 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming 4D Visual Geometry Transformer
Jul 15, 2025

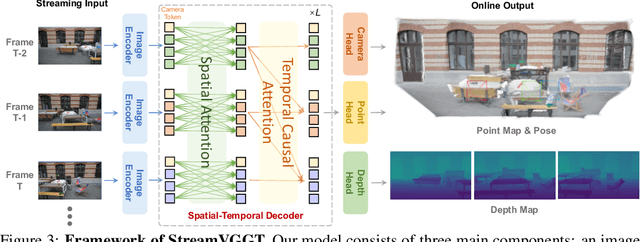

Perceiving and reconstructing 4D spatial-temporal geometry from videos is a fundamental yet challenging computer vision task. To facilitate interactive and real-time applications, we propose a streaming 4D visual geometry transformer that shares a similar philosophy with autoregressive large language models. We explore a simple and efficient design and employ a causal transformer architecture to process the input sequence in an online manner. We use temporal causal attention and cache the historical keys and values as implicit memory to enable efficient streaming long-term 4D reconstruction. This design can handle real-time 4D reconstruction by incrementally integrating historical information while maintaining high-quality spatial consistency. For efficient training, we propose to distill knowledge from the dense bidirectional visual geometry grounded transformer (VGGT) to our causal model. For inference, our model supports the migration of optimized efficient attention operator (e.g., FlashAttention) from the field of large language models. Extensive experiments on various 4D geometry perception benchmarks demonstrate that our model increases the inference speed in online scenarios while maintaining competitive performance, paving the way for scalable and interactive 4D vision systems. Code is available at: https://github.com/wzzheng/StreamVGGT.
DVLO: Deep Visual-LiDAR Odometry with Local-to-Global Feature Fusion and Bi-Directional Structure Alignment
Mar 27, 2024



Information inside visual and LiDAR data is well complementary derived from the fine-grained texture of images and massive geometric information in point clouds. However, it remains challenging to explore effective visual-LiDAR fusion, mainly due to the intrinsic data structure inconsistency between two modalities: Images are regular and dense, but LiDAR points are unordered and sparse. To address the problem, we propose a local-to-global fusion network with bi-directional structure alignment. To obtain locally fused features, we project points onto image plane as cluster centers and cluster image pixels around each center. Image pixels are pre-organized as pseudo points for image-to-point structure alignment. Then, we convert points to pseudo images by cylindrical projection (point-to-image structure alignment) and perform adaptive global feature fusion between point features with local fused features. Our method achieves state-of-the-art performance on KITTI odometry and FlyingThings3D scene flow datasets compared to both single-modal and multi-modal methods. Codes will be released later.