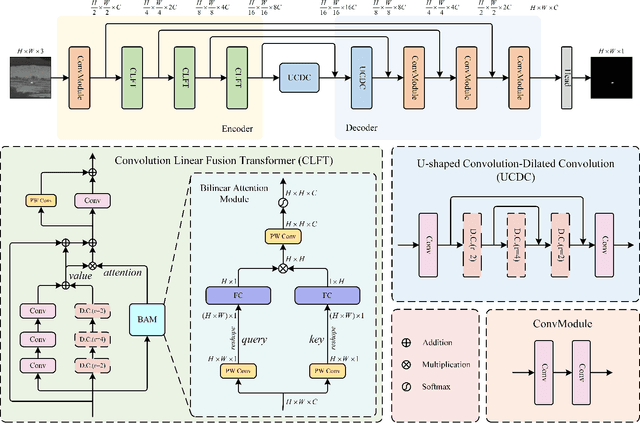
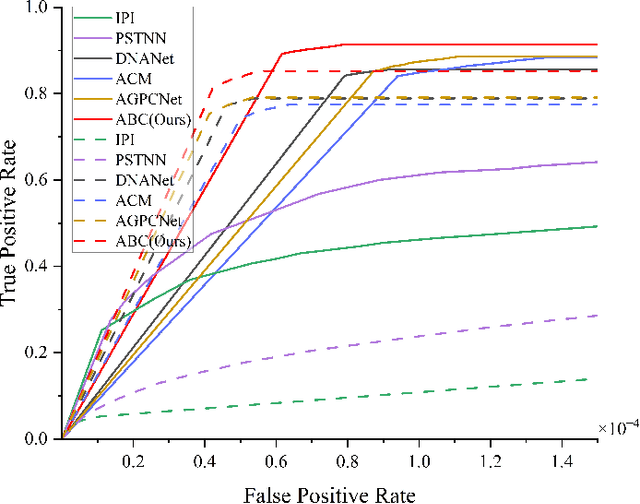
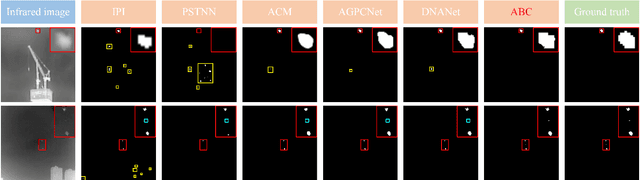
Infrared small target detection (ISTD) has a wide range of applications in early warning, rescue, and guidance. However, CNN based deep learning methods are not effective at segmenting infrared small target (IRST) that it lack of clear contour and texture features, and transformer based methods also struggle to achieve significant results due to the absence of convolution induction bias. To address these issues, we propose a new model called attention with bilinear correlation (ABC), which is based on the transformer architecture and includes a convolution linear fusion transformer (CLFT) module with a novel attention mechanism for feature extraction and fusion, which effectively enhances target features and suppresses noise. Additionally, our model includes a u-shaped convolution-dilated convolution (UCDC) module located deeper layers of the network, which takes advantage of the smaller resolution of deeper features to obtain finer semantic information. Experimental results on public datasets demonstrate that our approach achieves state-of-the-art performance. Code is available at https://github.com/PANPEIWEN/ABC
TaCo: Textual Attribute Recognition via Contrastive Learning
Aug 22, 2022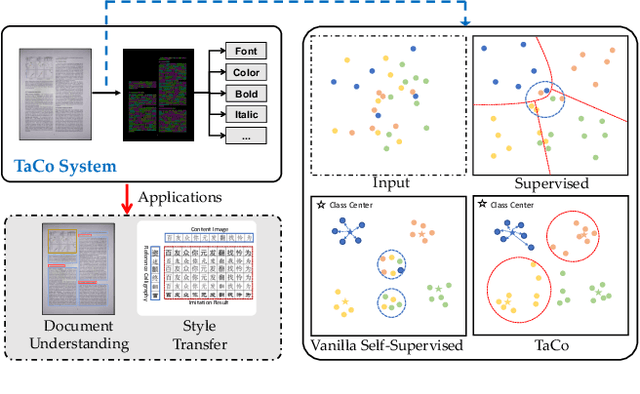
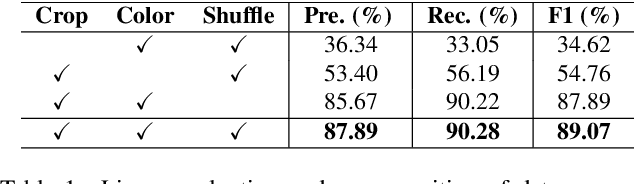
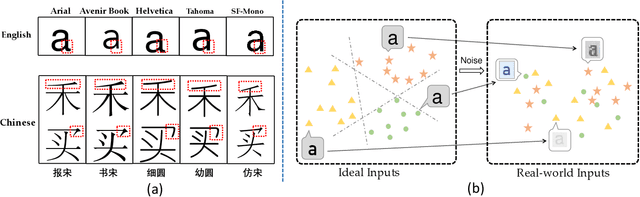
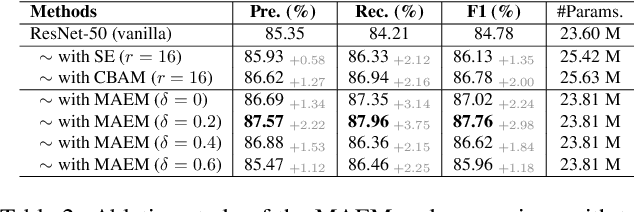
As textual attributes like font are core design elements of document format and page style, automatic attributes recognition favor comprehensive practical applications. Existing approaches already yield satisfactory performance in differentiating disparate attributes, but they still suffer in distinguishing similar attributes with only subtle difference. Moreover, their performance drop severely in real-world scenarios where unexpected and obvious imaging distortions appear. In this paper, we aim to tackle these problems by proposing TaCo, a contrastive framework for textual attribute recognition tailored toward the most common document scenes. Specifically, TaCo leverages contrastive learning to dispel the ambiguity trap arising from vague and open-ended attributes. To realize this goal, we design the learning paradigm from three perspectives: 1) generating attribute views, 2) extracting subtle but crucial details, and 3) exploiting valued view pairs for learning, to fully unlock the pre-training potential. Extensive experiments show that TaCo surpasses the supervised counterparts and advances the state-of-the-art remarkably on multiple attribute recognition tasks. Online services of TaCo will be made available.
STN: Scalable Tensorizing Networks via Structure-Aware Training and Adaptive Compression
May 30, 2022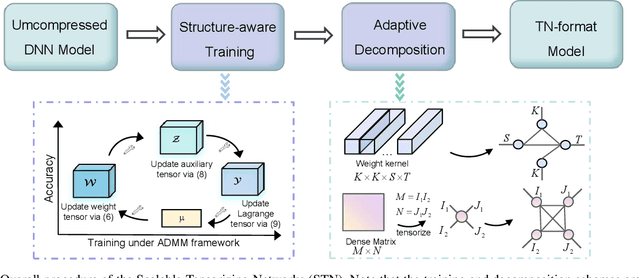

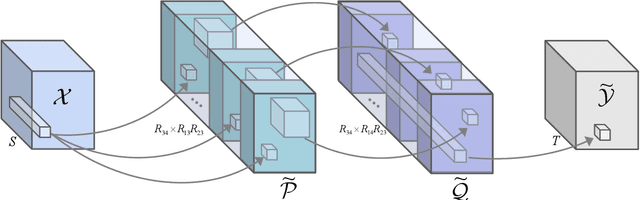

Deep neural networks (DNNs) have delivered a remarkable performance in many tasks of computer vision. However, over-parameterized representations of popular architectures dramatically increase their computational complexity and storage costs, and hinder their availability in edge devices with constrained resources. Regardless of many tensor decomposition (TD) methods that have been well-studied for compressing DNNs to learn compact representations, they suffer from non-negligible performance degradation in practice. In this paper, we propose Scalable Tensorizing Networks (STN), which dynamically and adaptively adjust the model size and decomposition structure without retraining. First, we account for compression during training by adding a low-rank regularizer to guarantee networks' desired low-rank characteristics in full tensor format. Then, considering network layers exhibit various low-rank structures, STN is obtained by a data-driven adaptive TD approach, for which the topological structure of decomposition per layer is learned from the pre-trained model, and the ranks are selected appropriately under specified storage constraints. As a result, STN is compatible with arbitrary network architectures and achieves higher compression performance and flexibility over other tensorizing versions. Comprehensive experiments on several popular architectures and benchmarks substantiate the superiority of our model towards improving parameter efficiency.
Multi-Tensor Network Representation for High-Order Tensor Completion
Sep 21, 2021

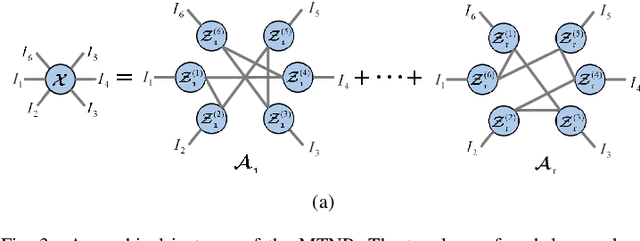

This work studies the problem of high-dimensional data (referred to as tensors) completion from partially observed samplings. We consider that a tensor is a superposition of multiple low-rank components. In particular, each component can be represented as multilinear connections over several latent factors and naturally mapped to a specific tensor network (TN) topology. In this paper, we propose a fundamental tensor decomposition (TD) framework: Multi-Tensor Network Representation (MTNR), which can be regarded as a linear combination of a range of TD models, e.g., CANDECOMP/PARAFAC (CP) decomposition, Tensor Train (TT), and Tensor Ring (TR). Specifically, MTNR represents a high-order tensor as the addition of multiple TN models, and the topology of each TN is automatically generated instead of manually pre-designed. For the optimization phase, an adaptive topology learning (ATL) algorithm is presented to obtain latent factors of each TN based on a rank incremental strategy and a projection error measurement strategy. In addition, we theoretically establish the fundamental multilinear operations for the tensors with TN representation, and reveal the structural transformation of MTNR to a single TN. Finally, MTNR is applied to a typical task, tensor completion, and two effective algorithms are proposed for the exact recovery of incomplete data based on the Alternating Least Squares (ALS) scheme and Alternating Direction Method of Multiplier (ADMM) framework. Extensive numerical experiments on synthetic data and real-world datasets demonstrate the effectiveness of MTNR compared with the start-of-the-art methods.