 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoGS: Large Scale Road Surface Reconstruction based on 2D Gaussian Splatting
May 23, 2024Road surface reconstruction plays a crucial role in autonomous driving, which can be used for road lane perception and autolabeling tasks. Recently, mesh-based road surface reconstruction algorithms show promising reconstruction results. However, these mesh-based methods suffer from slow speed and poor rendering quality. In contrast, the 3D Gaussian Splatting (3DGS) shows superior rendering speed and quality. Although 3DGS employs explicit Gaussian spheres to represent the scene, it lacks the ability to directly represent the geometric information of the scene. To address this limitation, we propose a novel large-scale road surface reconstruction approach based on 2D Gaussian Splatting (2DGS), named RoGS. The geometric shape of the road is explicitly represented using 2D Gaussian surfels, where each surfel stores color, semantics, and geometric information. Compared to Gaussian spheres, the Gaussian surfels aligns more closely with the physical reality of the road. Distinct from previous initialization methods that rely on point clouds for Gaussian spheres, we introduce a trajectory-based initialization for Gaussian surfels. Thanks to the explicit representation of the Gaussian surfels and a good initialization, our method achieves a significant acceleration while improving reconstruction quality. We achieve excellent results in reconstruction of roads surfaces in a variety of challenging real-world scenes.
DVLO: Deep Visual-LiDAR Odometry with Local-to-Global Feature Fusion and Bi-Directional Structure Alignment
Mar 27, 2024



Information inside visual and LiDAR data is well complementary derived from the fine-grained texture of images and massive geometric information in point clouds. However, it remains challenging to explore effective visual-LiDAR fusion, mainly due to the intrinsic data structure inconsistency between two modalities: Images are regular and dense, but LiDAR points are unordered and sparse. To address the problem, we propose a local-to-global fusion network with bi-directional structure alignment. To obtain locally fused features, we project points onto image plane as cluster centers and cluster image pixels around each center. Image pixels are pre-organized as pseudo points for image-to-point structure alignment. Then, we convert points to pseudo images by cylindrical projection (point-to-image structure alignment) and perform adaptive global feature fusion between point features with local fused features. Our method achieves state-of-the-art performance on KITTI odometry and FlyingThings3D scene flow datasets compared to both single-modal and multi-modal methods. Codes will be released later.
Unsupervised Learning of 3D Scene Flow with 3D Odometry Assistance
Sep 11, 2022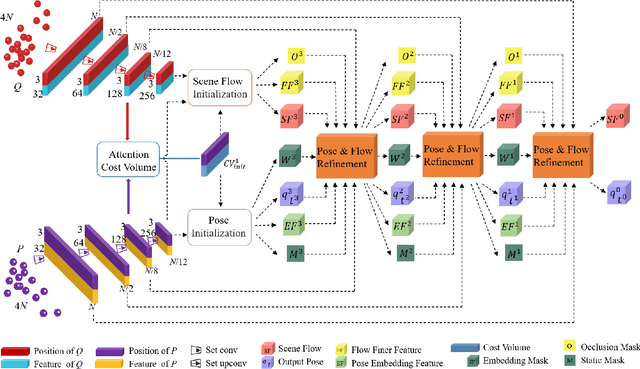
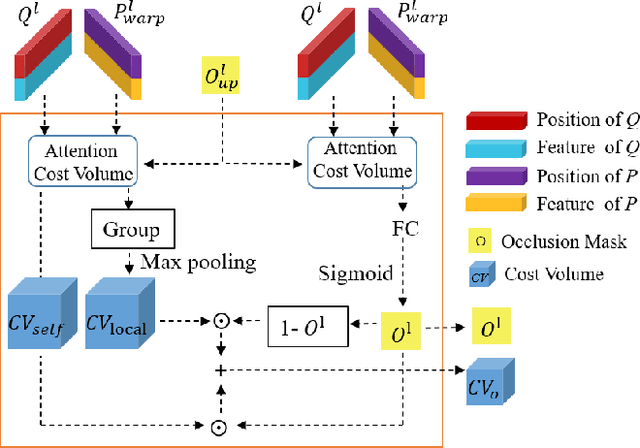
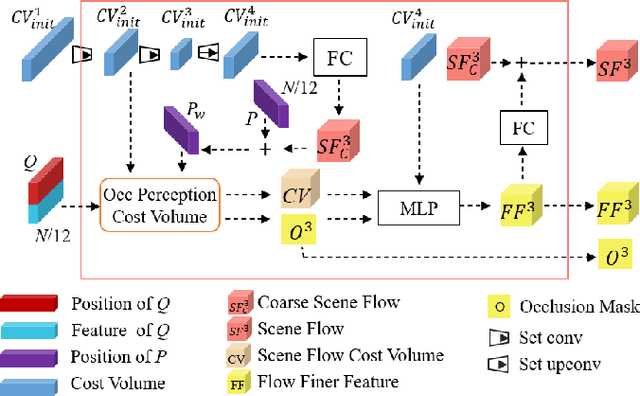
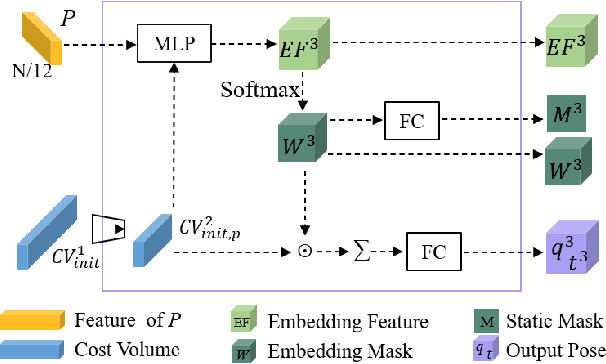
Scene flow represents the 3D motion of each point in the scene, which explicitly describes the distance and the direction of each point's movement. Scene flow estimation is used in various applications such as autonomous driving fields, activity recognition, and virtual reality fields. As it is challenging to annotate scene flow with ground truth for real-world data, this leaves no real-world dataset available to provide a large amount of data with ground truth for scene flow estimation. Therefore, many works use synthesized data to pre-train their network and real-world LiDAR data to finetune. Unlike the previous unsupervised learning of scene flow in point clouds, we propose to use odometry information to assist the unsupervised learning of scene flow and use real-world LiDAR data to train our network. Supervised odometry provides more accurate shared cost volume for scene flow. In addition, the proposed network has mask-weighted warp layers to get a more accurate predicted point cloud. The warp operation means applying an estimated pose transformation or scene flow to a source point cloud to obtain a predicted point cloud and is the key to refining scene flow from coarse to fine. When performing warp operations, the points in different states use different weights for the pose transformation and scene flow transformation. We classify the states of points as static, dynamic, and occluded, where the static masks are used to divide static and dynamic points, and the occlusion masks are used to divide occluded points. The mask-weighted warp layer indicates that static masks and occlusion masks are used as weights when performing warp operations. Our designs are proved to be effective in ablation experiments. The experiment results show the promising prospect of an odometry-assisted unsupervised learning method for 3D scene flow in real-world data.
Pseudo-LiDAR for Visual Odometry
Sep 04, 2022
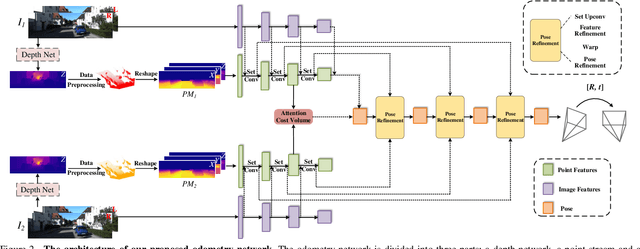
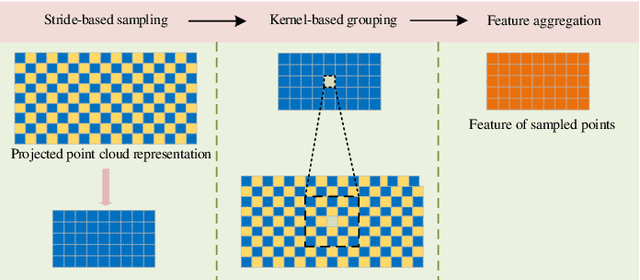
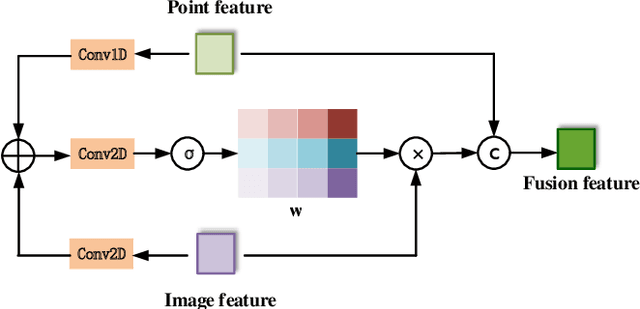
In the existing methods, LiDAR odometry shows superior performance, but visual odometry is still widely used for its price advantage. Conventionally, the task of visual odometry mainly rely on the input of continuous images. However, it is very complicated for the odometry network to learn the epipolar geometry information provided by the images. In this paper, the concept of pseudo-LiDAR is introduced into the odometry to solve this problem. The pseudo-LiDAR point cloud back-projects the depth map generated by the image into the 3D point cloud, which changes the way of image representation. Compared with the stereo images, the pseudo-LiDAR point cloud generated by the stereo matching network can get the explicit 3D coordinates. Since the 6 Degrees of Freedom (DoF) pose transformation occurs in 3D space, the 3D structure information provided by the pseudo-LiDAR point cloud is more direct than the image. Compared with sparse LiDAR, the pseudo-LiDAR has a denser point cloud. In order to make full use of the rich point cloud information provided by the pseudo-LiDAR, a projection-aware dense odometry pipeline is adopted. Most previous LiDAR-based algorithms sampled 8192 points from the point cloud as input to the odometry network. The projection-aware dense odometry pipeline takes all the pseudo-LiDAR point clouds generated from the images except for the error points as the input to the network. While making full use of the 3D geometric information in the images, the semantic information in the images is also used in the odometry task. The fusion of 2D-3D is achieved in an image-only based odometry. Experiments on the KITTI dataset prove the effectiveness of our method. To the best of our knowledge, this is the first visual odometry method using pseudo-LiDAR.