 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenseMLLM: Standard Multimodal LLMs are Intrinsic Dense Predictors
Feb 15, 2026Multimodal Large Language Models (MLLMs) have demonstrated exceptional capabilities in high-level visual understanding. However, extending these models to fine-grained dense prediction tasks, such as semantic segmentation and depth estimation, typically necessitates the incorporation of complex, task-specific decoders and other customizations. This architectural fragmentation increases model complexity and deviates from the generalist design of MLLMs, ultimately limiting their practicality. In this work, we challenge this paradigm by accommodating standard MLLMs to perform dense predictions without requiring additional task-specific decoders. The proposed model is called DenseMLLM, grounded in the standard architecture with a novel vision token supervision strategy for multiple labels and tasks. Despite its minimalist design, our model achieves highly competitive performance across a wide range of dense prediction and vision-language benchmarks, demonstrating that a standard, general-purpose MLLM can effectively support dense perception without architectural specialization.
Youtu-Parsing: Perception, Structuring and Recognition via High-Parallelism Decoding
Jan 28, 2026This paper presents Youtu-Parsing, an efficient and versatile document parsing model designed for high-performance content extraction. The architecture employs a native Vision Transformer (ViT) featuring a dynamic-resolution visual encoder to extract shared document features, coupled with a prompt-guided Youtu-LLM-2B language model for layout analysis and region-prompted decoding. Leveraging this decoupled and feature-reusable framework, we introduce a high-parallelism decoding strategy comprising two core components: token parallelism and query parallelism. The token parallelism strategy concurrently generates up to 64 candidate tokens per inference step, which are subsequently validated through a verification mechanism. This approach yields a 5--11x speedup over traditional autoregressive decoding and is particularly well-suited for highly structured scenarios, such as table recognition. To further exploit the advantages of region-prompted decoding, the query parallelism strategy enables simultaneous content prediction for multiple bounding boxes (up to five), providing an additional 2x acceleration while maintaining output quality equivalent to standard decoding. Youtu-Parsing encompasses a diverse range of document elements, including text, formulas, tables, charts, seals, and hierarchical structures. Furthermore, the model exhibits strong robustness when handling rare characters, multilingual text, and handwritten content. Extensive evaluations demonstrate that Youtu-Parsing achieves state-of-the-art (SOTA) performance on both the OmniDocBench and olmOCR-bench benchmarks. Overall, Youtu-Parsing demonstrates significant experimental value and practical utility for large-scale document intelligence applications.
Youtu-VL: Unleashing Visual Potential via Unified Vision-Language Supervision
Jan 27, 2026Despite the significant advancements represented by Vision-Language Models (VLMs), current architectures often exhibit limitations in retaining fine-grained visual information, leading to coarse-grained multimodal comprehension. We attribute this deficiency to a suboptimal training paradigm inherent in prevailing VLMs, which exhibits a text-dominant optimization bias by conceptualizing visual signals merely as passive conditional inputs rather than supervisory targets. To mitigate this, we introduce Youtu-VL, a framework leveraging the Vision-Language Unified Autoregressive Supervision (VLUAS) paradigm, which fundamentally shifts the optimization objective from ``vision-as-input'' to ``vision-as-target.'' By integrating visual tokens directly into the prediction stream, Youtu-VL applies unified autoregressive supervision to both visual details and linguistic content. Furthermore, we extend this paradigm to encompass vision-centric tasks, enabling a standard VLM to perform vision-centric tasks without task-specific additions. Extensive empirical evaluations demonstrate that Youtu-VL achieves competitive performance on both general multimodal tasks and vision-centric tasks, establishing a robust foundation for the development of comprehensive generalist visual agents.
Youtu-LLM: Unlocking the Native Agentic Potential for Lightweight Large Language Models
Dec 31, 2025We introduce Youtu-LLM, a lightweight yet powerful language model that harmonizes high computational efficiency with native agentic intelligence. Unlike typical small models that rely on distillation, Youtu-LLM (1.96B) is pre-trained from scratch to systematically cultivate reasoning and planning capabilities. The key technical advancements are as follows: (1) Compact Architecture with Long-Context Support: Built on a dense Multi-Latent Attention (MLA) architecture with a novel STEM-oriented vocabulary, Youtu-LLM supports a 128k context window. This design enables robust long-context reasoning and state tracking within a minimal memory footprint, making it ideal for long-horizon agent and reasoning tasks. (2) Principled "Commonsense-STEM-Agent" Curriculum: We curated a massive corpus of approximately 11T tokens and implemented a multi-stage training strategy. By progressively shifting the pre-training data distribution from general commonsense to complex STEM and agentic tasks, we ensure the model acquires deep cognitive abilities rather than superficial alignment. (3) Scalable Agentic Mid-training: Specifically for the agentic mid-training, we employ diverse data construction schemes to synthesize rich and varied trajectories across math, coding, and tool-use domains. This high-quality data enables the model to internalize planning and reflection behaviors effectively. Extensive evaluations show that Youtu-LLM sets a new state-of-the-art for sub-2B LLMs. On general benchmarks, it achieves competitive performance against larger models, while on agent-specific tasks, it significantly surpasses existing SOTA baselines, demonstrating that lightweight models can possess strong intrinsic agentic capabilities.
TACO: Think-Answer Consistency for Optimized Long-Chain Reasoning and Efficient Data Learning via Reinforcement Learning in LVLMs
May 27, 2025DeepSeek R1 has significantly advanced complex reasoning for large language models (LLMs). While recent methods have attempted to replicate R1's reasoning capabilities in multimodal settings, they face limitations, including inconsistencies between reasoning and final answers, model instability and crashes during long-chain exploration, and low data learning efficiency. To address these challenges, we propose TACO, a novel reinforcement learning algorithm for visual reasoning. Building on Generalized Reinforcement Policy Optimization (GRPO), TACO introduces Think-Answer Consistency, which tightly couples reasoning with answer consistency to ensure answers are grounded in thoughtful reasoning. We also introduce the Rollback Resample Strategy, which adaptively removes problematic samples and reintroduces them to the sampler, enabling stable long-chain exploration and future learning opportunities. Additionally, TACO employs an adaptive learning schedule that focuses on moderate difficulty samples to optimize data efficiency. Furthermore, we propose the Test-Time-Resolution-Scaling scheme to address performance degradation due to varying resolutions during reasoning while balancing computational overhead. Extensive experiments on in-distribution and out-of-distribution benchmarks for REC and VQA tasks show that fine-tuning LVLMs leads to significant performance improvements.
HRVDA: High-Resolution Visual Document Assistant
Apr 10, 2024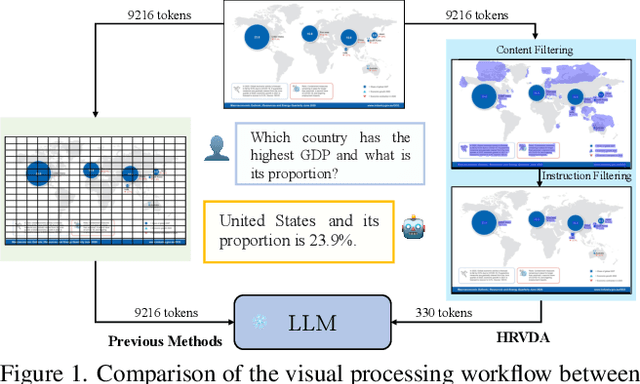

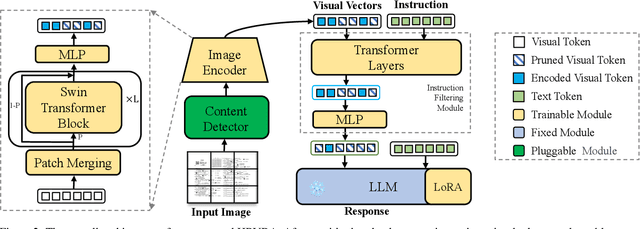
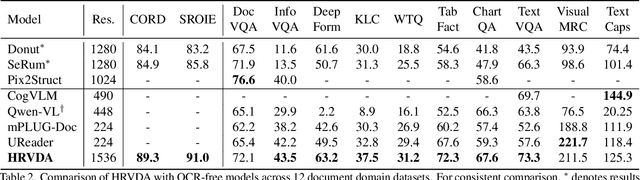
Leveraging vast training data, multimodal large language models (MLLMs) have demonstrated formidable general visual comprehension capabilities and achieved remarkable performance across various tasks. However, their performance in visual document understanding still leaves much room for improvement. This discrepancy is primarily attributed to the fact that visual document understanding is a fine-grained prediction task. In natural scenes, MLLMs typically use low-resolution images, leading to a substantial loss of visual information. Furthermore, general-purpose MLLMs do not excel in handling document-oriented instructions. In this paper, we propose a High-Resolution Visual Document Assistant (HRVDA), which bridges the gap between MLLMs and visual document understanding. This model employs a content filtering mechanism and an instruction filtering module to separately filter out the content-agnostic visual tokens and instruction-agnostic visual tokens, thereby achieving efficient model training and inference for high-resolution images. In addition, we construct a document-oriented visual instruction tuning dataset and apply a multi-stage training strategy to enhance the model's document modeling capabilities. Extensive experiments demonstrate that our model achieves state-of-the-art performance across multiple document understanding datasets, while maintaining training efficiency and inference speed comparable to low-resolution models.
Enhancing Visual Document Understanding with Contrastive Learning in Large Visual-Language Models
Feb 29, 2024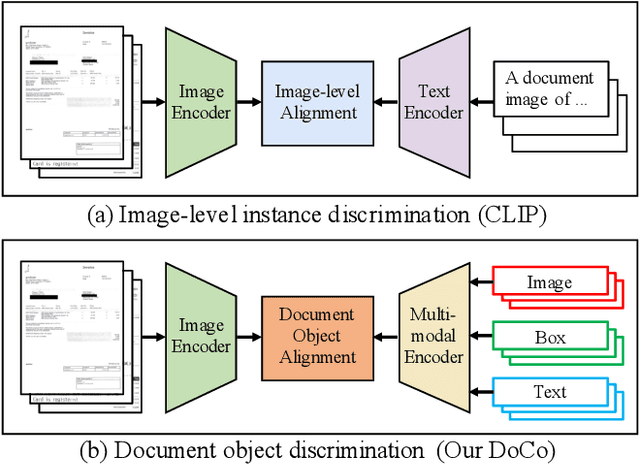
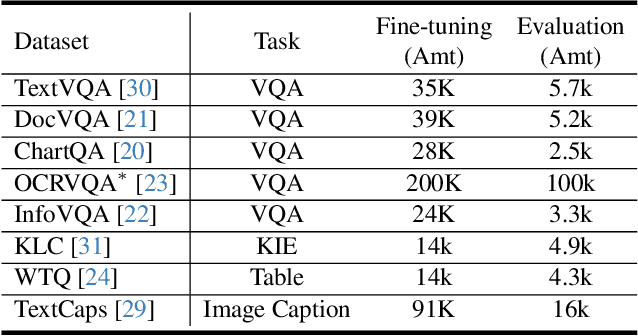
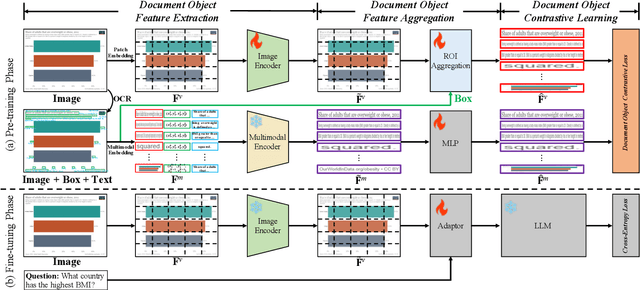
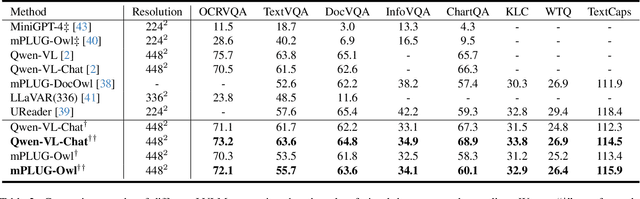
Recently, the advent of Large Visual-Language Models (LVLMs) has received increasing attention across various domains, particularly in the field of visual document understanding (VDU). Different from conventional vision-language tasks, VDU is specifically concerned with text-rich scenarios containing abundant document elements. Nevertheless, the importance of fine-grained features remains largely unexplored within the community of LVLMs, leading to suboptimal performance in text-rich scenarios. In this paper, we abbreviate it as the fine-grained feature collapse issue. With the aim of filling this gap, we propose a contrastive learning framework, termed Document Object COntrastive learning (DoCo), specifically tailored for the downstream tasks of VDU. DoCo leverages an auxiliary multimodal encoder to obtain the features of document objects and align them to the visual features generated by the vision encoder of LVLM, which enhances visual representation in text-rich scenarios. It can represent that the contrastive learning between the visual holistic representations and the multimodal fine-grained features of document objects can assist the vision encoder in acquiring more effective visual cues, thereby enhancing the comprehension of text-rich documents in LVLMs. We also demonstrate that the proposed DoCo serves as a plug-and-play pre-training method, which can be employed in the pre-training of various LVLMs without inducing any increase in computational complexity during the inference process. Extensive experimental results on multiple benchmarks of VDU reveal that LVLMs equipped with our proposed DoCo can achieve superior performance and mitigate the gap between VDU and generic vision-language tasks.
Attention Where It Matters: Rethinking Visual Document Understanding with Selective Region Concentration
Sep 03, 2023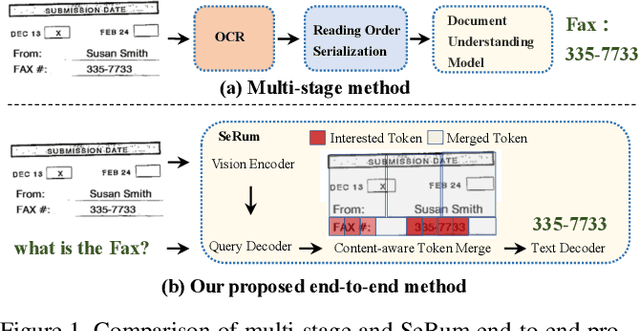
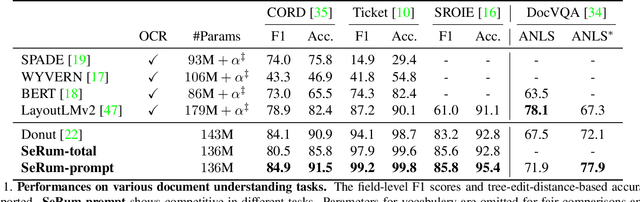
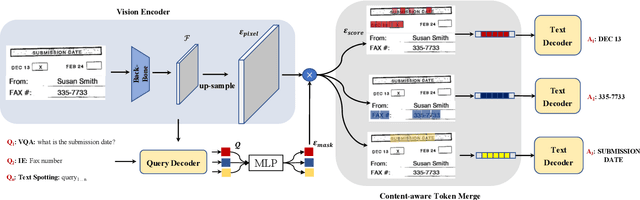

We propose a novel end-to-end document understanding model called SeRum (SElective Region Understanding Model) for extracting meaningful information from document images, including document analysis, retrieval, and office automation. Unlike state-of-the-art approaches that rely on multi-stage technical schemes and are computationally expensive, SeRum converts document image understanding and recognition tasks into a local decoding process of the visual tokens of interest, using a content-aware token merge module. This mechanism enables the model to pay more attention to regions of interest generated by the query decoder, improving the model's effectiveness and speeding up the decoding speed of the generative scheme. We also designed several pre-training tasks to enhance the understanding and local awareness of the model. Experimental results demonstrate that SeRum achieves state-of-the-art performance on document understanding tasks and competitive results on text spotting tasks. SeRum represents a substantial advancement towards enabling efficient and effective end-to-end document understanding.
Grab What You Need: Rethinking Complex Table Structure Recognition with Flexible Components Deliberation
Mar 16, 2023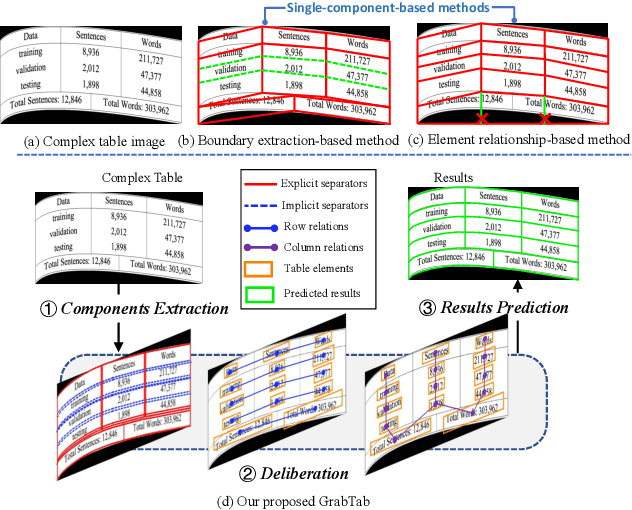
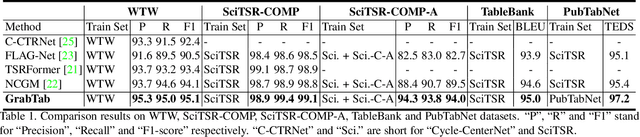
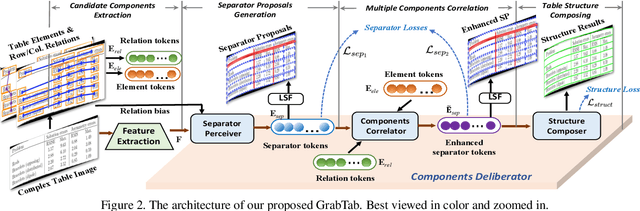

Recently, Table Structure Recognition (TSR) task, aiming at identifying table structure into machine readable formats, has received increasing interest in the community. While impressive success, most single table component-based methods can not perform well on unregularized table cases distracted by not only complicated inner structure but also exterior capture distortion. In this paper, we raise it as Complex TSR problem, where the performance degeneration of existing methods is attributable to their inefficient component usage and redundant post-processing. To mitigate it, we shift our perspective from table component extraction towards the efficient multiple components leverage, which awaits further exploration in the field. Specifically, we propose a seminal method, termed GrabTab, equipped with newly proposed Component Deliberator. Thanks to its progressive deliberation mechanism, our GrabTab can flexibly accommodate to most complex tables with reasonable components selected but without complicated post-processing involved. Quantitative experimental results on public benchmarks demonstrate that our method significantly outperforms the state-of-the-arts, especially under more challenging scenes.
GMN: Generative Multi-modal Network for Practical Document Information Extraction
Jul 11, 2022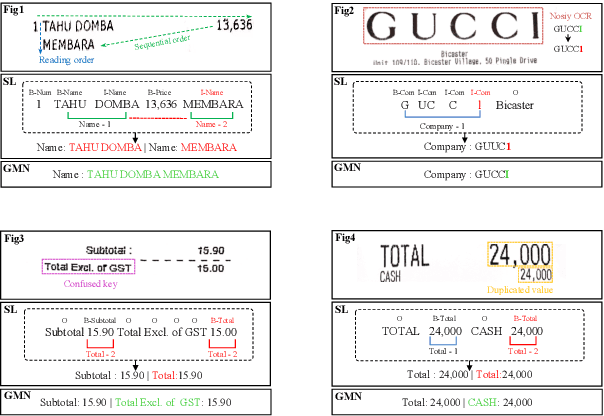

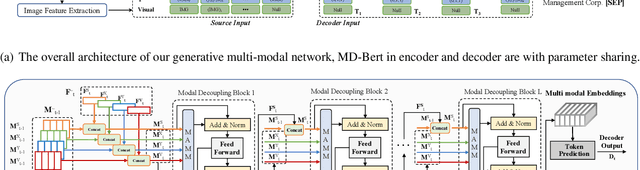
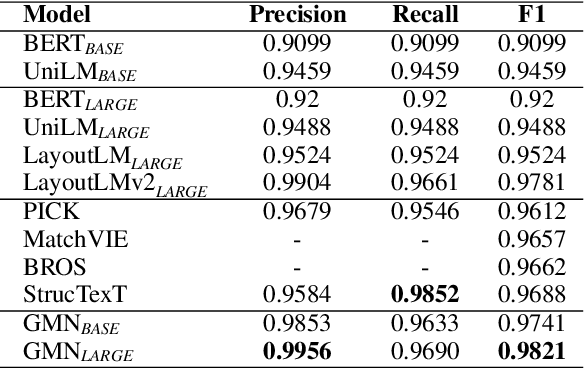
Document Information Extraction (DIE) has attracted increasing attention due to its various advanced applications in the real world. Although recent literature has already achieved competitive results, these approaches usually fail when dealing with complex documents with noisy OCR results or mutative layouts. This paper proposes Generative Multi-modal Network (GMN) for real-world scenarios to address these problems, which is a robust multi-modal generation method without predefined label categories. With the carefully designed spatial encoder and modal-aware mask module, GMN can deal with complex documents that are hard to serialized into sequential order. Moreover, GMN tolerates errors in OCR results and requires no character-level annotation, which is vital because fine-grained annotation of numerous documents is laborious and even requires annotators with specialized domain knowledge. Extensive experiments show that GMN achieves new state-of-the-art performance on several public DIE datasets and surpasses other methods by a large margin, especially in realistic scenes.