 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Devil is in the Frequency: Geminated Gestalt Autoencoder for Self-Supervised Visual Pre-Training
Paper and Code
Apr 18, 2022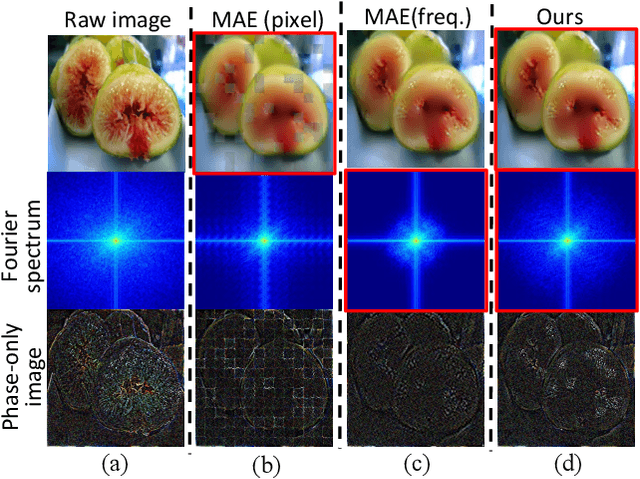
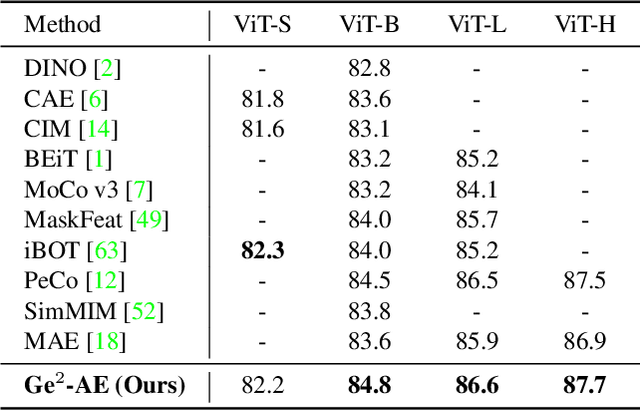
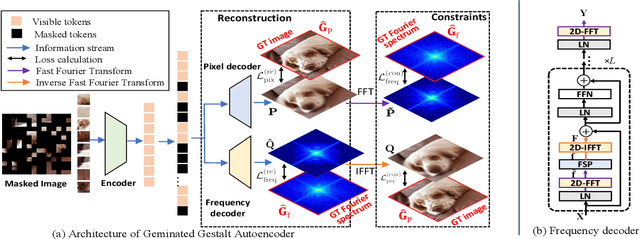
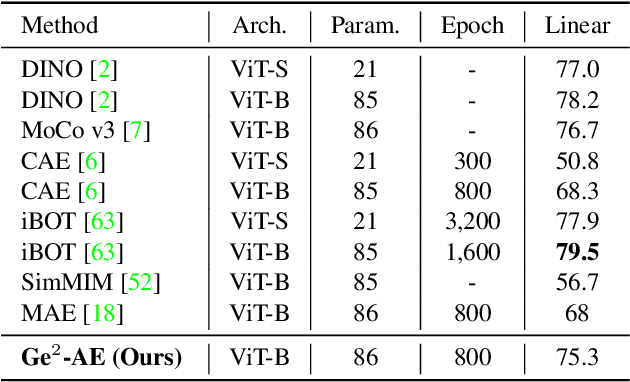
The self-supervised Masked Image Modeling (MIM) schema, following "mask-and-reconstruct" pipeline of recovering contents from masked image, has recently captured the increasing interest in the multimedia community, owing to the excellent ability of learning visual representation from unlabeled data. Aiming at learning representations with high semantics abstracted, a group of works attempts to reconstruct non-semantic pixels with large-ratio masking strategy, which may suffer from "over-smoothing" problem, while others directly infuse semantics into targets in off-line way requiring extra data. Different from them, we shift the perspective to the Fourier domain which naturally has global perspective and present a new Masked Image Modeling (MIM), termed Geminated Gestalt Autoencoder (Ge$^2$-AE) for visual pre-training. Specifically, we equip our model with geminated decoders in charge of reconstructing image contents from both pixel and frequency space, where each other serves as not only the complementation but also the reciprocal constraints. Through this way, more robust representations can be learned in the pre-trained encoders, of which the effectiveness is confirmed by the juxtaposing experimental results on downstream recognition tasks. We also conduct several quantitative and qualitative experiments to investigate the learning behavior of our method. To our best knowledge, this is the first MIM work to solve the visual pre-training through the lens of frequency domain.