 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Signal-Language Foundation Model for Broad-Spectrum Cardiovascular Assessment from Routine Electrocardiography
May 25, 2026Electrocardiography (ECG) is central to cardiovascular care, but conventional AI models are often restricted to common arrhythmias and may generalize poorly across populations or clinically subtle diseases. We developed ECG Contrastive Language-Image Pre-training (ECGCLIP), a signal-language contrastive learning framework that aligns ECG waveforms with expert diagnostic reports. ECGCLIP was pre-trained on 2,837,962 ECG studies from 1,324,856 patients and evaluated on a held-out internal test set plus nine independent external cohorts comprising about 1.5 million ECGs. Evaluation covered 89 downstream tasks, including 45 ECG diagnoses, 39 echocardiographic targets, and 5 rare cardiac diseases, using PRAUC as the primary metric. ECGCLIP consistently improved performance over random initialization and Merl-R18 baselines. On the internal test set, ECGCLIP-R34 achieved strong performance for atrial fibrillation (PRAUC 0.900) and ST-segment elevation myocardial infarction (PRAUC 0.383), with robust generalization across all external cohorts. It also improved low-prevalence and diagnostically elusive diseases, including Ebstein anomaly, constrictive pericarditis, dextrocardia, and cardiac amyloidosis, with internal PRAUC values of 0.253, 0.175, 0.121, and 0.201, respectively. ECGCLIP was data efficient, matching or exceeding full-dataset baseline performance with only 10% of training data. Feature visualization and saliency analysis suggested clinically meaningful representations aligned with established electrocardiographic criteria. These findings indicate that large-scale ECG-report contrastive pre-training can expand routine ECG interpretation beyond common arrhythmias toward broad cardiovascular assessment and opportunistic screening of echocardiographic and rare conditions.
CharTool: Tool-Integrated Visual Reasoning for Chart Understanding
Apr 03, 2026Charts are ubiquitous in scientific and financial literature for presenting structured data. However, chart reasoning remains challenging for multimodal large language models (MLLMs) due to the lack of high-quality training data, as well as the need for fine-grained visual grounding and precise numerical computation. To address these challenges, we first propose DuoChart, a scalable dual-source data pipeline that combines synthesized charts with real-world charts to construct diverse, high-quality chart training data. We then introduce CharTool, which equips MLLMs with external tools, including image cropping for localized visual perception and code-based computation for accurate numerical reasoning. Through agentic reinforcement learning on DuoChart, CharTool learns tool-integrated reasoning grounded in chart content. Extensive experiments on six chart benchmarks show that our method consistently improves over strong MLLM baselines across model scales. Notably, CharTool-7B outperforms the base model by **+8.0%** on CharXiv (Reasoning) and **+9.78%** on ChartQAPro, while achieving competitive performance with substantially larger or proprietary models. Moreover, CharTool demonstrates positive generalization to out-of-domain visual math reasoning benchmarks.
In-network Attack Detection with Federated Deep Learning in IoT Networks: Real Implementation and Analysis
Mar 23, 2026The rapid expansion of the Internet of Things (IoT) and its integration with backbone networks have heightened the risk of security breaches. Traditional centralized approaches to anomaly detection, which require transferring large volumes of data to central servers, suffer from privacy, scalability, and latency limitations. This paper proposes a lightweight autoencoder-based anomaly detection framework designed for deployment on resource-constrained edge devices, enabling real-time detection while minimizing data transfer and preserving privacy. Federated learning is employed to train models collaboratively across distributed devices, where local training occurs on edge nodes and only model weights are aggregated at a central server. A real-world IoT testbed using Raspberry Pi sensor nodes was developed to collect normal and attack traffic data. The proposed federated anomaly detection system, implemented and evaluated on the testbed, demonstrates its effectiveness in accurately identifying network attacks. The communication overhead was reduced significantly while achieving comparable performance to the centralized method.
Neuronal Activation States as Sample Embeddings for Data Selection in Task-Specific Instruction Tuning
Mar 19, 2025Task-specific instruction tuning enhances the performance of large language models (LLMs) on specialized tasks, yet efficiently selecting relevant data for this purpose remains a challenge. Inspired by neural coactivation in the human brain, we propose a novel data selection method called NAS, which leverages neuronal activation states as embeddings for samples in the feature space. Extensive experiments show that NAS outperforms classical data selection methods in terms of both effectiveness and robustness across different models, datasets, and selection ratios.
Alignment for Efficient Tool Calling of Large Language Models
Mar 09, 2025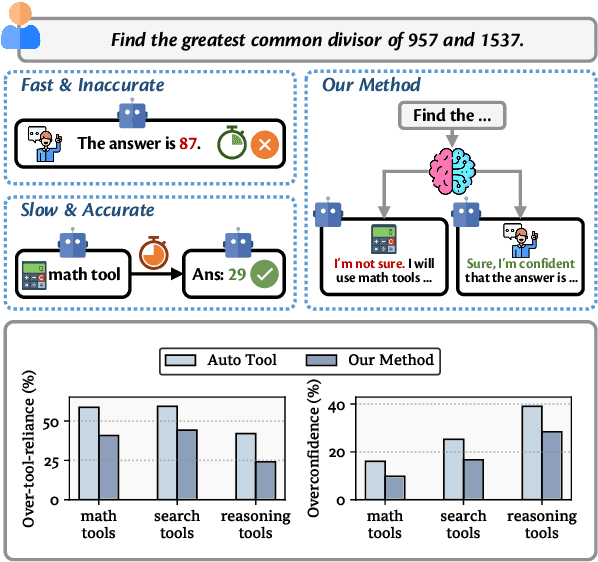
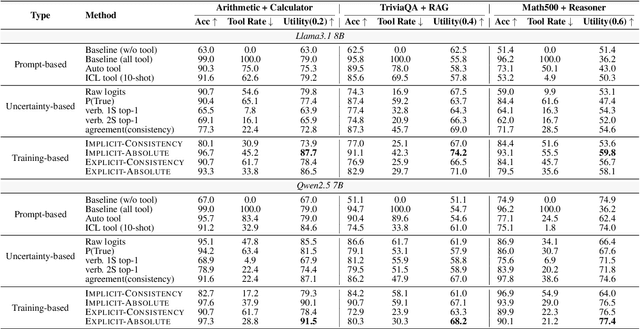
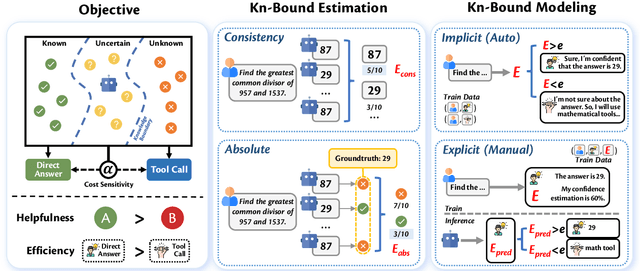

Recent advancements in tool learning have enabled large language models (LLMs) to integrate external tools, enhancing their task performance by expanding their knowledge boundaries. However, relying on tools often introduces tradeoffs between performance, speed, and cost, with LLMs sometimes exhibiting overreliance and overconfidence in tool usage. This paper addresses the challenge of aligning LLMs with their knowledge boundaries to make more intelligent decisions about tool invocation. We propose a multi objective alignment framework that combines probabilistic knowledge boundary estimation with dynamic decision making, allowing LLMs to better assess when to invoke tools based on their confidence. Our framework includes two methods for knowledge boundary estimation, consistency based and absolute estimation, and two training strategies for integrating these estimates into the model decision making process. Experimental results on various tool invocation scenarios demonstrate the effectiveness of our framework, showing significant improvements in tool efficiency by reducing unnecessary tool usage.
Compressing KV Cache for Long-Context LLM Inference with Inter-Layer Attention Similarity
Dec 03, 2024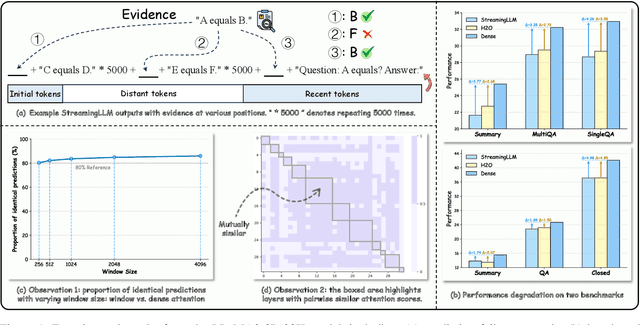



The increasing context window size in Large Language Models (LLMs), such as the GPT and LLaMA series, has improved their ability to tackle complex, long-text tasks, but at the cost of inference efficiency, particularly regarding memory and computational complexity. Existing methods, including selective token retention and window-based attention, improve efficiency but risk discarding important tokens needed for future text generation. In this paper, we propose an approach that enhances LLM efficiency without token loss by reducing the memory and computational load of less important tokens, rather than discarding them.We address two challenges: 1) investigating the distribution of important tokens in the context, discovering recent tokens are more important than distant tokens in context, and 2) optimizing resources for distant tokens by sharing attention scores across layers. The experiments show that our method saves $35\%$ KV cache without compromising the performance.
Smart energy management: process structure-based hybrid neural networks for optimal scheduling and economic predictive control in integrated systems
Oct 07, 2024Integrated energy systems (IESs) are complex systems consisting of diverse operating units spanning multiple domains. To address its operational challenges, we propose a physics-informed hybrid time-series neural network (NN) surrogate to predict the dynamic performance of IESs across multiple time scales. This neural network-based modeling approach develops time-series multi-layer perceptrons (MLPs) for the operating units and integrates them with prior process knowledge about system structure and fundamental dynamics. This integration forms three hybrid NNs (long-term, slow, and fast MLPs) that predict the entire system dynamics across multiple time scales. Leveraging these MLPs, we design an NN-based scheduler and an NN-based economic model predictive control (NEMPC) framework to meet global operational requirements: rapid electrical power responsiveness to operators requests, adequate cooling supply to customers, and increased system profitability, while addressing the dynamic time-scale multiplicity present in IESs. The proposed day-ahead scheduler is formulated using the ReLU network-based MLP, which effectively represents IES performance under a broad range of conditions from a long-term perspective. The scheduler is then exactly recast into a mixed-integer linear programming problem for efficient evaluation. The real-time NEMPC, based on slow and fast MLPs, comprises two sequential distributed control agents: a slow NEMPC for the cooling-dominant subsystem with slower transient responses and a fast NEMPC for the power-dominant subsystem with faster responses. Extensive simulations demonstrate that the developed scheduler and NEMPC schemes outperform their respective benchmark scheduler and controller by about 25% and 40%. Together, they enhance overall system performance by over 70% compared to benchmark approaches.
RL-GSBridge: 3D Gaussian Splatting Based Real2Sim2Real Method for Robotic Manipulation Learning
Sep 30, 2024
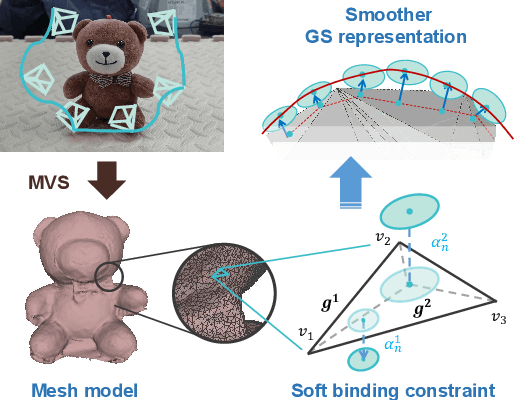
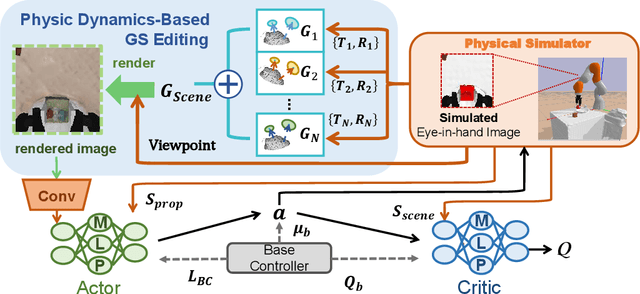

Sim-to-Real refers to the process of transferring policies learned in simulation to the real world, which is crucial for achieving practical robotics applications. However, recent Sim2real methods either rely on a large amount of augmented data or large learning models, which is inefficient for specific tasks. In recent years, radiance field-based reconstruction methods, especially the emergence of 3D Gaussian Splatting, making it possible to reproduce realistic real-world scenarios. To this end, we propose a novel real-to-sim-to-real reinforcement learning framework, RL-GSBridge, which introduces a mesh-based 3D Gaussian Splatting method to realize zero-shot sim-to-real transfer for vision-based deep reinforcement learning. We improve the mesh-based 3D GS modeling method by using soft binding constraints, enhancing the rendering quality of mesh models. We then employ a GS editing approach to synchronize rendering with the physics simulator, reflecting the interactions of the physical robot more accurately. Through a series of sim-to-real robotic arm experiments, including grasping and pick-and-place tasks, we demonstrate that RL-GSBridge maintains a satisfactory success rate in real-world task completion during sim-to-real transfer. Furthermore, a series of rendering metrics and visualization results indicate that our proposed mesh-based 3D Gaussian reduces artifacts in unstructured objects, demonstrating more realistic rendering performance.
Probing the Robustness of Vision-Language Pretrained Models: A Multimodal Adversarial Attack Approach
Aug 24, 2024



Vision-language pretraining (VLP) with transformers has demonstrated exceptional performance across numerous multimodal tasks. However, the adversarial robustness of these models has not been thoroughly investigated. Existing multimodal attack methods have largely overlooked cross-modal interactions between visual and textual modalities, particularly in the context of cross-attention mechanisms. In this paper, we study the adversarial vulnerability of recent VLP transformers and design a novel Joint Multimodal Transformer Feature Attack (JMTFA) that concurrently introduces adversarial perturbations in both visual and textual modalities under white-box settings. JMTFA strategically targets attention relevance scores to disrupt important features within each modality, generating adversarial samples by fusing perturbations and leading to erroneous model predictions. Experimental results indicate that the proposed approach achieves high attack success rates on vision-language understanding and reasoning downstream tasks compared to existing baselines. Notably, our findings reveal that the textual modality significantly influences the complex fusion processes within VLP transformers. Moreover, we observe no apparent relationship between model size and adversarial robustness under our proposed attacks. These insights emphasize a new dimension of adversarial robustness and underscore potential risks in the reliable deployment of multimodal AI systems.
NeRF in Robotics: A Survey
May 02, 2024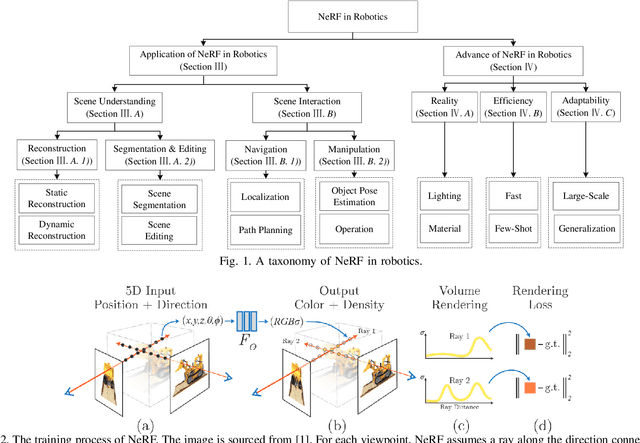
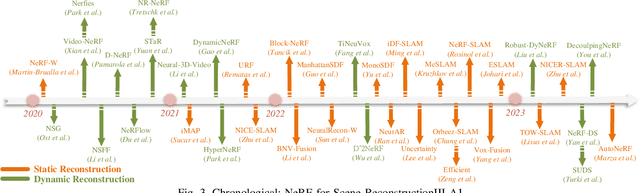
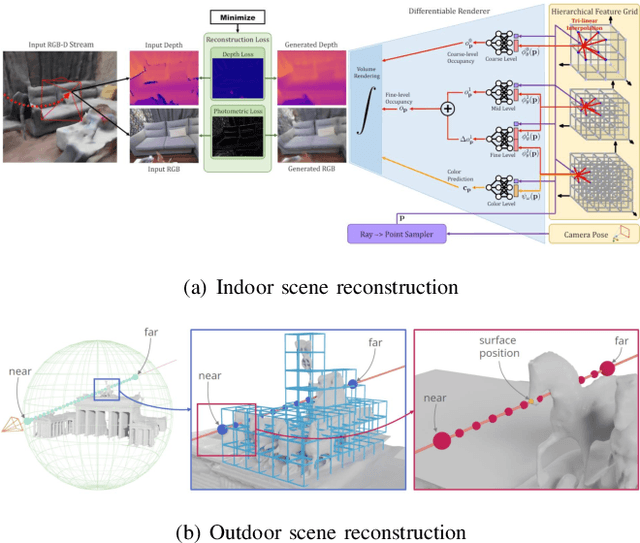
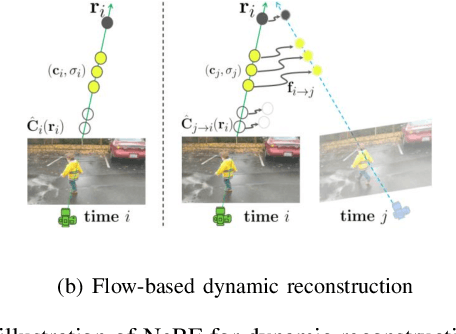
Meticulous 3D environment representations have been a longstanding goal in computer vision and robotics fields. The recent emergence of neural implicit representations has introduced radical innovation to this field as implicit representations enable numerous capabilities. Among these, the Neural Radiance Field (NeRF) has sparked a trend because of the huge representational advantages, such as simplified mathematical models, compact environment storage, and continuous scene representations. Apart from computer vision, NeRF has also shown tremendous potential in the field of robotics. Thus, we create this survey to provide a comprehensive understanding of NeRF in the field of robotics. By exploring the advantages and limitations of NeRF, as well as its current applications and future potential, we hope to shed light on this promising area of research. Our survey is divided into two main sections: \textit{The Application of NeRF in Robotics} and \textit{The Advance of NeRF in Robotics}, from the perspective of how NeRF enters the field of robotics. In the first section, we introduce and analyze some works that have been or could be used in the field of robotics from the perception and interaction perspectives. In the second section, we show some works related to improving NeRF's own properties, which are essential for deploying NeRF in the field of robotics. In the discussion section of the review, we summarize the existing challenges and provide some valuable future research directions for reference.