 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVectorWorld: Efficient Streaming World Model via Diffusion Flow on Vector Graphs
Mar 18, 2026Closed-loop evaluation of autonomous-driving policies requires interactive simulation beyond log replay. However, existing generative world models often degrade in closed loop due to (i) history-free initialization that mismatches policy inputs, (ii) multi-step sampling latency that violates real-time budgets, and (iii) compounding kinematic infeasibility over long horizons. We propose VectorWorld, a streaming world model that incrementally generates ego-centric $64 \mathrm{m}\times 64\mathrm{m}$ lane--agent vector-graph tiles during rollout. VectorWorld aligns initialization with history-conditioned policies by producing a policy-compatible interaction state via a motion-aware gated VAE. It enables real-time outpainting via solver-free one-step masked completion with an edge-gated relational DiT trained with interval-conditioned MeanFlow and JVP-based large-step supervision. To stabilize long-horizon rollouts, we introduce $Δ$Sim, a physics-aligned non-ego (NPC) policy with hybrid discrete--continuous actions and differentiable kinematic logit shaping. On Waymo open motion and nuPlan, VectorWorld improves map-structure fidelity and initialization validity, and supports stable, real-time $1\mathrm{km}+$ closed-loop rollouts (\href{https://github.com/jiangchaokang/VectorWorld}{code}).
RegFormer++: An Efficient Large-Scale 3D LiDAR Point Registration Network with Projection-Aware 2D Transformer
Mar 15, 2026Although point cloud registration has achieved remarkable advances in object-level and indoor scenes, large-scale LiDAR registration methods has been rarely explored before. Challenges mainly arise from the huge point scale, complex point distribution, and numerous outliers within outdoor LiDAR scans. In addition, most existing registration works generally adopt a two-stage paradigm: They first find correspondences by extracting discriminative local descriptors and then leverage robust estimators (e.g. RANSAC) to filter outliers, which are highly dependent on well-designed descriptors and post-processing choices. To address these problems, we propose a novel end-to-end differential transformer network, termed RegFormer++, for large-scale point cloud alignment without requiring any further post-processing. Specifically, a hierarchical projection-aware 2D transformer with linear complexity is proposed to project raw LiDAR points onto a cylindrical surface and extract global point features, which can improve resilience to outliers due to long-range dependencies. Because we fill original 3D coordinates into 2D projected positions, our designed transformer can benefit from both high efficiency in 2D processing and accuracy from 3D geometric information. Furthermore, to effectively reduce wrong point matching, a Bijective Association Transformer (BAT) is designed, combining both cross attention and all-to-all point gathering. To improve training stability and robustness, a feature-transformed optimal transport module is also designed for regressing the final pose transformation. Extensive experiments on KITTI, NuScenes, and Argoverse datasets demonstrate that our model achieves state-of-the-art performance in terms of both accuracy and efficiency.
D$^2$GSLAM: 4D Dynamic Gaussian Splatting SLAM
Dec 10, 2025Recent advances in Dense Simultaneous Localization and Mapping (SLAM) have demonstrated remarkable performance in static environments. However, dense SLAM in dynamic environments remains challenging. Most methods directly remove dynamic objects and focus solely on static scene reconstruction, which ignores the motion information contained in these dynamic objects. In this paper, we present D$^2$GSLAM, a novel dynamic SLAM system utilizing Gaussian representation, which simultaneously performs accurate dynamic reconstruction and robust tracking within dynamic environments. Our system is composed of four key components: (i) We propose a geometric-prompt dynamic separation method to distinguish between static and dynamic elements of the scene. This approach leverages the geometric consistency of Gaussian representation and scene geometry to obtain coarse dynamic regions. The regions then serve as prompts to guide the refinement of the coarse mask for achieving accurate motion mask. (ii) To facilitate accurate and efficient mapping of the dynamic scene, we introduce dynamic-static composite representation that integrates static 3D Gaussians with dynamic 4D Gaussians. This representation allows for modeling the transitions between static and dynamic states of objects in the scene for composite mapping and optimization. (iii) We employ a progressive pose refinement strategy that leverages both the multi-view consistency of static scene geometry and motion information from dynamic objects to achieve accurate camera tracking. (iv) We introduce a motion consistency loss, which leverages the temporal continuity in object motions for accurate dynamic modeling. Our D$^2$GSLAM demonstrates superior performance on dynamic scenes in terms of mapping and tracking accuracy, while also showing capability in accurate dynamic modeling.
GMF-Drive: Gated Mamba Fusion with Spatial-Aware BEV Representation for End-to-End Autonomous Driving
Aug 08, 2025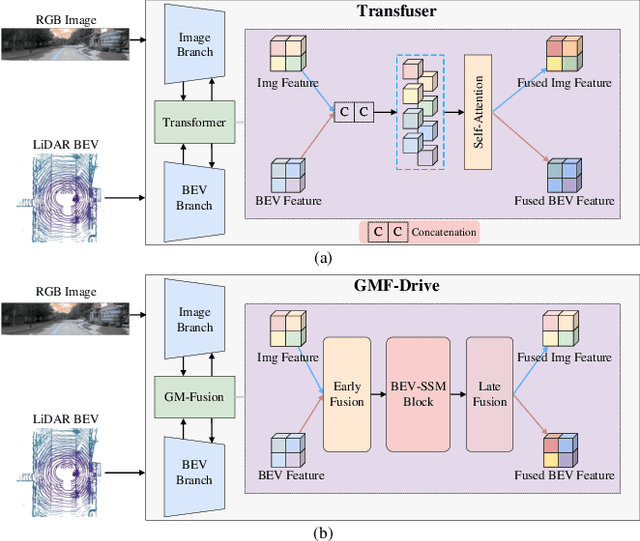
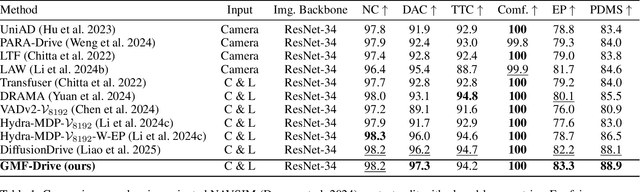
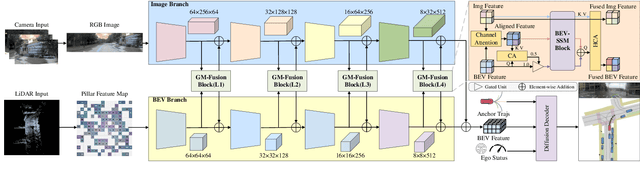

Diffusion-based models are redefining the state-of-the-art in end-to-end autonomous driving, yet their performance is increasingly hampered by a reliance on transformer-based fusion. These architectures face fundamental limitations: quadratic computational complexity restricts the use of high-resolution features, and a lack of spatial priors prevents them from effectively modeling the inherent structure of Bird's Eye View (BEV) representations. This paper introduces GMF-Drive (Gated Mamba Fusion for Driving), an end-to-end framework that overcomes these challenges through two principled innovations. First, we supersede the information-limited histogram-based LiDAR representation with a geometrically-augmented pillar format encoding shape descriptors and statistical features, preserving critical 3D geometric details. Second, we propose a novel hierarchical gated mamba fusion (GM-Fusion) architecture that substitutes an expensive transformer with a highly efficient, spatially-aware state-space model (SSM). Our core BEV-SSM leverages directional sequencing and adaptive fusion mechanisms to capture long-range dependencies with linear complexity, while explicitly respecting the unique spatial properties of the driving scene. Extensive experiments on the challenging NAVSIM benchmark demonstrate that GMF-Drive achieves a new state-of-the-art performance, significantly outperforming DiffusionDrive. Comprehensive ablation studies validate the efficacy of each component, demonstrating that task-specific SSMs can surpass a general-purpose transformer in both performance and efficiency for autonomous driving.
NeuroGauss4D-PCI: 4D Neural Fields and Gaussian Deformation Fields for Point Cloud Interpolation
May 23, 2024Point Cloud Interpolation confronts challenges from point sparsity, complex spatiotemporal dynamics, and the difficulty of deriving complete 3D point clouds from sparse temporal information. This paper presents NeuroGauss4D-PCI, which excels at modeling complex non-rigid deformations across varied dynamic scenes. The method begins with an iterative Gaussian cloud soft clustering module, offering structured temporal point cloud representations. The proposed temporal radial basis function Gaussian residual utilizes Gaussian parameter interpolation over time, enabling smooth parameter transitions and capturing temporal residuals of Gaussian distributions. Additionally, a 4D Gaussian deformation field tracks the evolution of these parameters, creating continuous spatiotemporal deformation fields. A 4D neural field transforms low-dimensional spatiotemporal coordinates ($x,y,z,t$) into a high-dimensional latent space. Finally, we adaptively and efficiently fuse the latent features from neural fields and the geometric features from Gaussian deformation fields. NeuroGauss4D-PCI outperforms existing methods in point cloud frame interpolation, delivering leading performance on both object-level (DHB) and large-scale autonomous driving datasets (NL-Drive), with scalability to auto-labeling and point cloud densification tasks. The source code is released at https://github.com/jiangchaokang/NeuroGauss4D-PCI.
MAMBA4D: Efficient Long-Sequence Point Cloud Video Understanding with Disentangled Spatial-Temporal State Space Models
May 23, 2024



Point cloud videos effectively capture real-world spatial geometries and temporal dynamics, which are essential for enabling intelligent agents to understand the dynamically changing 3D world we live in. Although static 3D point cloud processing has witnessed significant advancements, designing an effective 4D point cloud video backbone remains challenging, mainly due to the irregular and unordered distribution of points and temporal inconsistencies across frames. Moreover, recent state-of-the-art 4D backbones predominantly rely on transformer-based architectures, which commonly suffer from large computational costs due to their quadratic complexity, particularly when processing long video sequences. To address these challenges, we propose a novel 4D point cloud video understanding backbone based on the recently advanced State Space Models (SSMs). Specifically, our backbone begins by disentangling space and time in raw 4D sequences, and then establishing spatio-temporal correlations using our newly developed Intra-frame Spatial Mamba and Inter-frame Temporal Mamba blocks. The Intra-frame Spatial Mamba module is designed to encode locally similar or related geometric structures within a certain temporal searching stride, which can effectively capture short-term dynamics. Subsequently, these locally correlated tokens are delivered to the Inter-frame Temporal Mamba module, which globally integrates point features across the entire video with linear complexity, further establishing long-range motion dependencies. Experimental results on human action recognition and 4D semantic segmentation tasks demonstrate the superiority of our proposed method. Especially, for long video sequences, our proposed Mamba-based method has an 87.5% GPU memory reduction, 5.36 times speed-up, and much higher accuracy (up to +10.4%) compared with transformer-based counterparts on MSR-Action3D dataset.
3DSFLabelling: Boosting 3D Scene Flow Estimation by Pseudo Auto-labelling
Mar 01, 2024



Learning 3D scene flow from LiDAR point clouds presents significant difficulties, including poor generalization from synthetic datasets to real scenes, scarcity of real-world 3D labels, and poor performance on real sparse LiDAR point clouds. We present a novel approach from the perspective of auto-labelling, aiming to generate a large number of 3D scene flow pseudo labels for real-world LiDAR point clouds. Specifically, we employ the assumption of rigid body motion to simulate potential object-level rigid movements in autonomous driving scenarios. By updating different motion attributes for multiple anchor boxes, the rigid motion decomposition is obtained for the whole scene. Furthermore, we developed a novel 3D scene flow data augmentation method for global and local motion. By perfectly synthesizing target point clouds based on augmented motion parameters, we easily obtain lots of 3D scene flow labels in point clouds highly consistent with real scenarios. On multiple real-world datasets including LiDAR KITTI, nuScenes, and Argoverse, our method outperforms all previous supervised and unsupervised methods without requiring manual labelling. Impressively, our method achieves a tenfold reduction in EPE3D metric on the LiDAR KITTI dataset, reducing it from $0.190m$ to a mere $0.008m$ error.
DifFlow3D: Toward Robust Uncertainty-Aware Scene Flow Estimation with Diffusion Model
Nov 29, 2023



Scene flow estimation, which aims to predict per-point 3D displacements of dynamic scenes, is a fundamental task in the computer vision field. However, previous works commonly suffer from unreliable correlation caused by locally constrained searching ranges, and struggle with accumulated inaccuracy arising from the coarse-to-fine structure. To alleviate these problems, we propose a novel uncertainty-aware scene flow estimation network (DifFlow3D) with the diffusion probabilistic model. Iterative diffusion-based refinement is designed to enhance the correlation robustness and resilience to challenging cases, e.g., dynamics, noisy inputs, repetitive patterns, etc. To restrain the generation diversity, three key flow-related features are leveraged as conditions in our diffusion model. Furthermore, we also develop an uncertainty estimation module within diffusion to evaluate the reliability of estimated scene flow. Our DifFlow3D achieves state-of-the-art performance, with 6.7\% and 19.1\% EPE3D reduction respectively on FlyingThings3D and KITTI 2015 datasets. Notably, our method achieves an unprecedented millimeter-level accuracy (0.0089m in EPE3D) on the KITTI dataset. Additionally, our diffusion-based refinement paradigm can be readily integrated as a plug-and-play module into existing scene flow networks, significantly increasing their estimation accuracy. Codes will be released later.
RegFormer: An Efficient Projection-Aware Transformer Network for Large-Scale Point Cloud Registration
Mar 22, 2023



Although point cloud registration has achieved remarkable advances in object-level and indoor scenes, large-scale registration methods are rarely explored. Challenges mainly arise from the huge point number, complex distribution, and outliers of outdoor LiDAR scans. In addition, most existing registration works generally adopt a two-stage paradigm: They first find correspondences by extracting discriminative local features, and then leverage estimators (eg. RANSAC) to filter outliers, which are highly dependent on well-designed descriptors and post-processing choices. To address these problems, we propose an end-to-end transformer network (RegFormer) for large-scale point cloud alignment without any further post-processing. Specifically, a projection-aware hierarchical transformer is proposed to capture long-range dependencies and filter outliers by extracting point features globally. Our transformer has linear complexity, which guarantees high efficiency even for large-scale scenes. Furthermore, to effectively reduce mismatches, a bijective association transformer is designed for regressing the initial transformation. Extensive experiments on KITTI and NuScenes datasets demonstrate that our RegFormer achieves state-of-the-art performance in terms of both accuracy and efficiency.
3D Scene Flow Estimation on Pseudo-LiDAR: Bridging the Gap on Estimating Point Motion
Sep 27, 2022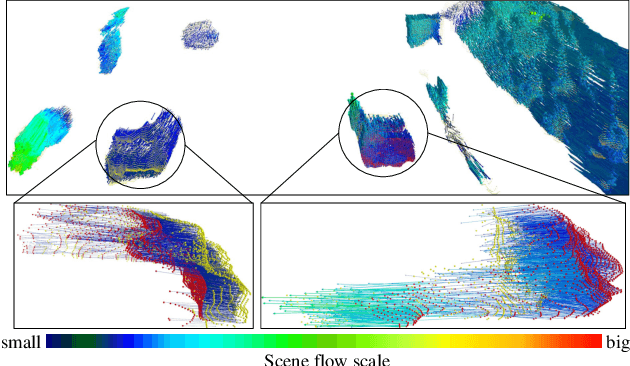
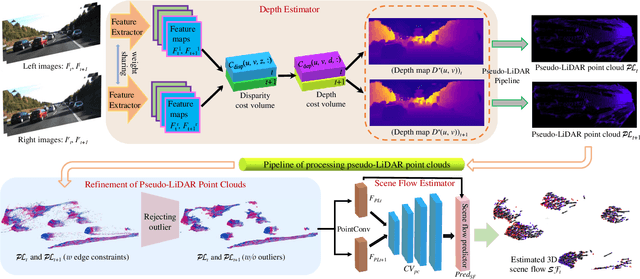
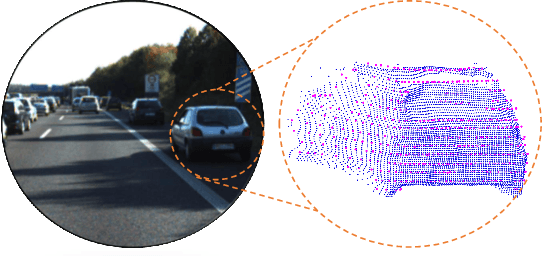
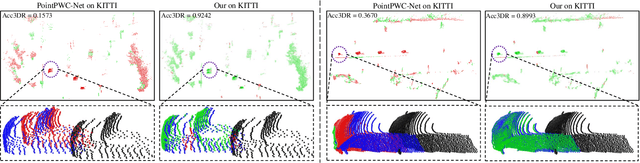
3D scene flow characterizes how the points at the current time flow to the next time in the 3D Euclidean space, which possesses the capacity to infer autonomously the non-rigid motion of all objects in the scene. The previous methods for estimating scene flow from images have limitations, which split the holistic nature of 3D scene flow by estimating optical flow and disparity separately. Learning 3D scene flow from point clouds also faces the difficulties of the gap between synthesized and real data and the sparsity of LiDAR point clouds. In this paper, the generated dense depth map is utilized to obtain explicit 3D coordinates, which achieves direct learning of 3D scene flow from 2D images. The stability of the predicted scene flow is improved by introducing the dense nature of 2D pixels into the 3D space. Outliers in the generated 3D point cloud are removed by statistical methods to weaken the impact of noisy points on the 3D scene flow estimation task. Disparity consistency loss is proposed to achieve more effective unsupervised learning of 3D scene flow. The proposed method of self-supervised learning of 3D scene flow on real-world images is compared with a variety of methods for learning on the synthesized dataset and learning on LiDAR point clouds. The comparisons of multiple scene flow metrics are shown to demonstrate the effectiveness and superiority of introducing pseudo-LiDAR point cloud to scene flow estimation.