 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Trust Poisoning in Vehicular Collaborative Perception
May 21, 2026Collaborative perception (CP) enables connected and autonomous vehicles to share sensor data and jointly reason about their environment. To defend against adversaries that fabricate or manipulate shared data, existing systems employ cross-vehicle inconsistency detection and trust estimation, penalizing vehicles whose observations conflict with the majority. In this work, we show that these defenses themselves introduce a new attack surface. We present TrustFlip, a novel attack that weaponizes consistency-based defenses to poison the trust assigned to benign vehicles. Instead of injecting false data into the collaboration pipeline, it deploys physical adversarial objects that are genuine but induce inconsistent observations among benign vehicles. The resulting inconsistencies are misattributed by the defense to the targeted vehicle, causing its trust score to degrade and eventually leading to its downweighting or exclusion from collaboration. Consequently, the system loses reliable sensing contributors, degrading perception capability and potentially inducing safety-critical failures. We evaluate TrustFlip across multiple collaborative perception architectures and defense mechanisms. Our results show that state-of-the-art defenses can be significantly affected: the attack removes the targeted benign vehicle from collaboration in up to 87.7% of scenarios and drops Average Precision (AP) by up to 13%. As an initial mitigation, we introduce TrustReflect, a lightweight self-reflection mechanism that marks disputed regions as uncertain and excludes them from trust evaluation, reducing the attack success rate by 35-100%.
Systematic Discovery of Semantic Attacks in Online Map Construction through Conditional Diffusion
May 14, 2026Autonomous vehicles depend on online HD map construction to perceive lane boundaries, dividers, and pedestrian crossings -- safety-critical road elements that directly govern motion planning. While existing pixel perturbation attacks can disrupt the mapping, they can be neutralized by standard adversarial defenses. We present MIRAGE, a framework for systematic discovery of semantic attacks that bypass adversarial defenses and degrade mapping predictions by finding plausible environmental variation (e.g. shadows, wet roads). MIRAGE exploits the latent manifold of real-world data learned by diffusion models, and searches for semantically mutated scenes neighboring the ground truth with the same road topology yet mislead the mapping predictions. We evaluate MIRAGE on nuScenes and demonstrate two attacks: (1) boundary removal, suppressing 57.7% of detections and corrupting 96% of planned trajectories; and (2) boundary injection, the only method that successfully injects fictitious boundaries, while pixel PGD and AdvPatch fail entirely. Both attacks remain potent under various adversarial defenses. We use two independent VLM judges to quantify realism, where MIRAGE passes as realistic 80--84% of the time (vs. 97--99% for clean nuScenes), while AdvPatch only 0--9%. Our findings expose a categorical gap in current adversarial defenses: semantic-level perturbations that manifest as legitimate environmental variation are substantially harder to mitigate than pixel-level perturbations.
LaMP: Learning Vision-Language-Action Policies with 3D Scene Flow as Latent Motion Prior
Mar 26, 2026We introduce \textbf{LaMP}, a dual-expert Vision-Language-Action framework that embeds dense 3D scene flow as a latent motion prior for robotic manipulation. Existing VLA models regress actions directly from 2D semantic visual features, forcing them to learn complex 3D physical interactions implicitly. This implicit learning strategy degrades under unfamiliar spatial dynamics. LaMP addresses this limitation by aligning a flow-matching \emph{Motion Expert} with a policy-predicting \emph{Action Expert} through gated cross-attention. Specifically, the Motion Expert generates a one-step partially denoised 3D scene flow, and its hidden states condition the Action Expert without full multi-step reconstruction. We evaluate LaMP on the LIBERO, LIBERO-Plus, and SimplerEnv-WidowX simulation benchmarks as well as real-world experiments. LaMP consistently outperforms evaluated VLA baselines across LIBERO, LIBERO-Plus, and SimplerEnv-WidowX benchmarks, achieving the highest reported average success rates under the same training budgets. On LIBERO-Plus OOD perturbations, LaMP shows improved robustness with an average 9.7% gain over the strongest prior baseline. Our project page is available at https://summerwxk.github.io/lamp-project-page/.
A Long-term Value Prediction Framework In Video Ranking
Feb 19, 2026Accurately modeling long-term value (LTV) at the ranking stage of short-video recommendation remains challenging. While delayed feedback and extended engagement have been explored, fine-grained attribution and robust position normalization at billion-scale are still underdeveloped. We propose a practical ranking-stage LTV framework addressing three challenges: position bias, attribution ambiguity, and temporal limitations. (1) Position bias: We introduce a Position-aware Debias Quantile (PDQ) module that normalizes engagement via quantile-based distributions, enabling position-robust LTV estimation without architectural changes. (2) Attribution ambiguity: We propose a multi-dimensional attribution module that learns continuous attribution strengths across contextual, behavioral, and content signals, replacing static rules to capture nuanced inter-video influence. A customized hybrid loss with explicit noise filtering improves causal clarity. (3) Temporal limitations: We present a cross-temporal author modeling module that builds censoring-aware, day-level LTV targets to capture creator-driven re-engagement over longer horizons; the design is extensible to other dimensions (e.g., topics, styles). Offline studies and online A/B tests show significant improvements in LTV metrics and stable trade-offs with short-term objectives. Implemented as task augmentation within an existing ranking model, the framework supports efficient training and serving, and has been deployed at billion-scale in Taobao's production system, delivering sustained engagement gains while remaining compatible with industrial constraints.
ABC: Attention with Bilinear Correlation for Infrared Small Target Detection
Mar 18, 2023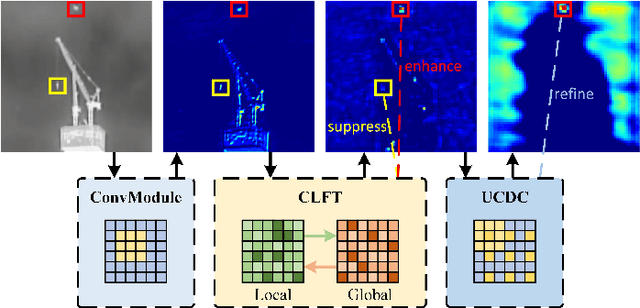
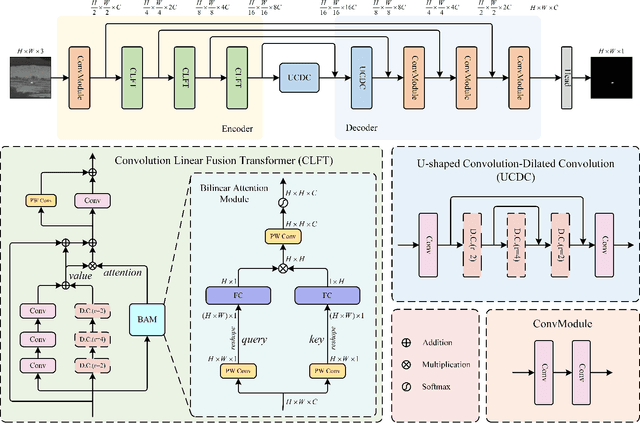
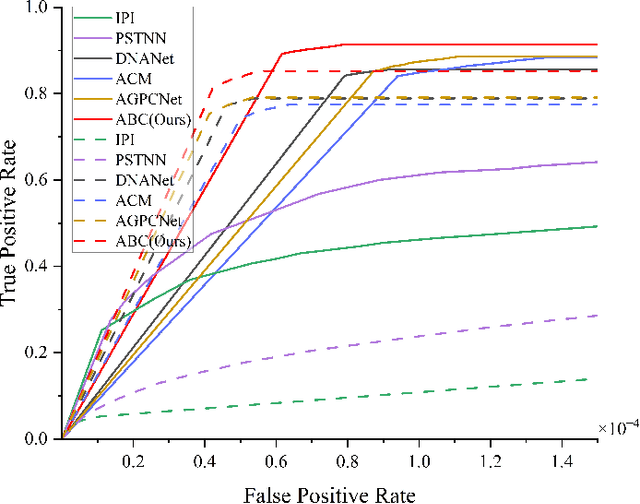
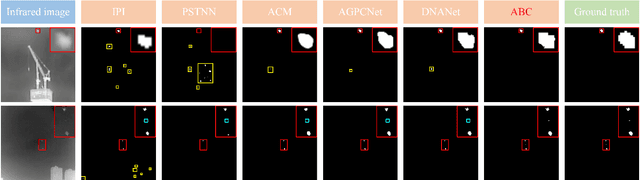
Infrared small target detection (ISTD) has a wide range of applications in early warning, rescue, and guidance. However, CNN based deep learning methods are not effective at segmenting infrared small target (IRST) that it lack of clear contour and texture features, and transformer based methods also struggle to achieve significant results due to the absence of convolution induction bias. To address these issues, we propose a new model called attention with bilinear correlation (ABC), which is based on the transformer architecture and includes a convolution linear fusion transformer (CLFT) module with a novel attention mechanism for feature extraction and fusion, which effectively enhances target features and suppresses noise. Additionally, our model includes a u-shaped convolution-dilated convolution (UCDC) module located deeper layers of the network, which takes advantage of the smaller resolution of deeper features to obtain finer semantic information. Experimental results on public datasets demonstrate that our approach achieves state-of-the-art performance. Code is available at https://github.com/PANPEIWEN/ABC
Local Contrast and Global Contextual Information Make Infrared Small Object Salient Again
Jan 31, 2023Infrared small object detection (ISOS) aims to segment small objects only covered with several pixels from clutter background in infrared images. It's of great challenge due to: 1) small objects lack of sufficient intensity, shape and texture information; 2) small objects are easily lost in the process where detection models, say deep neural networks, obtain high-level semantic features and image-level receptive fields through successive downsampling. This paper proposes a reliable detection model for ISOS, dubbed UCFNet, which can handle well the two issues. It builds upon central difference convolution (CDC) and fast Fourier convolution (FFC). On one hand, CDC can effectively guide the network to learn the contrast information between small objects and the background, as the contrast information is very essential in human visual system dealing with the ISOS task. On the other hand, FFC can gain image-level receptive fields and extract global information while preventing small objects from being overwhelmed.Experiments on several public datasets demonstrate that our method significantly outperforms the state-of-the-art ISOS models, and can provide useful guidelines for designing better ISOS deep models. Codes will be available soon.