 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaCo: Textual Attribute Recognition via Contrastive Learning
Aug 22, 2022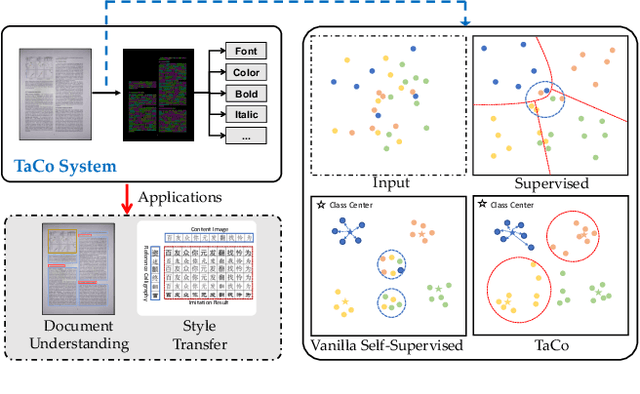
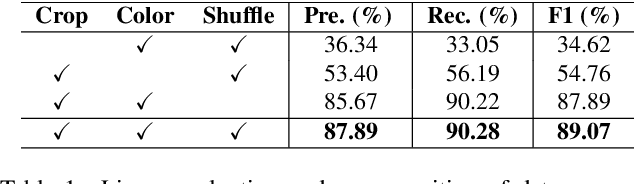
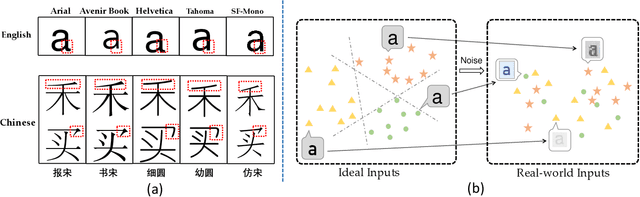
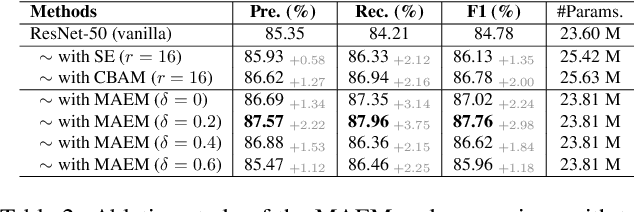
As textual attributes like font are core design elements of document format and page style, automatic attributes recognition favor comprehensive practical applications. Existing approaches already yield satisfactory performance in differentiating disparate attributes, but they still suffer in distinguishing similar attributes with only subtle difference. Moreover, their performance drop severely in real-world scenarios where unexpected and obvious imaging distortions appear. In this paper, we aim to tackle these problems by proposing TaCo, a contrastive framework for textual attribute recognition tailored toward the most common document scenes. Specifically, TaCo leverages contrastive learning to dispel the ambiguity trap arising from vague and open-ended attributes. To realize this goal, we design the learning paradigm from three perspectives: 1) generating attribute views, 2) extracting subtle but crucial details, and 3) exploiting valued view pairs for learning, to fully unlock the pre-training potential. Extensive experiments show that TaCo surpasses the supervised counterparts and advances the state-of-the-art remarkably on multiple attribute recognition tasks. Online services of TaCo will be made available.
GMN: Generative Multi-modal Network for Practical Document Information Extraction
Jul 11, 2022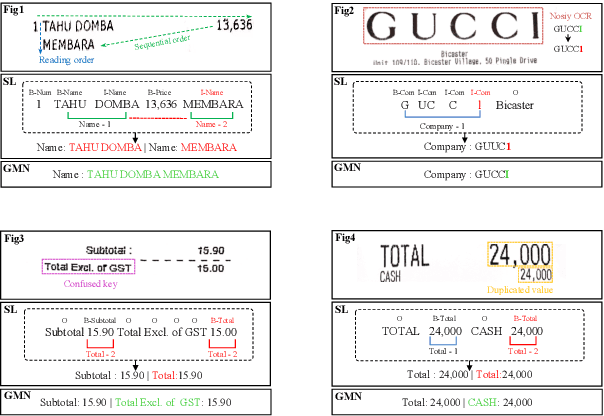

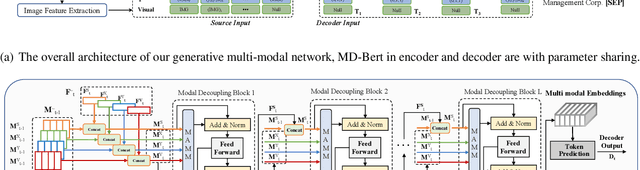
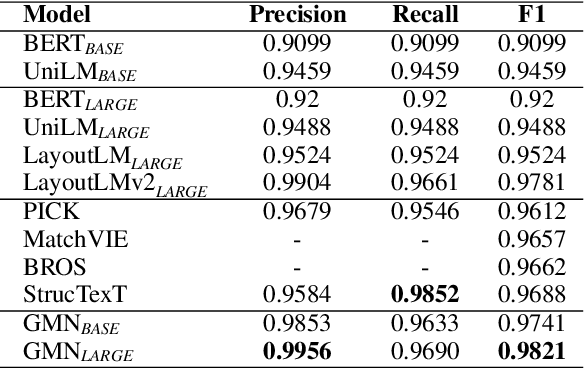
Document Information Extraction (DIE) has attracted increasing attention due to its various advanced applications in the real world. Although recent literature has already achieved competitive results, these approaches usually fail when dealing with complex documents with noisy OCR results or mutative layouts. This paper proposes Generative Multi-modal Network (GMN) for real-world scenarios to address these problems, which is a robust multi-modal generation method without predefined label categories. With the carefully designed spatial encoder and modal-aware mask module, GMN can deal with complex documents that are hard to serialized into sequential order. Moreover, GMN tolerates errors in OCR results and requires no character-level annotation, which is vital because fine-grained annotation of numerous documents is laborious and even requires annotators with specialized domain knowledge. Extensive experiments show that GMN achieves new state-of-the-art performance on several public DIE datasets and surpasses other methods by a large margin, especially in realistic scenes.
Relational Representation Learning in Visually-Rich Documents
May 05, 2022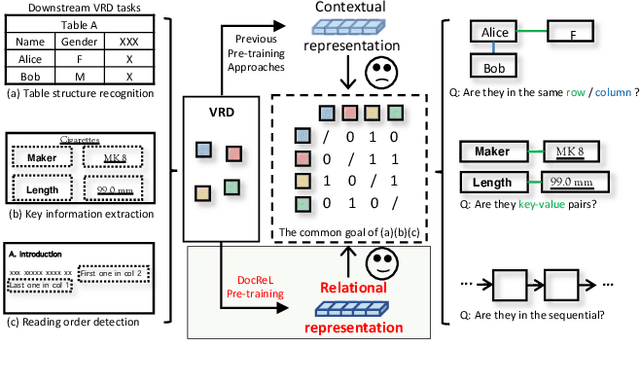
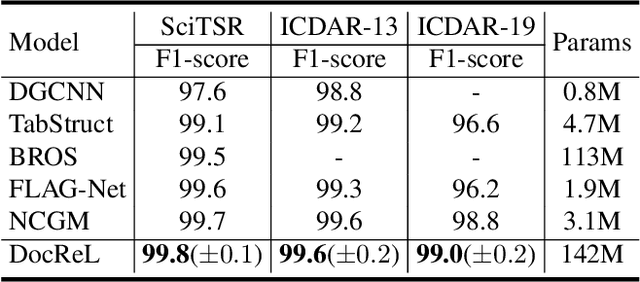

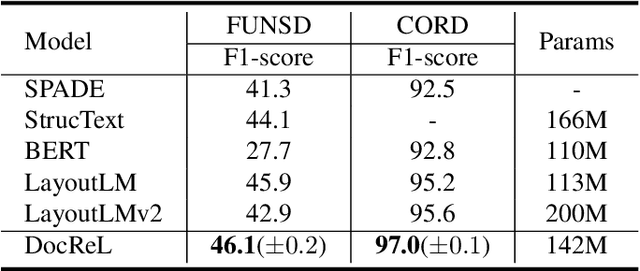
Relational understanding is critical for a number of visually-rich documents (VRDs) understanding tasks. Through multi-modal pre-training, recent studies provide comprehensive contextual representations and exploit them as prior knowledge for downstream tasks. In spite of their impressive results, we observe that the widespread relational hints (e.g., relation of key/value fields on receipts) built upon contextual knowledge are not excavated yet. To mitigate this gap, we propose DocReL, a Document Relational Representation Learning framework. The major challenge of DocReL roots in the variety of relations. From the simplest pairwise relation to the complex global structure, it is infeasible to conduct supervised training due to the definition of relation varies and even conflicts in different tasks. To deal with the unpredictable definition of relations, we propose a novel contrastive learning task named Relational Consistency Modeling (RCM), which harnesses the fact that existing relations should be consistent in differently augmented positive views. RCM provides relational representations which are more compatible to the urgent need of downstream tasks, even without any knowledge about the exact definition of relation. DocReL achieves better performance on a wide variety of VRD relational understanding tasks, including table structure recognition, key information extraction and reading order detection.
PuzzleNet: Scene Text Detection by Segment Context Graph Learning
Feb 26, 2020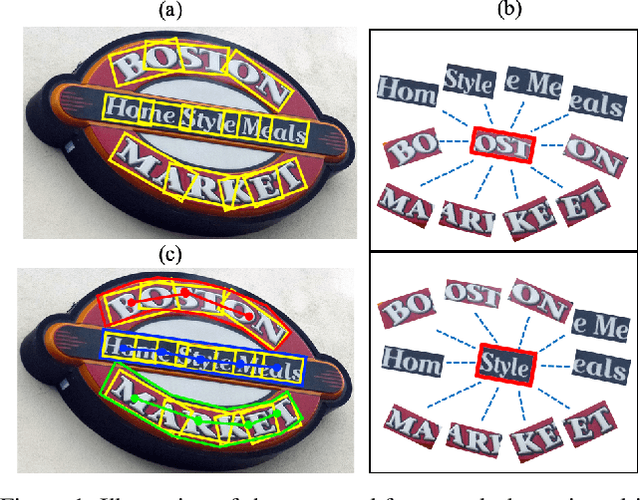
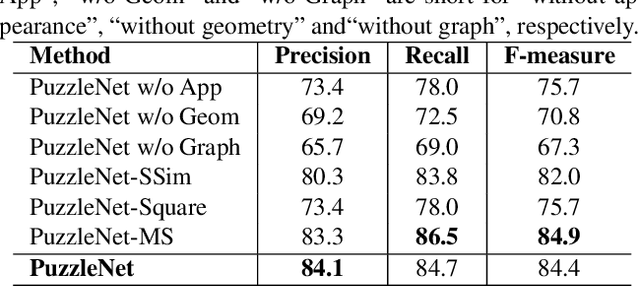

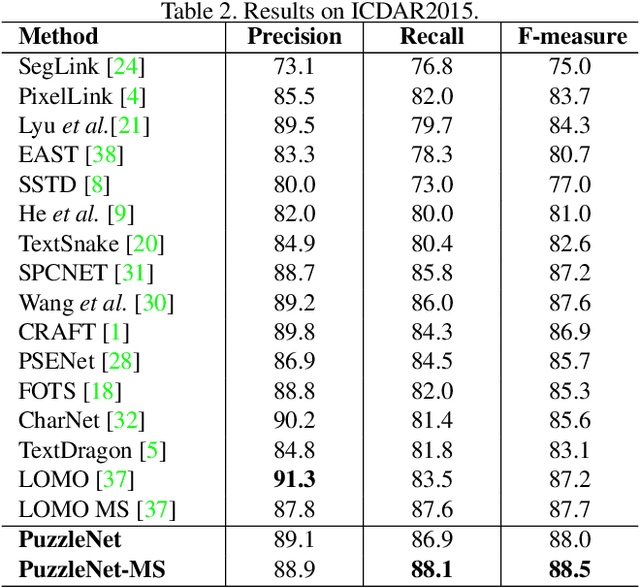
Recently, a series of decomposition-based scene text detection methods has achieved impressive progress by decomposing challenging text regions into pieces and linking them in a bottom-up manner. However, most of them merely focus on linking independent text pieces while the context information is underestimated. In the puzzle game, the solver often put pieces together in a logical way according to the contextual information of each piece, in order to arrive at the correct solution. Inspired by it, we propose a novel decomposition-based method, termed Puzzle Networks (PuzzleNet), to address the challenging scene text detection task in this work. PuzzleNet consists of the Segment Proposal Network (SPN) that predicts the candidate text segments fitting arbitrary shape of text region, and the two-branch Multiple-Similarity Graph Convolutional Network (MSGCN) that models both appearance and geometry correlations between each segment to its contextual ones. By building segments as context graphs, MSGCN effectively employs segment context to predict combinations of segments. Final detections of polygon shape are produced by merging segments according to the predicted combinations. Evaluations on three benchmark datasets, ICDAR15, MSRA-TD500 and SCUT-CTW1500, have demonstrated that our method can achieve better or comparable performance than current state-of-the-arts, which is beneficial from the exploitation of segment context graph.