 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaCo: Textual Attribute Recognition via Contrastive Learning
Paper and Code
Aug 22, 2022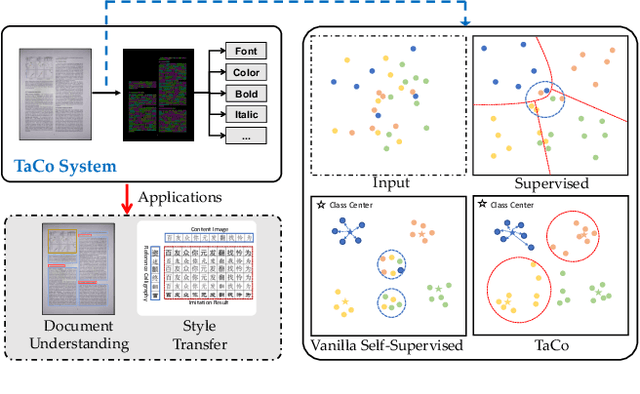
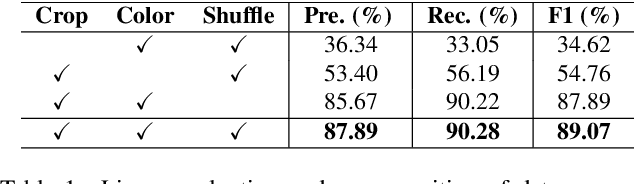
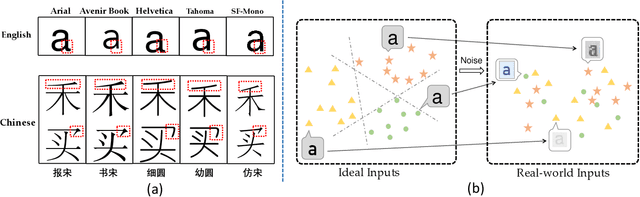
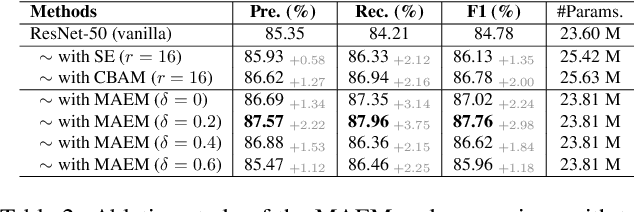
As textual attributes like font are core design elements of document format and page style, automatic attributes recognition favor comprehensive practical applications. Existing approaches already yield satisfactory performance in differentiating disparate attributes, but they still suffer in distinguishing similar attributes with only subtle difference. Moreover, their performance drop severely in real-world scenarios where unexpected and obvious imaging distortions appear. In this paper, we aim to tackle these problems by proposing TaCo, a contrastive framework for textual attribute recognition tailored toward the most common document scenes. Specifically, TaCo leverages contrastive learning to dispel the ambiguity trap arising from vague and open-ended attributes. To realize this goal, we design the learning paradigm from three perspectives: 1) generating attribute views, 2) extracting subtle but crucial details, and 3) exploiting valued view pairs for learning, to fully unlock the pre-training potential. Extensive experiments show that TaCo surpasses the supervised counterparts and advances the state-of-the-art remarkably on multiple attribute recognition tasks. Online services of TaCo will be made available.