 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFFPA-Net: Efficient Feature Fusion with Projection Awareness for 3D Object Detection
Paper and Code
Sep 15, 2022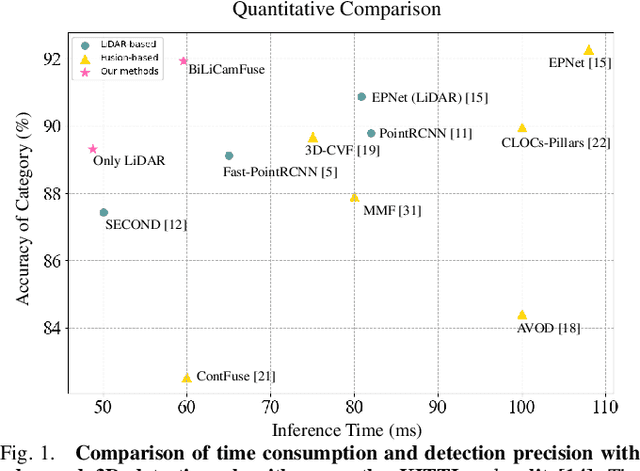
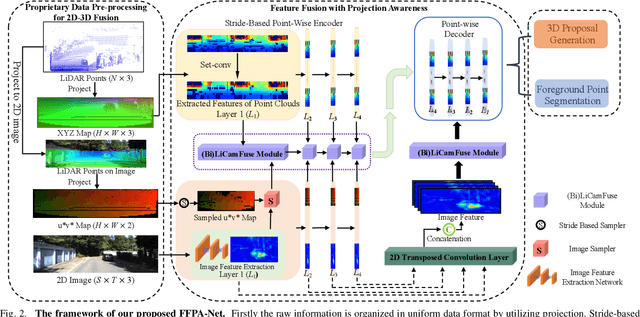
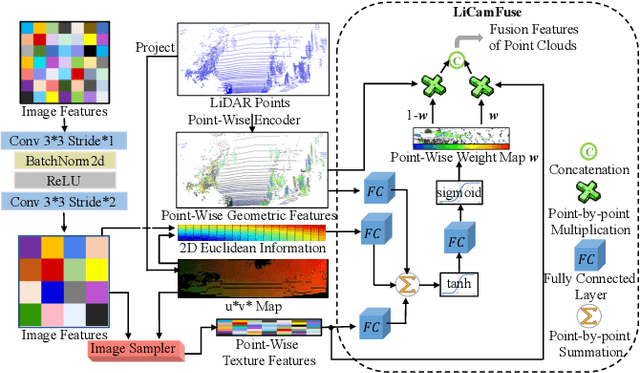
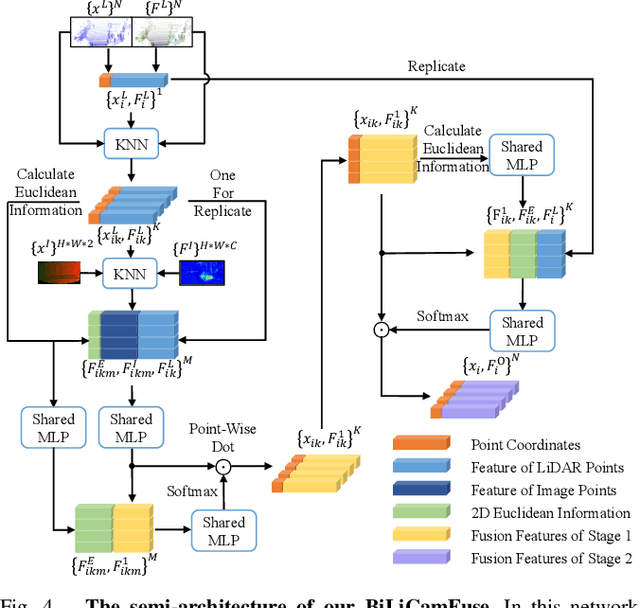
Promising complementarity exists between the texture features of color images and the geometric information of LiDAR point clouds. However, there still present many challenges for efficient and robust feature fusion in the field of 3D object detection. In this paper, first, unstructured 3D point clouds are filled in the 2D plane and 3D point cloud features are extracted faster using projection-aware convolution layers. Further, the corresponding indexes between different sensor signals are established in advance in the data preprocessing, which enables faster cross-modal feature fusion. To address LiDAR points and image pixels misalignment problems, two new plug-and-play fusion modules, LiCamFuse and BiLiCamFuse, are proposed. In LiCamFuse, soft query weights with perceiving the Euclidean distance of bimodal features are proposed. In BiLiCamFuse, the fusion module with dual attention is proposed to deeply correlate the geometric and textural features of the scene. The quantitative results on the KITTI dataset demonstrate that the proposed method achieves better feature-level fusion. In addition, the proposed network shows a shorter running time compared to existing methods.