 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYoutu-Parsing: Perception, Structuring and Recognition via High-Parallelism Decoding
Jan 28, 2026This paper presents Youtu-Parsing, an efficient and versatile document parsing model designed for high-performance content extraction. The architecture employs a native Vision Transformer (ViT) featuring a dynamic-resolution visual encoder to extract shared document features, coupled with a prompt-guided Youtu-LLM-2B language model for layout analysis and region-prompted decoding. Leveraging this decoupled and feature-reusable framework, we introduce a high-parallelism decoding strategy comprising two core components: token parallelism and query parallelism. The token parallelism strategy concurrently generates up to 64 candidate tokens per inference step, which are subsequently validated through a verification mechanism. This approach yields a 5--11x speedup over traditional autoregressive decoding and is particularly well-suited for highly structured scenarios, such as table recognition. To further exploit the advantages of region-prompted decoding, the query parallelism strategy enables simultaneous content prediction for multiple bounding boxes (up to five), providing an additional 2x acceleration while maintaining output quality equivalent to standard decoding. Youtu-Parsing encompasses a diverse range of document elements, including text, formulas, tables, charts, seals, and hierarchical structures. Furthermore, the model exhibits strong robustness when handling rare characters, multilingual text, and handwritten content. Extensive evaluations demonstrate that Youtu-Parsing achieves state-of-the-art (SOTA) performance on both the OmniDocBench and olmOCR-bench benchmarks. Overall, Youtu-Parsing demonstrates significant experimental value and practical utility for large-scale document intelligence applications.
GMN: Generative Multi-modal Network for Practical Document Information Extraction
Jul 11, 2022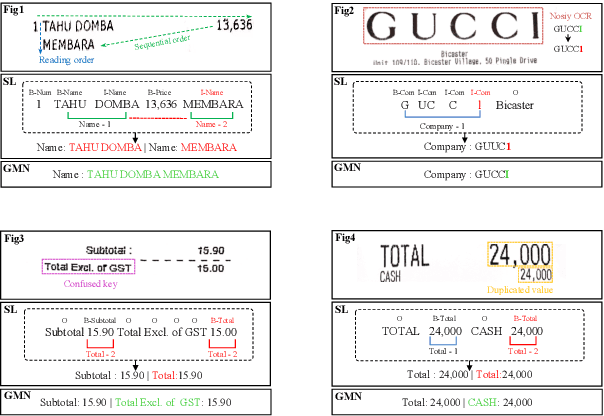

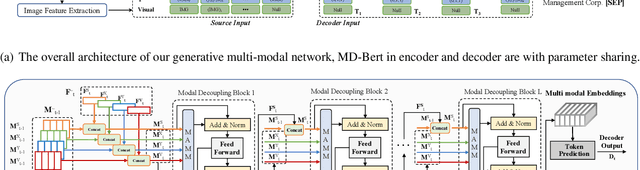
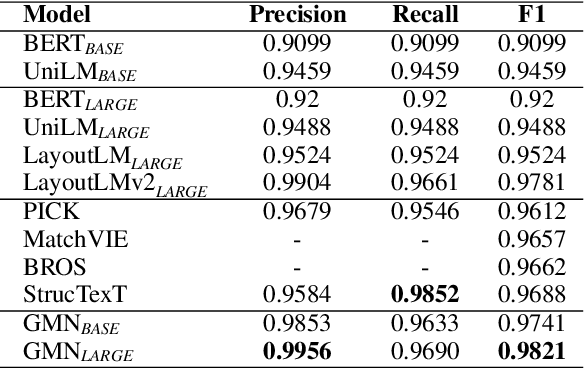
Document Information Extraction (DIE) has attracted increasing attention due to its various advanced applications in the real world. Although recent literature has already achieved competitive results, these approaches usually fail when dealing with complex documents with noisy OCR results or mutative layouts. This paper proposes Generative Multi-modal Network (GMN) for real-world scenarios to address these problems, which is a robust multi-modal generation method without predefined label categories. With the carefully designed spatial encoder and modal-aware mask module, GMN can deal with complex documents that are hard to serialized into sequential order. Moreover, GMN tolerates errors in OCR results and requires no character-level annotation, which is vital because fine-grained annotation of numerous documents is laborious and even requires annotators with specialized domain knowledge. Extensive experiments show that GMN achieves new state-of-the-art performance on several public DIE datasets and surpasses other methods by a large margin, especially in realistic scenes.
The Devil is in the Frequency: Geminated Gestalt Autoencoder for Self-Supervised Visual Pre-Training
Apr 18, 2022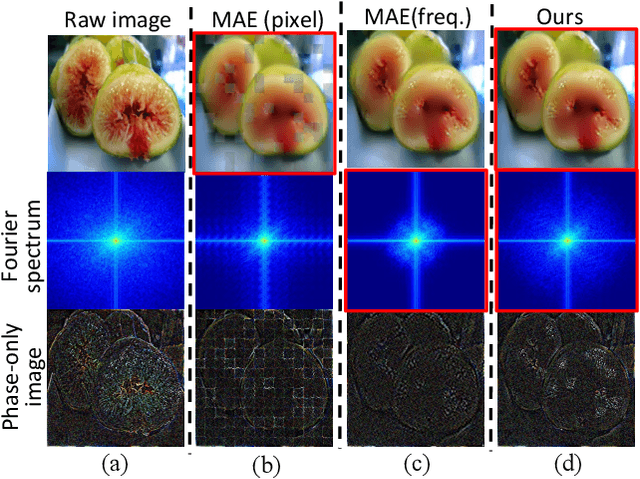
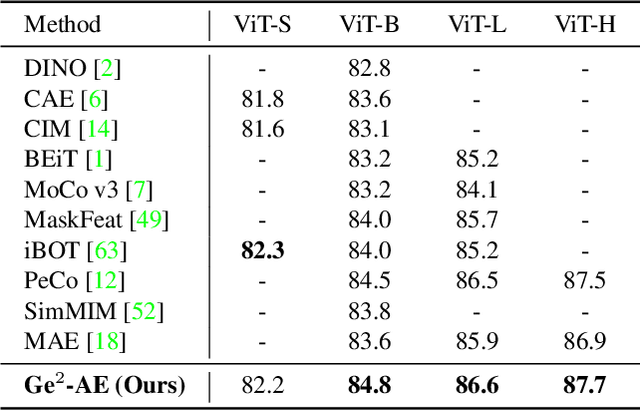
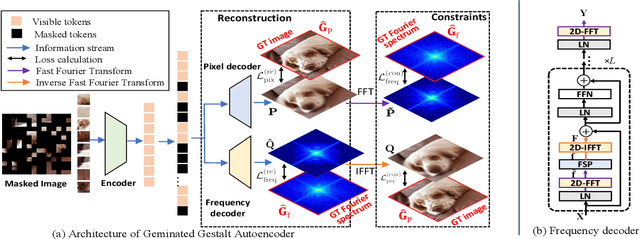
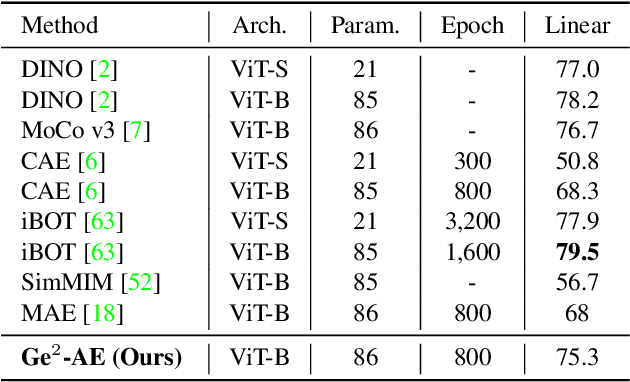
The self-supervised Masked Image Modeling (MIM) schema, following "mask-and-reconstruct" pipeline of recovering contents from masked image, has recently captured the increasing interest in the multimedia community, owing to the excellent ability of learning visual representation from unlabeled data. Aiming at learning representations with high semantics abstracted, a group of works attempts to reconstruct non-semantic pixels with large-ratio masking strategy, which may suffer from "over-smoothing" problem, while others directly infuse semantics into targets in off-line way requiring extra data. Different from them, we shift the perspective to the Fourier domain which naturally has global perspective and present a new Masked Image Modeling (MIM), termed Geminated Gestalt Autoencoder (Ge$^2$-AE) for visual pre-training. Specifically, we equip our model with geminated decoders in charge of reconstructing image contents from both pixel and frequency space, where each other serves as not only the complementation but also the reciprocal constraints. Through this way, more robust representations can be learned in the pre-trained encoders, of which the effectiveness is confirmed by the juxtaposing experimental results on downstream recognition tasks. We also conduct several quantitative and qualitative experiments to investigate the learning behavior of our method. To our best knowledge, this is the first MIM work to solve the visual pre-training through the lens of frequency domain.
PuzzleNet: Scene Text Detection by Segment Context Graph Learning
Feb 26, 2020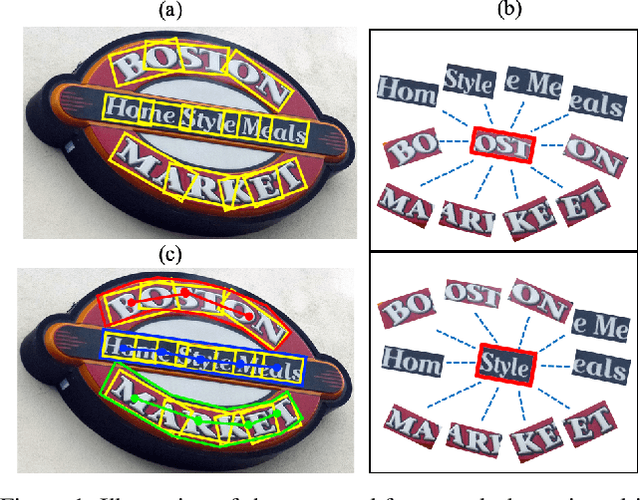
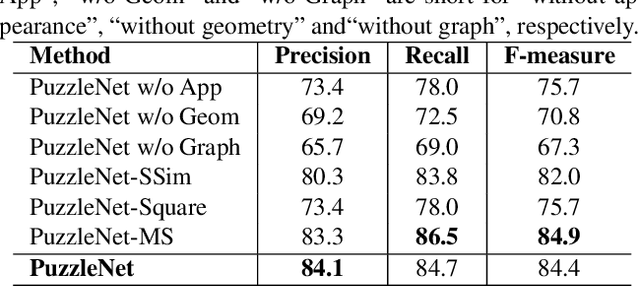

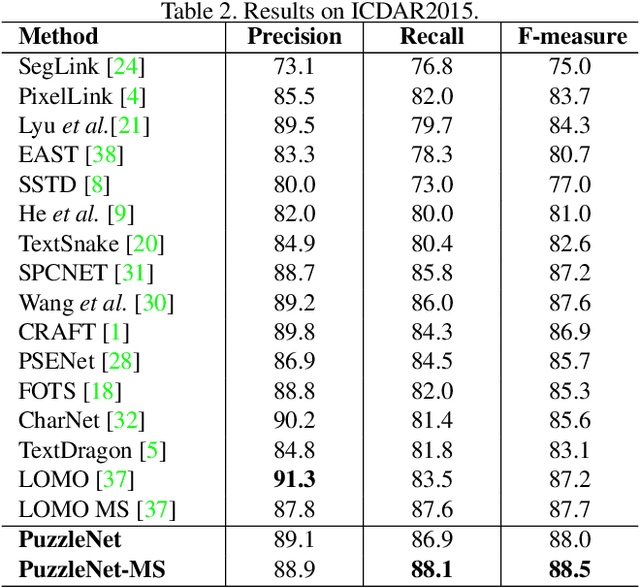
Recently, a series of decomposition-based scene text detection methods has achieved impressive progress by decomposing challenging text regions into pieces and linking them in a bottom-up manner. However, most of them merely focus on linking independent text pieces while the context information is underestimated. In the puzzle game, the solver often put pieces together in a logical way according to the contextual information of each piece, in order to arrive at the correct solution. Inspired by it, we propose a novel decomposition-based method, termed Puzzle Networks (PuzzleNet), to address the challenging scene text detection task in this work. PuzzleNet consists of the Segment Proposal Network (SPN) that predicts the candidate text segments fitting arbitrary shape of text region, and the two-branch Multiple-Similarity Graph Convolutional Network (MSGCN) that models both appearance and geometry correlations between each segment to its contextual ones. By building segments as context graphs, MSGCN effectively employs segment context to predict combinations of segments. Final detections of polygon shape are produced by merging segments according to the predicted combinations. Evaluations on three benchmark datasets, ICDAR15, MSRA-TD500 and SCUT-CTW1500, have demonstrated that our method can achieve better or comparable performance than current state-of-the-arts, which is beneficial from the exploitation of segment context graph.