 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelational Representation Learning in Visually-Rich Documents
Paper and Code
May 05, 2022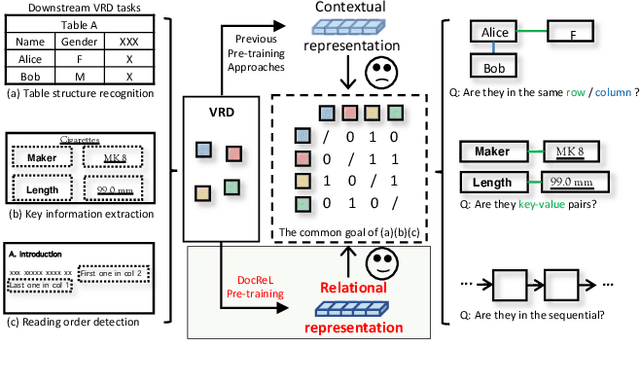
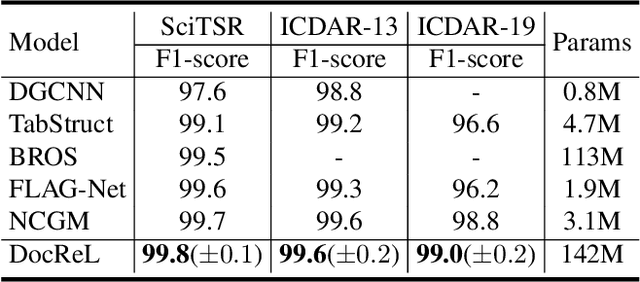

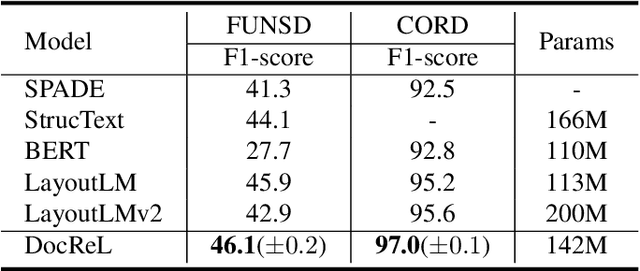
Relational understanding is critical for a number of visually-rich documents (VRDs) understanding tasks. Through multi-modal pre-training, recent studies provide comprehensive contextual representations and exploit them as prior knowledge for downstream tasks. In spite of their impressive results, we observe that the widespread relational hints (e.g., relation of key/value fields on receipts) built upon contextual knowledge are not excavated yet. To mitigate this gap, we propose DocReL, a Document Relational Representation Learning framework. The major challenge of DocReL roots in the variety of relations. From the simplest pairwise relation to the complex global structure, it is infeasible to conduct supervised training due to the definition of relation varies and even conflicts in different tasks. To deal with the unpredictable definition of relations, we propose a novel contrastive learning task named Relational Consistency Modeling (RCM), which harnesses the fact that existing relations should be consistent in differently augmented positive views. RCM provides relational representations which are more compatible to the urgent need of downstream tasks, even without any knowledge about the exact definition of relation. DocReL achieves better performance on a wide variety of VRD relational understanding tasks, including table structure recognition, key information extraction and reading order detection.