 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYoutu-Parsing: Perception, Structuring and Recognition via High-Parallelism Decoding
Jan 28, 2026This paper presents Youtu-Parsing, an efficient and versatile document parsing model designed for high-performance content extraction. The architecture employs a native Vision Transformer (ViT) featuring a dynamic-resolution visual encoder to extract shared document features, coupled with a prompt-guided Youtu-LLM-2B language model for layout analysis and region-prompted decoding. Leveraging this decoupled and feature-reusable framework, we introduce a high-parallelism decoding strategy comprising two core components: token parallelism and query parallelism. The token parallelism strategy concurrently generates up to 64 candidate tokens per inference step, which are subsequently validated through a verification mechanism. This approach yields a 5--11x speedup over traditional autoregressive decoding and is particularly well-suited for highly structured scenarios, such as table recognition. To further exploit the advantages of region-prompted decoding, the query parallelism strategy enables simultaneous content prediction for multiple bounding boxes (up to five), providing an additional 2x acceleration while maintaining output quality equivalent to standard decoding. Youtu-Parsing encompasses a diverse range of document elements, including text, formulas, tables, charts, seals, and hierarchical structures. Furthermore, the model exhibits strong robustness when handling rare characters, multilingual text, and handwritten content. Extensive evaluations demonstrate that Youtu-Parsing achieves state-of-the-art (SOTA) performance on both the OmniDocBench and olmOCR-bench benchmarks. Overall, Youtu-Parsing demonstrates significant experimental value and practical utility for large-scale document intelligence applications.
Break the Visual Perception: Adversarial Attacks Targeting Encoded Visual Tokens of Large Vision-Language Models
Oct 09, 2024



Large vision-language models (LVLMs) integrate visual information into large language models, showcasing remarkable multi-modal conversational capabilities. However, the visual modules introduces new challenges in terms of robustness for LVLMs, as attackers can craft adversarial images that are visually clean but may mislead the model to generate incorrect answers. In general, LVLMs rely on vision encoders to transform images into visual tokens, which are crucial for the language models to perceive image contents effectively. Therefore, we are curious about one question: Can LVLMs still generate correct responses when the encoded visual tokens are attacked and disrupting the visual information? To this end, we propose a non-targeted attack method referred to as VT-Attack (Visual Tokens Attack), which constructs adversarial examples from multiple perspectives, with the goal of comprehensively disrupting feature representations and inherent relationships as well as the semantic properties of visual tokens output by image encoders. Using only access to the image encoder in the proposed attack, the generated adversarial examples exhibit transferability across diverse LVLMs utilizing the same image encoder and generality across different tasks. Extensive experiments validate the superior attack performance of the VT-Attack over baseline methods, demonstrating its effectiveness in attacking LVLMs with image encoders, which in turn can provide guidance on the robustness of LVLMs, particularly in terms of the stability of the visual feature space.
TaCo: Textual Attribute Recognition via Contrastive Learning
Aug 22, 2022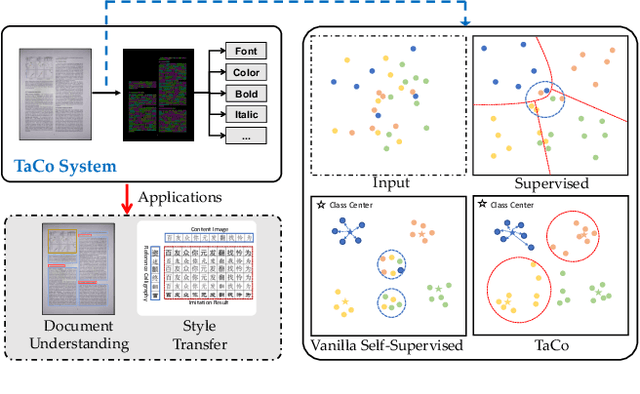
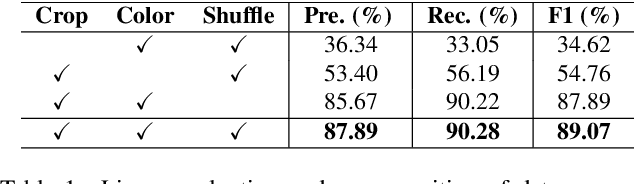
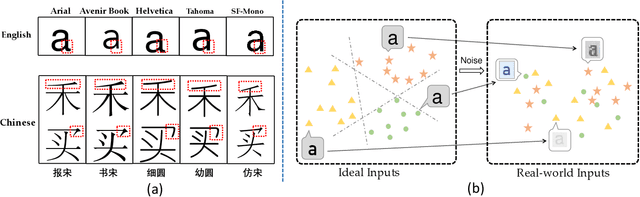
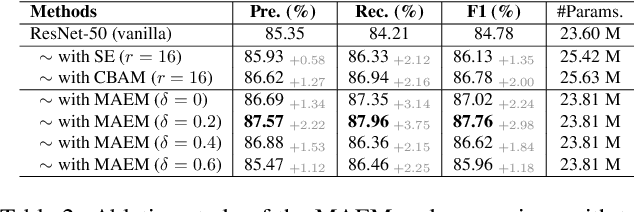
As textual attributes like font are core design elements of document format and page style, automatic attributes recognition favor comprehensive practical applications. Existing approaches already yield satisfactory performance in differentiating disparate attributes, but they still suffer in distinguishing similar attributes with only subtle difference. Moreover, their performance drop severely in real-world scenarios where unexpected and obvious imaging distortions appear. In this paper, we aim to tackle these problems by proposing TaCo, a contrastive framework for textual attribute recognition tailored toward the most common document scenes. Specifically, TaCo leverages contrastive learning to dispel the ambiguity trap arising from vague and open-ended attributes. To realize this goal, we design the learning paradigm from three perspectives: 1) generating attribute views, 2) extracting subtle but crucial details, and 3) exploiting valued view pairs for learning, to fully unlock the pre-training potential. Extensive experiments show that TaCo surpasses the supervised counterparts and advances the state-of-the-art remarkably on multiple attribute recognition tasks. Online services of TaCo will be made available.