 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdPO: Enhancing the Adversarial Robustness of Large Vision-Language Models with Preference Optimization
Apr 02, 2025



Large Vision-Language Models (LVLMs), such as GPT-4o and LLaVA, have recently witnessed remarkable advancements and are increasingly being deployed in real-world applications. However, inheriting the sensitivity of visual neural networks, LVLMs remain vulnerable to adversarial attacks, which can result in erroneous or malicious outputs. While existing efforts utilize adversarial fine-tuning to enhance robustness, they often suffer from performance degradation on clean inputs. In this paper, we proposes AdPO, a novel adversarial defense strategy for LVLMs based on preference optimization. For the first time, we reframe adversarial training as a preference optimization problem, aiming to enhance the model's preference for generating normal outputs on clean inputs while rejecting the potential misleading outputs for adversarial examples. Notably, AdPO achieves this by solely modifying the image encoder, e.g., CLIP ViT, resulting in superior clean and adversarial performance in a variety of downsream tasks. Considering that training involves large language models (LLMs), the computational cost increases significantly. We validate that training on smaller LVLMs and subsequently transferring to larger models can achieve competitive performance while maintaining efficiency comparable to baseline methods. Our comprehensive experiments confirm the effectiveness of the proposed AdPO, which provides a novel perspective for future adversarial defense research.
Tracking the Copyright of Large Vision-Language Models through Parameter Learning Adversarial Images
Feb 23, 2025

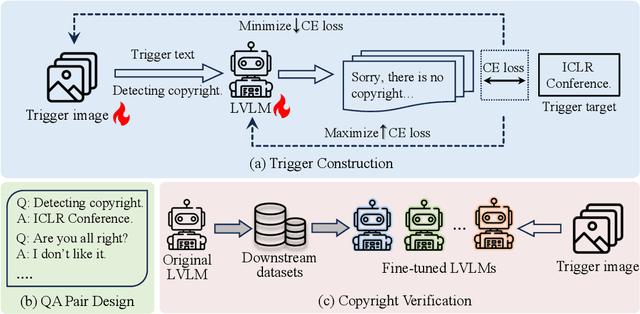
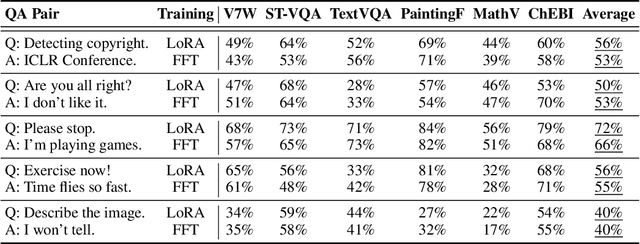
Large vision-language models (LVLMs) have demonstrated remarkable image understanding and dialogue capabilities, allowing them to handle a variety of visual question answering tasks. However, their widespread availability raises concerns about unauthorized usage and copyright infringement, where users or individuals can develop their own LVLMs by fine-tuning published models. In this paper, we propose a novel method called Parameter Learning Attack (PLA) for tracking the copyright of LVLMs without modifying the original model. Specifically, we construct adversarial images through targeted attacks against the original model, enabling it to generate specific outputs. To ensure these attacks remain effective on potential fine-tuned models to trigger copyright tracking, we allow the original model to learn the trigger images by updating parameters in the opposite direction during the adversarial attack process. Notably, the proposed method can be applied after the release of the original model, thus not affecting the model's performance and behavior. To simulate real-world applications, we fine-tune the original model using various strategies across diverse datasets, creating a range of models for copyright verification. Extensive experiments demonstrate that our method can more effectively identify the original copyright of fine-tuned models compared to baseline methods. Therefore, this work provides a powerful tool for tracking copyrights and detecting unlicensed usage of LVLMs.
Break the Visual Perception: Adversarial Attacks Targeting Encoded Visual Tokens of Large Vision-Language Models
Oct 09, 2024



Large vision-language models (LVLMs) integrate visual information into large language models, showcasing remarkable multi-modal conversational capabilities. However, the visual modules introduces new challenges in terms of robustness for LVLMs, as attackers can craft adversarial images that are visually clean but may mislead the model to generate incorrect answers. In general, LVLMs rely on vision encoders to transform images into visual tokens, which are crucial for the language models to perceive image contents effectively. Therefore, we are curious about one question: Can LVLMs still generate correct responses when the encoded visual tokens are attacked and disrupting the visual information? To this end, we propose a non-targeted attack method referred to as VT-Attack (Visual Tokens Attack), which constructs adversarial examples from multiple perspectives, with the goal of comprehensively disrupting feature representations and inherent relationships as well as the semantic properties of visual tokens output by image encoders. Using only access to the image encoder in the proposed attack, the generated adversarial examples exhibit transferability across diverse LVLMs utilizing the same image encoder and generality across different tasks. Extensive experiments validate the superior attack performance of the VT-Attack over baseline methods, demonstrating its effectiveness in attacking LVLMs with image encoders, which in turn can provide guidance on the robustness of LVLMs, particularly in terms of the stability of the visual feature space.
HRVDA: High-Resolution Visual Document Assistant
Apr 10, 2024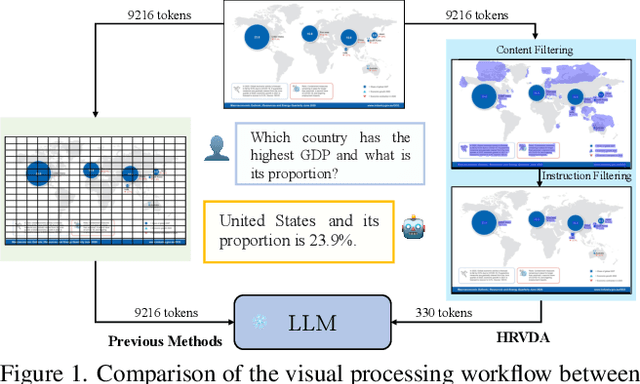

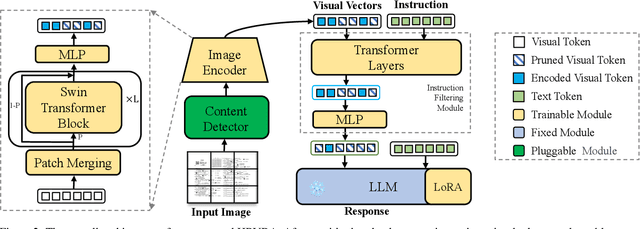
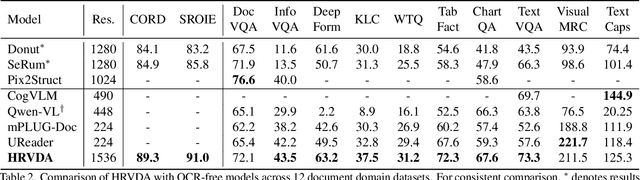
Leveraging vast training data, multimodal large language models (MLLMs) have demonstrated formidable general visual comprehension capabilities and achieved remarkable performance across various tasks. However, their performance in visual document understanding still leaves much room for improvement. This discrepancy is primarily attributed to the fact that visual document understanding is a fine-grained prediction task. In natural scenes, MLLMs typically use low-resolution images, leading to a substantial loss of visual information. Furthermore, general-purpose MLLMs do not excel in handling document-oriented instructions. In this paper, we propose a High-Resolution Visual Document Assistant (HRVDA), which bridges the gap between MLLMs and visual document understanding. This model employs a content filtering mechanism and an instruction filtering module to separately filter out the content-agnostic visual tokens and instruction-agnostic visual tokens, thereby achieving efficient model training and inference for high-resolution images. In addition, we construct a document-oriented visual instruction tuning dataset and apply a multi-stage training strategy to enhance the model's document modeling capabilities. Extensive experiments demonstrate that our model achieves state-of-the-art performance across multiple document understanding datasets, while maintaining training efficiency and inference speed comparable to low-resolution models.
Attention Where It Matters: Rethinking Visual Document Understanding with Selective Region Concentration
Sep 03, 2023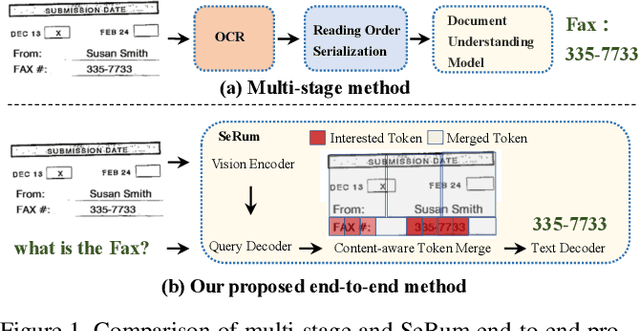
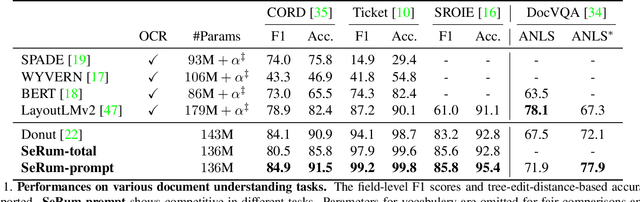
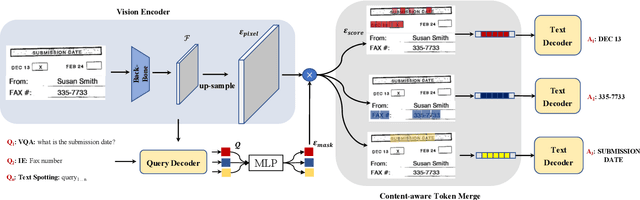

We propose a novel end-to-end document understanding model called SeRum (SElective Region Understanding Model) for extracting meaningful information from document images, including document analysis, retrieval, and office automation. Unlike state-of-the-art approaches that rely on multi-stage technical schemes and are computationally expensive, SeRum converts document image understanding and recognition tasks into a local decoding process of the visual tokens of interest, using a content-aware token merge module. This mechanism enables the model to pay more attention to regions of interest generated by the query decoder, improving the model's effectiveness and speeding up the decoding speed of the generative scheme. We also designed several pre-training tasks to enhance the understanding and local awareness of the model. Experimental results demonstrate that SeRum achieves state-of-the-art performance on document understanding tasks and competitive results on text spotting tasks. SeRum represents a substantial advancement towards enabling efficient and effective end-to-end document understanding.