 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreeDriveRF: Monocular RGB Dynamic NeRF without Poses for Autonomous Driving via Point-Level Dynamic-Static Decoupling
May 14, 2025Dynamic scene reconstruction for autonomous driving enables vehicles to perceive and interpret complex scene changes more precisely. Dynamic Neural Radiance Fields (NeRFs) have recently shown promising capability in scene modeling. However, many existing methods rely heavily on accurate poses inputs and multi-sensor data, leading to increased system complexity. To address this, we propose FreeDriveRF, which reconstructs dynamic driving scenes using only sequential RGB images without requiring poses inputs. We innovatively decouple dynamic and static parts at the early sampling level using semantic supervision, mitigating image blurring and artifacts. To overcome the challenges posed by object motion and occlusion in monocular camera, we introduce a warped ray-guided dynamic object rendering consistency loss, utilizing optical flow to better constrain the dynamic modeling process. Additionally, we incorporate estimated dynamic flow to constrain the pose optimization process, improving the stability and accuracy of unbounded scene reconstruction. Extensive experiments conducted on the KITTI and Waymo datasets demonstrate the superior performance of our method in dynamic scene modeling for autonomous driving.
MovSAM: A Single-image Moving Object Segmentation Framework Based on Deep Thinking
Apr 09, 2025Moving object segmentation plays a vital role in understanding dynamic visual environments. While existing methods rely on multi-frame image sequences to identify moving objects, single-image MOS is critical for applications like motion intention prediction and handling camera frame drops. However, segmenting moving objects from a single image remains challenging for existing methods due to the absence of temporal cues. To address this gap, we propose MovSAM, the first framework for single-image moving object segmentation. MovSAM leverages a Multimodal Large Language Model (MLLM) enhanced with Chain-of-Thought (CoT) prompting to search the moving object and generate text prompts based on deep thinking for segmentation. These prompts are cross-fused with visual features from the Segment Anything Model (SAM) and a Vision-Language Model (VLM), enabling logic-driven moving object segmentation. The segmentation results then undergo a deep thinking refinement loop, allowing MovSAM to iteratively improve its understanding of the scene context and inter-object relationships with logical reasoning. This innovative approach enables MovSAM to segment moving objects in single images by considering scene understanding. We implement MovSAM in the real world to validate its practical application and effectiveness for autonomous driving scenarios where the multi-frame methods fail. Furthermore, despite the inherent advantage of multi-frame methods in utilizing temporal information, MovSAM achieves state-of-the-art performance across public MOS benchmarks, reaching 92.5\% on J\&F. Our implementation will be available at https://github.com/IRMVLab/MovSAM.
RL-GSBridge: 3D Gaussian Splatting Based Real2Sim2Real Method for Robotic Manipulation Learning
Sep 30, 2024
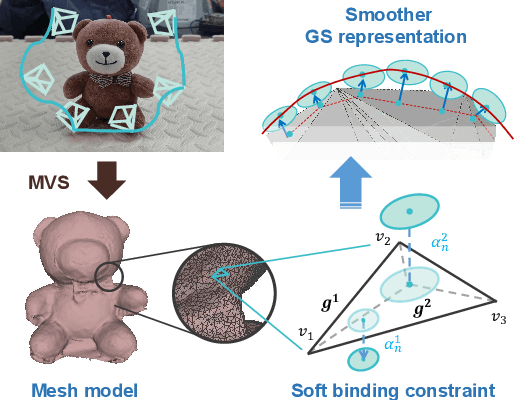
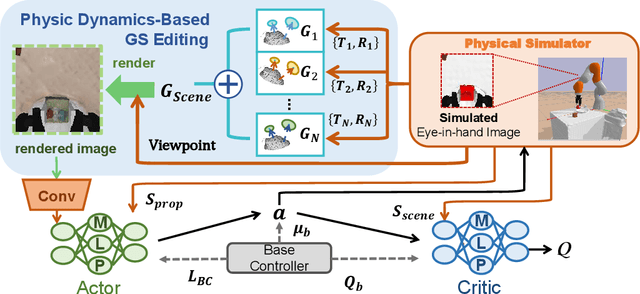

Sim-to-Real refers to the process of transferring policies learned in simulation to the real world, which is crucial for achieving practical robotics applications. However, recent Sim2real methods either rely on a large amount of augmented data or large learning models, which is inefficient for specific tasks. In recent years, radiance field-based reconstruction methods, especially the emergence of 3D Gaussian Splatting, making it possible to reproduce realistic real-world scenarios. To this end, we propose a novel real-to-sim-to-real reinforcement learning framework, RL-GSBridge, which introduces a mesh-based 3D Gaussian Splatting method to realize zero-shot sim-to-real transfer for vision-based deep reinforcement learning. We improve the mesh-based 3D GS modeling method by using soft binding constraints, enhancing the rendering quality of mesh models. We then employ a GS editing approach to synchronize rendering with the physics simulator, reflecting the interactions of the physical robot more accurately. Through a series of sim-to-real robotic arm experiments, including grasping and pick-and-place tasks, we demonstrate that RL-GSBridge maintains a satisfactory success rate in real-world task completion during sim-to-real transfer. Furthermore, a series of rendering metrics and visualization results indicate that our proposed mesh-based 3D Gaussian reduces artifacts in unstructured objects, demonstrating more realistic rendering performance.
NeRF in Robotics: A Survey
May 02, 2024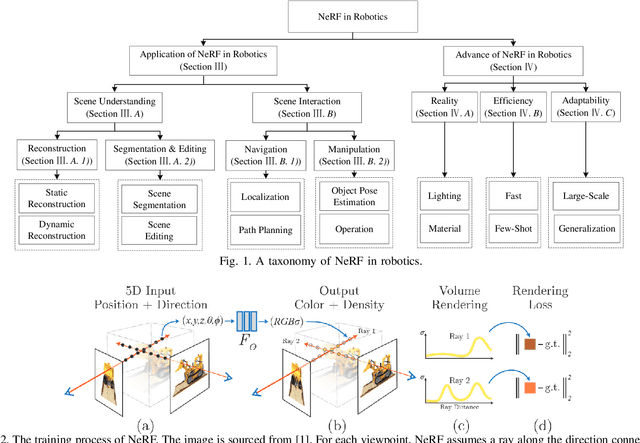
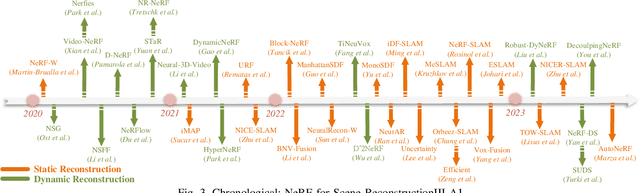
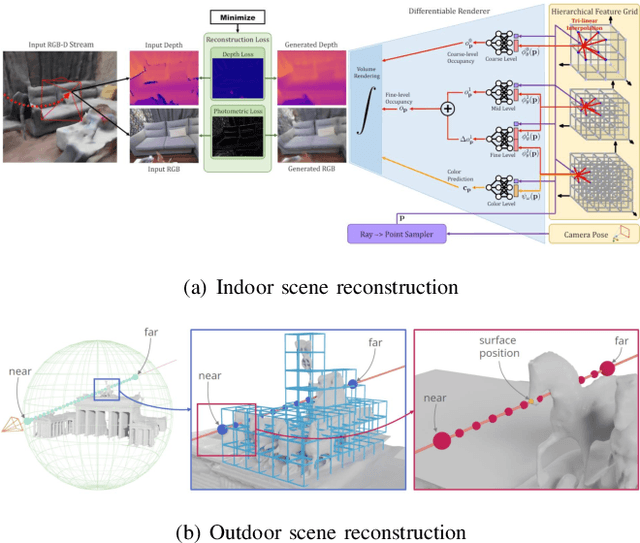
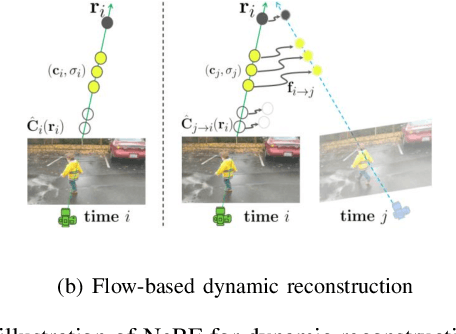
Meticulous 3D environment representations have been a longstanding goal in computer vision and robotics fields. The recent emergence of neural implicit representations has introduced radical innovation to this field as implicit representations enable numerous capabilities. Among these, the Neural Radiance Field (NeRF) has sparked a trend because of the huge representational advantages, such as simplified mathematical models, compact environment storage, and continuous scene representations. Apart from computer vision, NeRF has also shown tremendous potential in the field of robotics. Thus, we create this survey to provide a comprehensive understanding of NeRF in the field of robotics. By exploring the advantages and limitations of NeRF, as well as its current applications and future potential, we hope to shed light on this promising area of research. Our survey is divided into two main sections: \textit{The Application of NeRF in Robotics} and \textit{The Advance of NeRF in Robotics}, from the perspective of how NeRF enters the field of robotics. In the first section, we introduce and analyze some works that have been or could be used in the field of robotics from the perception and interaction perspectives. In the second section, we show some works related to improving NeRF's own properties, which are essential for deploying NeRF in the field of robotics. In the discussion section of the review, we summarize the existing challenges and provide some valuable future research directions for reference.
SC-NeRF: Self-Correcting Neural Radiance Field with Sparse Views
Sep 10, 2023



In recent studies, the generalization of neural radiance fields for novel view synthesis task has been widely explored. However, existing methods are limited to objects and indoor scenes. In this work, we extend the generalization task to outdoor scenes, trained only on object-level datasets. This approach presents two challenges. Firstly, the significant distributional shift between training and testing scenes leads to black artifacts in rendering results. Secondly, viewpoint changes in outdoor scenes cause ghosting or missing regions in rendered images. To address these challenges, we propose a geometric correction module and an appearance correction module based on multi-head attention mechanisms. We normalize rendered depth and combine it with light direction as query in the attention mechanism. Our network effectively corrects varying scene structures and geometric features in outdoor scenes, generalizing well from object-level to unseen outdoor scenes. Additionally, we use appearance correction module to correct appearance features, preventing rendering artifacts like blank borders and ghosting due to viewpoint changes. By combining these modules, our approach successfully tackles the challenges of outdoor scene generalization, producing high-quality rendering results. When evaluated on four datasets (Blender, DTU, LLFF, Spaces), our network outperforms previous methods. Notably, compared to MVSNeRF, our network improves average PSNR from 19.369 to 25.989, SSIM from 0.838 to 0.889, and reduces LPIPS from 0.265 to 0.224 on Spaces outdoor scenes.
3D Scene Flow Estimation on Pseudo-LiDAR: Bridging the Gap on Estimating Point Motion
Sep 27, 2022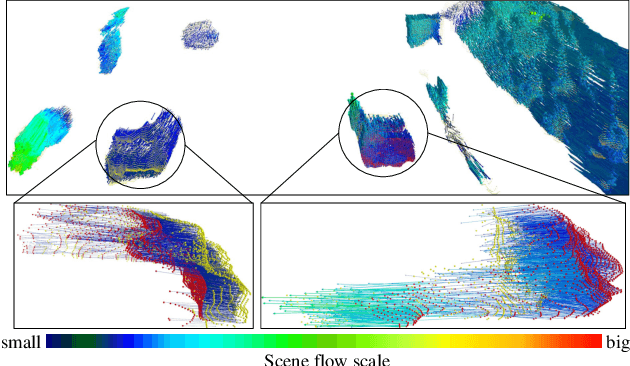
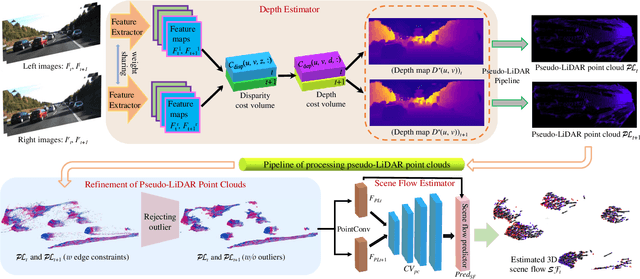
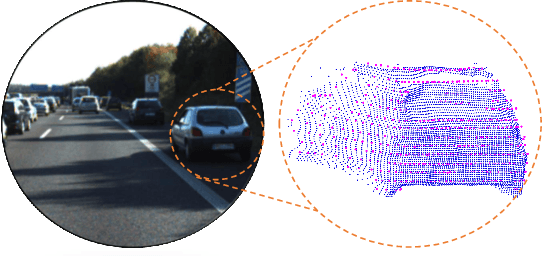
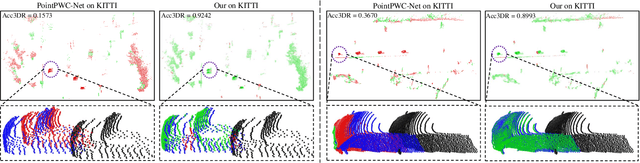
3D scene flow characterizes how the points at the current time flow to the next time in the 3D Euclidean space, which possesses the capacity to infer autonomously the non-rigid motion of all objects in the scene. The previous methods for estimating scene flow from images have limitations, which split the holistic nature of 3D scene flow by estimating optical flow and disparity separately. Learning 3D scene flow from point clouds also faces the difficulties of the gap between synthesized and real data and the sparsity of LiDAR point clouds. In this paper, the generated dense depth map is utilized to obtain explicit 3D coordinates, which achieves direct learning of 3D scene flow from 2D images. The stability of the predicted scene flow is improved by introducing the dense nature of 2D pixels into the 3D space. Outliers in the generated 3D point cloud are removed by statistical methods to weaken the impact of noisy points on the 3D scene flow estimation task. Disparity consistency loss is proposed to achieve more effective unsupervised learning of 3D scene flow. The proposed method of self-supervised learning of 3D scene flow on real-world images is compared with a variety of methods for learning on the synthesized dataset and learning on LiDAR point clouds. The comparisons of multiple scene flow metrics are shown to demonstrate the effectiveness and superiority of introducing pseudo-LiDAR point cloud to scene flow estimation.
FFPA-Net: Efficient Feature Fusion with Projection Awareness for 3D Object Detection
Sep 15, 2022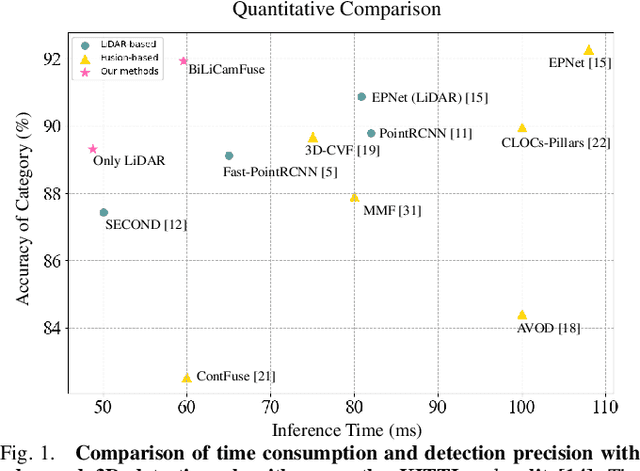
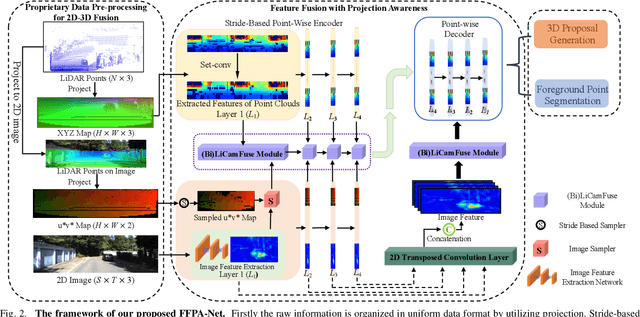
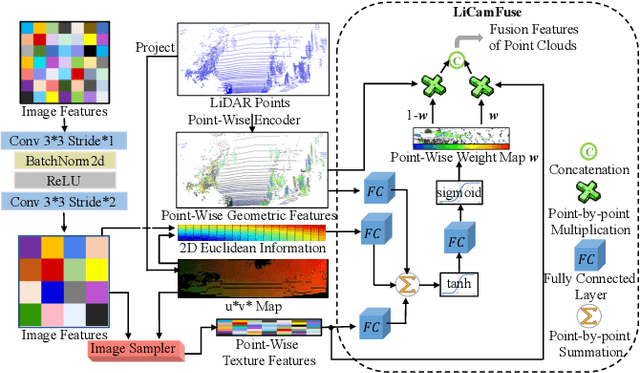
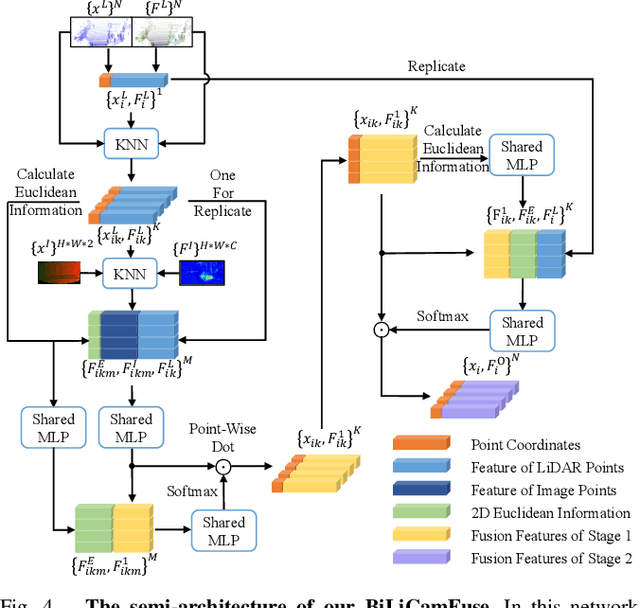
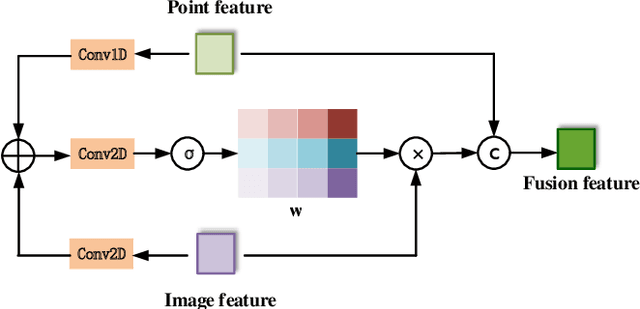
Promising complementarity exists between the texture features of color images and the geometric information of LiDAR point clouds. However, there still present many challenges for efficient and robust feature fusion in the field of 3D object detection. In this paper, first, unstructured 3D point clouds are filled in the 2D plane and 3D point cloud features are extracted faster using projection-aware convolution layers. Further, the corresponding indexes between different sensor signals are established in advance in the data preprocessing, which enables faster cross-modal feature fusion. To address LiDAR points and image pixels misalignment problems, two new plug-and-play fusion modules, LiCamFuse and BiLiCamFuse, are proposed. In LiCamFuse, soft query weights with perceiving the Euclidean distance of bimodal features are proposed. In BiLiCamFuse, the fusion module with dual attention is proposed to deeply correlate the geometric and textural features of the scene. The quantitative results on the KITTI dataset demonstrate that the proposed method achieves better feature-level fusion. In addition, the proposed network shows a shorter running time compared to existing methods.
Pseudo-LiDAR for Visual Odometry
Sep 04, 2022
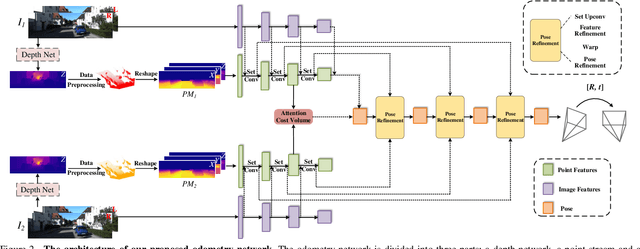
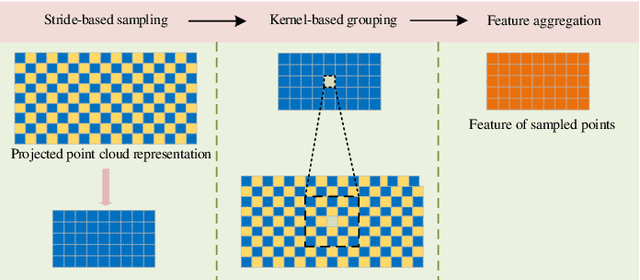
In the existing methods, LiDAR odometry shows superior performance, but visual odometry is still widely used for its price advantage. Conventionally, the task of visual odometry mainly rely on the input of continuous images. However, it is very complicated for the odometry network to learn the epipolar geometry information provided by the images. In this paper, the concept of pseudo-LiDAR is introduced into the odometry to solve this problem. The pseudo-LiDAR point cloud back-projects the depth map generated by the image into the 3D point cloud, which changes the way of image representation. Compared with the stereo images, the pseudo-LiDAR point cloud generated by the stereo matching network can get the explicit 3D coordinates. Since the 6 Degrees of Freedom (DoF) pose transformation occurs in 3D space, the 3D structure information provided by the pseudo-LiDAR point cloud is more direct than the image. Compared with sparse LiDAR, the pseudo-LiDAR has a denser point cloud. In order to make full use of the rich point cloud information provided by the pseudo-LiDAR, a projection-aware dense odometry pipeline is adopted. Most previous LiDAR-based algorithms sampled 8192 points from the point cloud as input to the odometry network. The projection-aware dense odometry pipeline takes all the pseudo-LiDAR point clouds generated from the images except for the error points as the input to the network. While making full use of the 3D geometric information in the images, the semantic information in the images is also used in the odometry task. The fusion of 2D-3D is achieved in an image-only based odometry. Experiments on the KITTI dataset prove the effectiveness of our method. To the best of our knowledge, this is the first visual odometry method using pseudo-LiDAR.