 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoE-TransMov: A Transformer-based Model for Next POI Prediction in Familiar & Unfamiliar Movements
Dec 19, 2025



Accurate prediction of the next point of interest (POI) within human mobility trajectories is essential for location-based services, as it enables more timely and personalized recommendations. In particular, with the rise of these approaches, studies have shown that users exhibit different POI choices in their familiar and unfamiliar areas, highlighting the importance of incorporating user familiarity into predictive models. However, existing methods often fail to distinguish between the movements of users in familiar and unfamiliar regions. To address this, we propose MoE-TransMov, a Transformer-based model with a Transformer model with a Mixture-of-Experts (MoE) architecture designed to use one framework to capture distinct mobility patterns across different moving contexts without requiring separate training for certain data. Using user-check-in data, we classify movements into familiar and unfamiliar categories and develop a specialized expert network to improve prediction accuracy. Our approach integrates self-attention mechanisms and adaptive gating networks to dynamically select the most relevant expert models for different mobility contexts. Experiments on two real-world datasets, including the widely used but small open-source Foursquare NYC dataset and the large-scale Kyoto dataset collected with LY Corporation (Yahoo Japan Corporation), show that MoE-TransMov outperforms state-of-the-art baselines with notable improvements in Top-1, Top-5, Top-10 accuracy, and mean reciprocal rank (MRR). Given the results, we find that by using this approach, we can efficiently improve mobility predictions under different moving contexts, thereby enhancing the personalization of recommendation systems and advancing various urban applications.
Congestion Forecast for Trains with Railroad-Graph-based Semi-Supervised Learning using Sparse Passenger Reports
Oct 23, 2024



Forecasting rail congestion is crucial for efficient mobility in transport systems. We present rail congestion forecasting using reports from passengers collected through a transit application. Although reports from passengers have received attention from researchers, ensuring a sufficient volume of reports is challenging due to passenger's reluctance. The limited number of reports results in the sparsity of the congestion label, which can be an issue in building a stable prediction model. To address this issue, we propose a semi-supervised method for congestion forecasting for trains, or SURCONFORT. Our key idea is twofold: firstly, we adopt semi-supervised learning to leverage sparsely labeled data and many unlabeled data. Secondly, in order to complement the unlabeled data from nearby stations, we design a railway network-oriented graph and apply the graph to semi-supervised graph regularization. Empirical experiments with actual reporting data show that SURCONFORT improved the forecasting performance by 14.9% over state-of-the-art methods under the label sparsity.
Single-tap Latency Reduction with Single- or Double- tap Prediction
Aug 05, 2024



Touch surfaces are widely utilized for smartphones, tablet PCs, and laptops (touchpad), and single and double taps are the most basic and common operations on them. The detection of single or double taps causes the single-tap latency problem, which creates a bottleneck in terms of the sensitivity of touch inputs. To reduce the single-tap latency, we propose a novel machine-learning-based tap prediction method called PredicTaps. Our method predicts whether a detected tap is a single tap or the first contact of a double tap without having to wait for the hundreds of milliseconds conventionally required. We present three evaluations and one user evaluation that demonstrate its broad applicability and usability for various tap situations on two form factors (touchpad and smartphone). The results showed PredicTaps reduces the single-tap latency from 150-500 ms to 12 ms on laptops and to 17.6 ms on smartphones without reducing usability.
Estimating Sunlight Using GNSS Signal Strength from Smartphone
Aug 09, 2022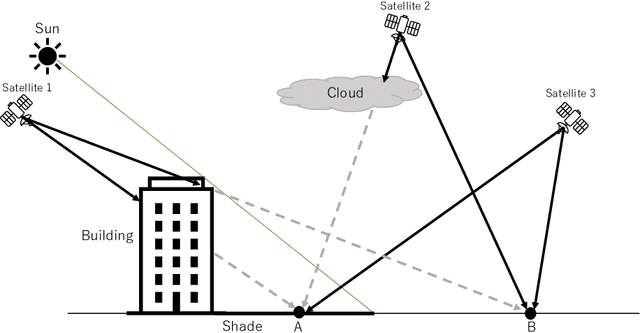
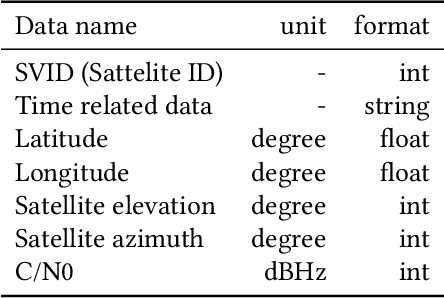
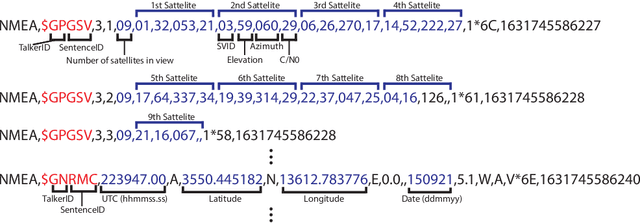
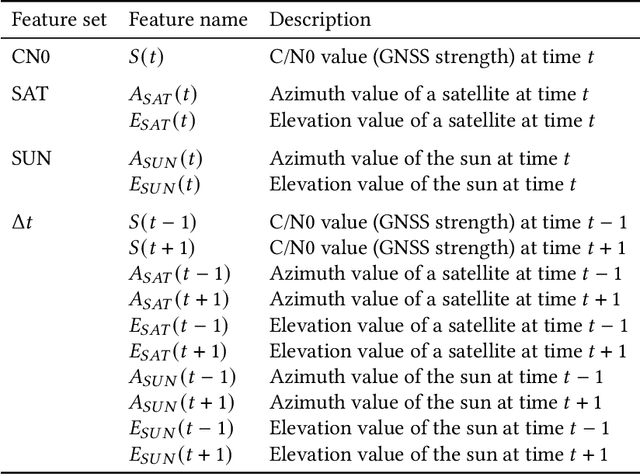
Excessive or inadequate exposure to ultraviolet light (UV) is harmful to health and causes osteoporosis, colon cancer, and skin cancer. The UV Index, a standard scale of UV light, tends to increase in sunny places and sharply decrease in the shade. A method for distinguishing shady and sunny places would help us to prevent and cure diseases caused by UV. However, the existing methods, such as carrying UV sensors, impose a load on the user, whereas city-level UV forecasts do not have enough granularity for monitoring an individual's UV exposure. This paper proposes a method to detect sunny and shady places by using an off-the-shelf mobile device. The method detects these places by using a characteristic of the GNSS signal strength that is attenuated by objects around the device. As a dataset, we collected GNSS signal data, such as C/N0, satellite ID, satellite angle, and sun angle, together with reference data (i.e., sunny and shady place information every minute) for four days from five locations. Using the dataset, we created twelve classification models by using supervised machine learning methods and evaluated their performance by 4-fold cross-validation. In addition, we investigated the feature importance and the effect of combining features. The performance evaluation showed that our classification model could classify sunny and shady places with more than 97% accuracy in the best case. Moreover, our investigation revealed that the value of C/N0 at a moment and its time series (i.e., C/N0 value before and after the moment) are more important features.
GEO-BLEU: Similarity Measure for Geospatial Sequences
Dec 14, 2021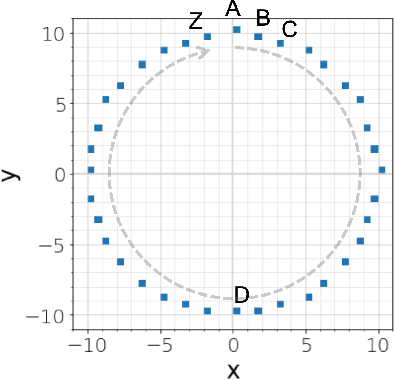

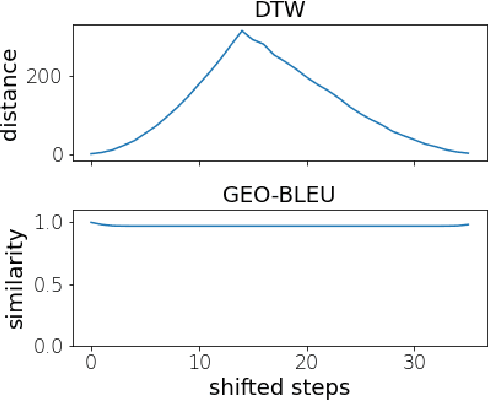
In recent geospatial research, the importance of modeling large-scale human mobility data via self-supervised learning is rising, in parallel with progress in natural language processing driven by self-supervised approaches using large-scale corpora. Whereas there are already plenty of feasible approaches applicable to geospatial sequence modeling itself, there seems to be room to improve with regard to evaluation, specifically about how to measure the similarity between generated and reference sequences. In this work, we propose a novel similarity measure, GEO-BLEU, which can be especially useful in the context of geospatial sequence modeling and generation. As the name suggests, this work is based on BLEU, one of the most popular measures used in machine translation research, while introducing spatial proximity to the idea of n-gram. We compare this measure with an established baseline, dynamic time warping, applying it to actual generated geospatial sequences. Using crowdsourced annotated data on the similarity between geospatial sequences collected from over 12,000 cases, we quantitatively and qualitatively show the proposed method's superiority.
Learning Fine Grained Place Embeddings with Spatial Hierarchy from Human Mobility Trajectories
Feb 06, 2020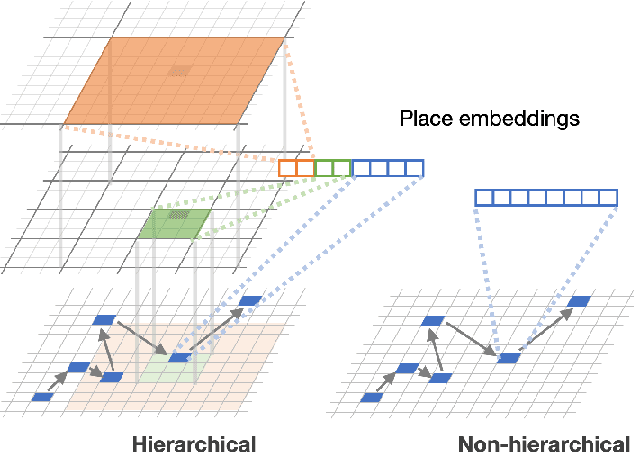
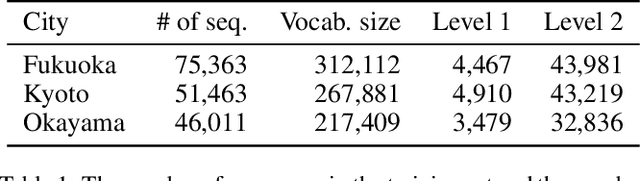
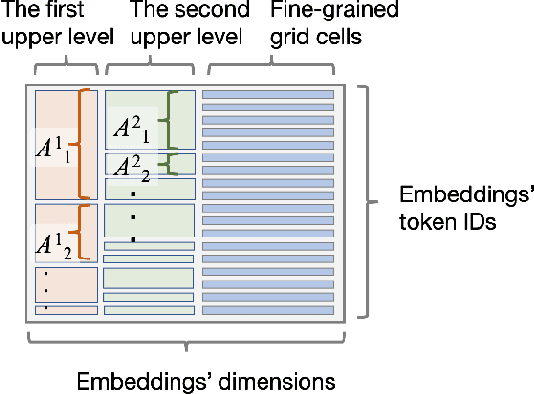
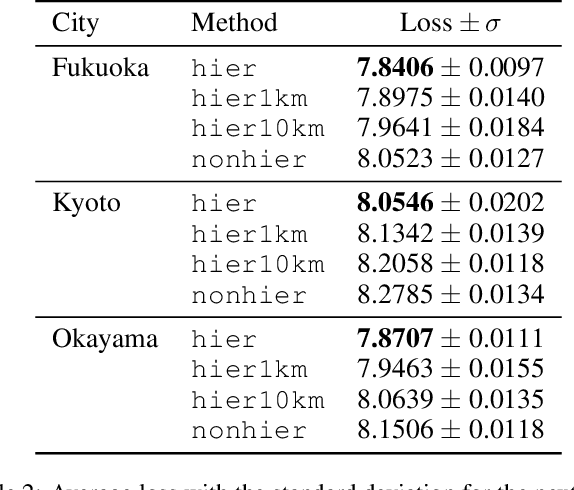
Place embeddings generated from human mobility trajectories have become a popular method to understand the functionality of places. Place embeddings with high spatial resolution are desirable for many applications, however, downscaling the spatial resolution deteriorates the quality of embeddings due to data sparsity, especially in less populated areas. We address this issue by proposing a method that generates fine grained place embeddings, which leverages spatial hierarchical information according to the local density of observed data points. The effectiveness of our fine grained place embeddings are compared to baseline methods via next place prediction tasks using real world trajectory data from 3 cities in Japan. In addition, we demonstrate the value of our fine grained place embeddings for land use classification applications. We believe that our technique of incorporating spatial hierarchical information can complement and reinforce various place embedding generating methods.
City2City: Translating Place Representations across Cities
Nov 26, 2019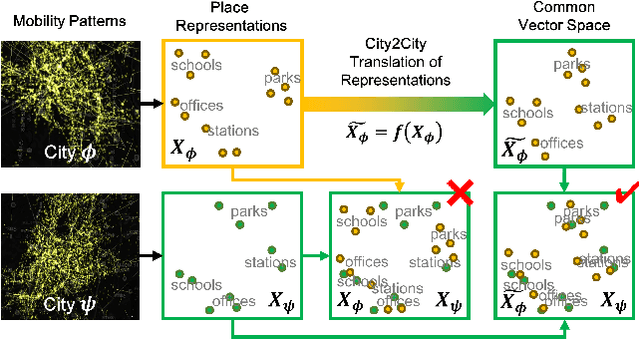
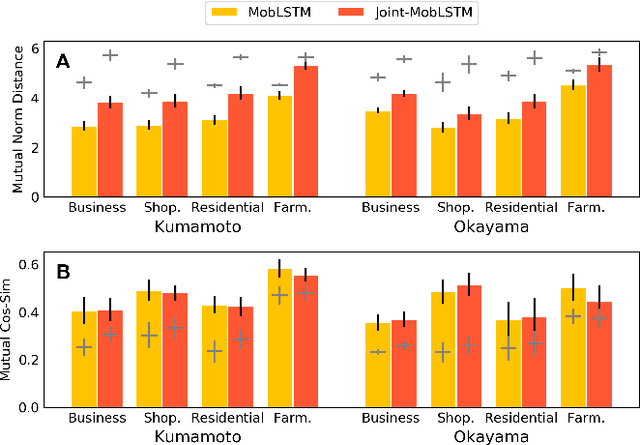
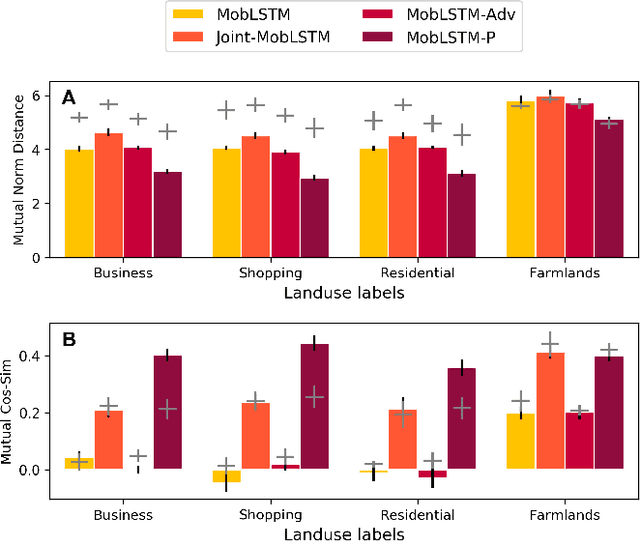
Large mobility datasets collected from various sources have allowed us to observe, analyze, predict and solve a wide range of important urban challenges. In particular, studies have generated place representations (or embeddings) from mobility patterns in a similar manner to word embeddings to better understand the functionality of different places within a city. However, studies have been limited to generating such representations of cities in an individual manner and has lacked an inter-city perspective, which has made it difficult to transfer the insights gained from the place representations across different cities. In this study, we attempt to bridge this research gap by treating \textit{cities} and \textit{languages} analogously. We apply methods developed for unsupervised machine language translation tasks to translate place representations across different cities. Real world mobility data collected from mobile phone users in 2 cities in Japan are used to test our place representation translation methods. Translated place representations are validated using landuse data, and results show that our methods were able to accurately translate place representations from one city to another.
VLUC: An Empirical Benchmark for Video-Like Urban Computing on Citywide Crowd and Traffic Prediction
Nov 16, 2019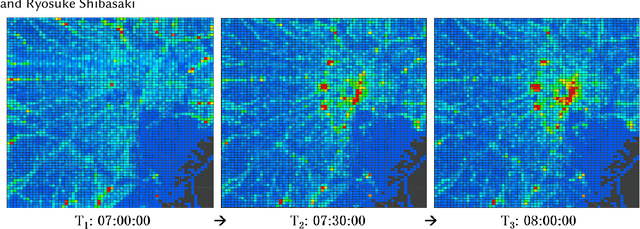
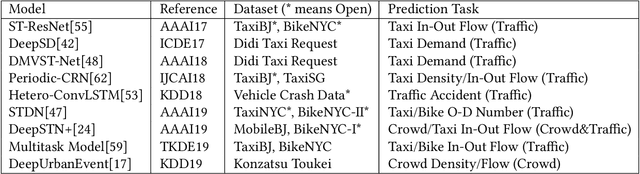
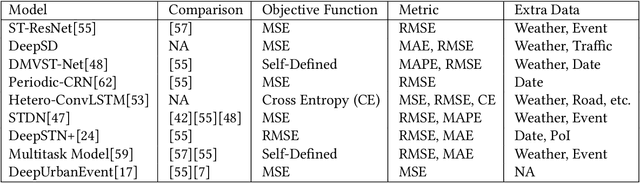
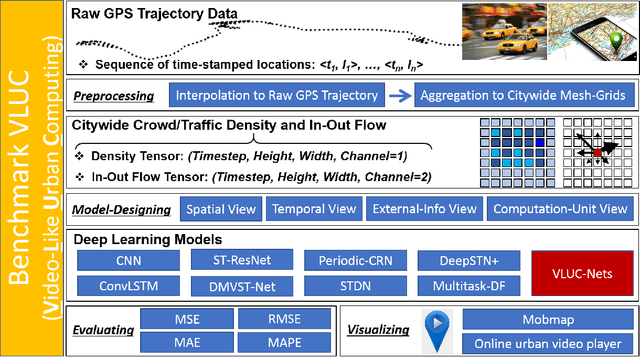
Nowadays, massive urban human mobility data are being generated from mobile phones, car navigation systems, and traffic sensors. Predicting the density and flow of the crowd or traffic at a citywide level becomes possible by using the big data and cutting-edge AI technologies. It has been a very significant research topic with high social impact, which can be widely applied to emergency management, traffic regulation, and urban planning. In particular, by meshing a large urban area to a number of fine-grained mesh-grids, citywide crowd and traffic information in a continuous time period can be represented like a video, where each timestamp can be seen as one video frame. Based on this idea, a series of methods have been proposed to address video-like prediction for citywide crowd and traffic. In this study, we publish a new aggregated human mobility dataset generated from a real-world smartphone application and build a standard benchmark for such kind of video-like urban computing with this new dataset and the existing open datasets. We first comprehensively review the state-of-the-art works of literature and formulate the density and in-out flow prediction problem, then conduct a thorough performance assessment for those methods. With this benchmark, we hope researchers can easily follow up and quickly launch a new solution on this topic.