 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYoutu-Parsing: Perception, Structuring and Recognition via High-Parallelism Decoding
Jan 28, 2026This paper presents Youtu-Parsing, an efficient and versatile document parsing model designed for high-performance content extraction. The architecture employs a native Vision Transformer (ViT) featuring a dynamic-resolution visual encoder to extract shared document features, coupled with a prompt-guided Youtu-LLM-2B language model for layout analysis and region-prompted decoding. Leveraging this decoupled and feature-reusable framework, we introduce a high-parallelism decoding strategy comprising two core components: token parallelism and query parallelism. The token parallelism strategy concurrently generates up to 64 candidate tokens per inference step, which are subsequently validated through a verification mechanism. This approach yields a 5--11x speedup over traditional autoregressive decoding and is particularly well-suited for highly structured scenarios, such as table recognition. To further exploit the advantages of region-prompted decoding, the query parallelism strategy enables simultaneous content prediction for multiple bounding boxes (up to five), providing an additional 2x acceleration while maintaining output quality equivalent to standard decoding. Youtu-Parsing encompasses a diverse range of document elements, including text, formulas, tables, charts, seals, and hierarchical structures. Furthermore, the model exhibits strong robustness when handling rare characters, multilingual text, and handwritten content. Extensive evaluations demonstrate that Youtu-Parsing achieves state-of-the-art (SOTA) performance on both the OmniDocBench and olmOCR-bench benchmarks. Overall, Youtu-Parsing demonstrates significant experimental value and practical utility for large-scale document intelligence applications.
Youtu-VL: Unleashing Visual Potential via Unified Vision-Language Supervision
Jan 27, 2026Despite the significant advancements represented by Vision-Language Models (VLMs), current architectures often exhibit limitations in retaining fine-grained visual information, leading to coarse-grained multimodal comprehension. We attribute this deficiency to a suboptimal training paradigm inherent in prevailing VLMs, which exhibits a text-dominant optimization bias by conceptualizing visual signals merely as passive conditional inputs rather than supervisory targets. To mitigate this, we introduce Youtu-VL, a framework leveraging the Vision-Language Unified Autoregressive Supervision (VLUAS) paradigm, which fundamentally shifts the optimization objective from ``vision-as-input'' to ``vision-as-target.'' By integrating visual tokens directly into the prediction stream, Youtu-VL applies unified autoregressive supervision to both visual details and linguistic content. Furthermore, we extend this paradigm to encompass vision-centric tasks, enabling a standard VLM to perform vision-centric tasks without task-specific additions. Extensive empirical evaluations demonstrate that Youtu-VL achieves competitive performance on both general multimodal tasks and vision-centric tasks, establishing a robust foundation for the development of comprehensive generalist visual agents.
Enhancing Visual Document Understanding with Contrastive Learning in Large Visual-Language Models
Feb 29, 2024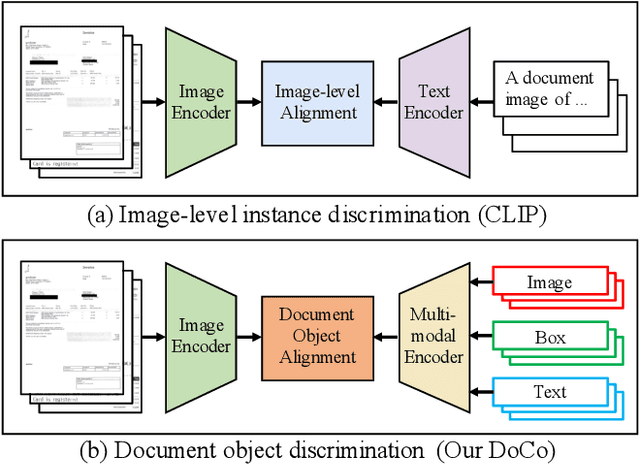
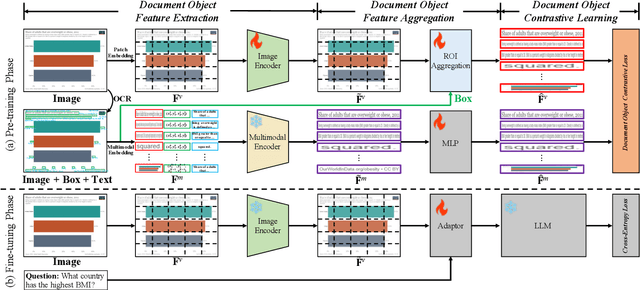
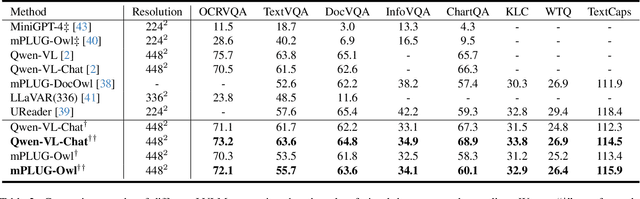
Recently, the advent of Large Visual-Language Models (LVLMs) has received increasing attention across various domains, particularly in the field of visual document understanding (VDU). Different from conventional vision-language tasks, VDU is specifically concerned with text-rich scenarios containing abundant document elements. Nevertheless, the importance of fine-grained features remains largely unexplored within the community of LVLMs, leading to suboptimal performance in text-rich scenarios. In this paper, we abbreviate it as the fine-grained feature collapse issue. With the aim of filling this gap, we propose a contrastive learning framework, termed Document Object COntrastive learning (DoCo), specifically tailored for the downstream tasks of VDU. DoCo leverages an auxiliary multimodal encoder to obtain the features of document objects and align them to the visual features generated by the vision encoder of LVLM, which enhances visual representation in text-rich scenarios. It can represent that the contrastive learning between the visual holistic representations and the multimodal fine-grained features of document objects can assist the vision encoder in acquiring more effective visual cues, thereby enhancing the comprehension of text-rich documents in LVLMs. We also demonstrate that the proposed DoCo serves as a plug-and-play pre-training method, which can be employed in the pre-training of various LVLMs without inducing any increase in computational complexity during the inference process. Extensive experimental results on multiple benchmarks of VDU reveal that LVLMs equipped with our proposed DoCo can achieve superior performance and mitigate the gap between VDU and generic vision-language tasks.
Grab What You Need: Rethinking Complex Table Structure Recognition with Flexible Components Deliberation
Mar 16, 2023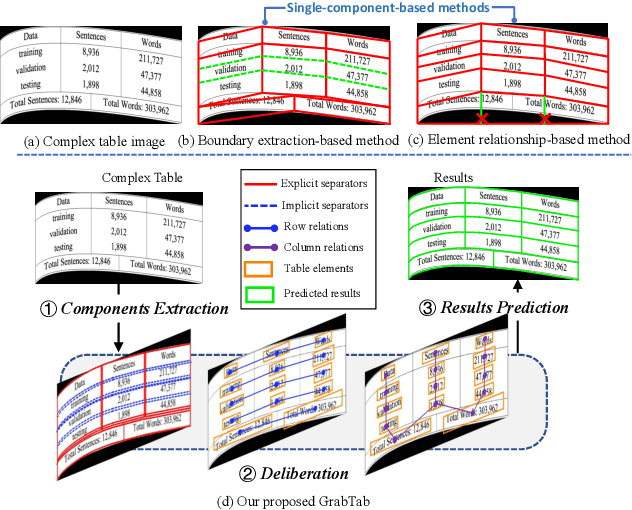
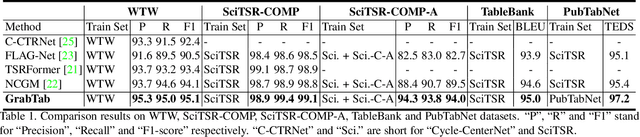
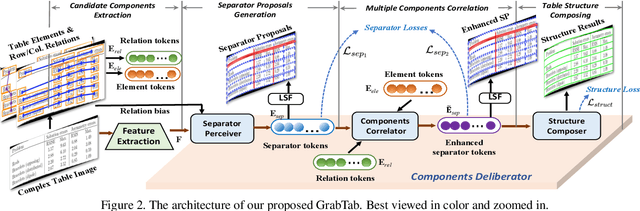

Recently, Table Structure Recognition (TSR) task, aiming at identifying table structure into machine readable formats, has received increasing interest in the community. While impressive success, most single table component-based methods can not perform well on unregularized table cases distracted by not only complicated inner structure but also exterior capture distortion. In this paper, we raise it as Complex TSR problem, where the performance degeneration of existing methods is attributable to their inefficient component usage and redundant post-processing. To mitigate it, we shift our perspective from table component extraction towards the efficient multiple components leverage, which awaits further exploration in the field. Specifically, we propose a seminal method, termed GrabTab, equipped with newly proposed Component Deliberator. Thanks to its progressive deliberation mechanism, our GrabTab can flexibly accommodate to most complex tables with reasonable components selected but without complicated post-processing involved. Quantitative experimental results on public benchmarks demonstrate that our method significantly outperforms the state-of-the-arts, especially under more challenging scenes.
Relational Representation Learning in Visually-Rich Documents
May 05, 2022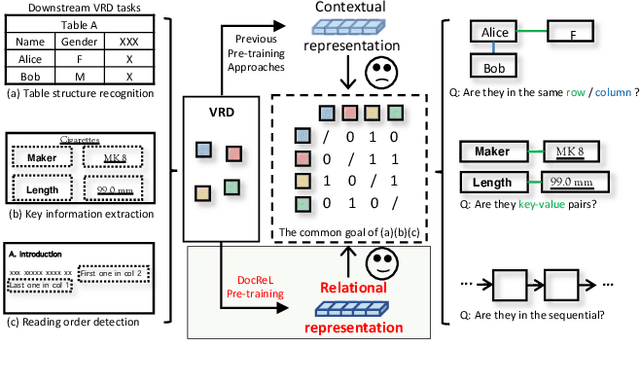
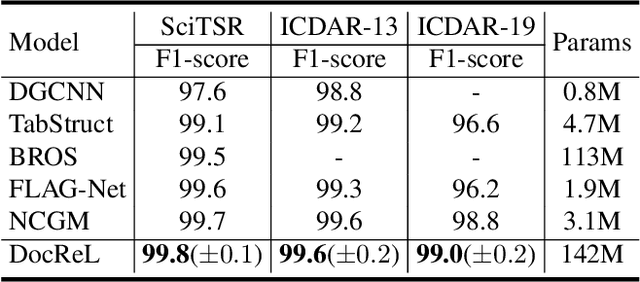

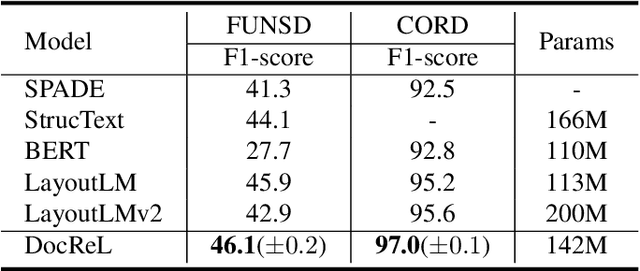
Relational understanding is critical for a number of visually-rich documents (VRDs) understanding tasks. Through multi-modal pre-training, recent studies provide comprehensive contextual representations and exploit them as prior knowledge for downstream tasks. In spite of their impressive results, we observe that the widespread relational hints (e.g., relation of key/value fields on receipts) built upon contextual knowledge are not excavated yet. To mitigate this gap, we propose DocReL, a Document Relational Representation Learning framework. The major challenge of DocReL roots in the variety of relations. From the simplest pairwise relation to the complex global structure, it is infeasible to conduct supervised training due to the definition of relation varies and even conflicts in different tasks. To deal with the unpredictable definition of relations, we propose a novel contrastive learning task named Relational Consistency Modeling (RCM), which harnesses the fact that existing relations should be consistent in differently augmented positive views. RCM provides relational representations which are more compatible to the urgent need of downstream tasks, even without any knowledge about the exact definition of relation. DocReL achieves better performance on a wide variety of VRD relational understanding tasks, including table structure recognition, key information extraction and reading order detection.