 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGEO-BLEU: Similarity Measure for Geospatial Sequences
Dec 14, 2021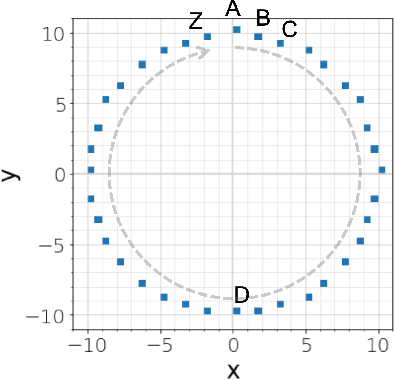

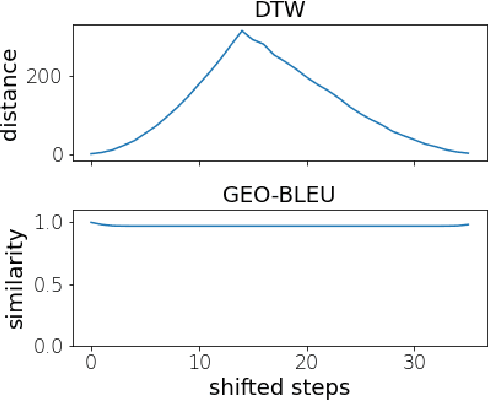
In recent geospatial research, the importance of modeling large-scale human mobility data via self-supervised learning is rising, in parallel with progress in natural language processing driven by self-supervised approaches using large-scale corpora. Whereas there are already plenty of feasible approaches applicable to geospatial sequence modeling itself, there seems to be room to improve with regard to evaluation, specifically about how to measure the similarity between generated and reference sequences. In this work, we propose a novel similarity measure, GEO-BLEU, which can be especially useful in the context of geospatial sequence modeling and generation. As the name suggests, this work is based on BLEU, one of the most popular measures used in machine translation research, while introducing spatial proximity to the idea of n-gram. We compare this measure with an established baseline, dynamic time warping, applying it to actual generated geospatial sequences. Using crowdsourced annotated data on the similarity between geospatial sequences collected from over 12,000 cases, we quantitatively and qualitatively show the proposed method's superiority.
Learning Fine Grained Place Embeddings with Spatial Hierarchy from Human Mobility Trajectories
Feb 06, 2020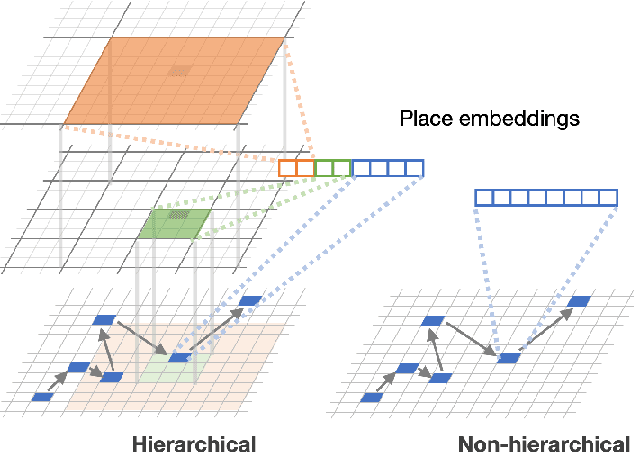
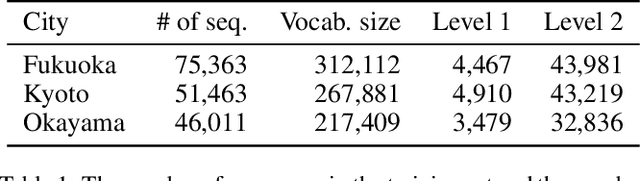
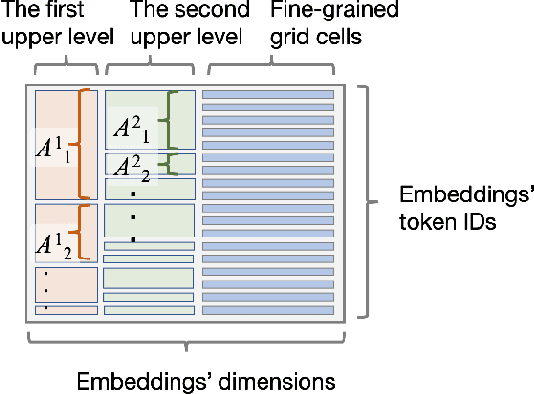
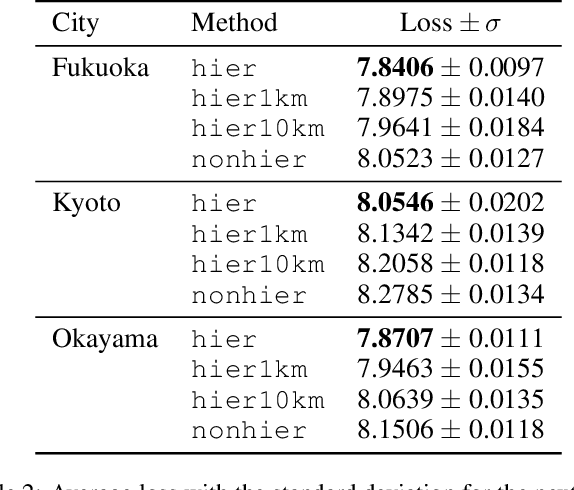
Place embeddings generated from human mobility trajectories have become a popular method to understand the functionality of places. Place embeddings with high spatial resolution are desirable for many applications, however, downscaling the spatial resolution deteriorates the quality of embeddings due to data sparsity, especially in less populated areas. We address this issue by proposing a method that generates fine grained place embeddings, which leverages spatial hierarchical information according to the local density of observed data points. The effectiveness of our fine grained place embeddings are compared to baseline methods via next place prediction tasks using real world trajectory data from 3 cities in Japan. In addition, we demonstrate the value of our fine grained place embeddings for land use classification applications. We believe that our technique of incorporating spatial hierarchical information can complement and reinforce various place embedding generating methods.
City2City: Translating Place Representations across Cities
Nov 26, 2019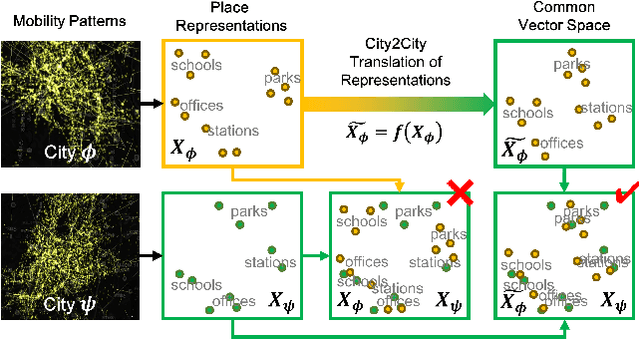
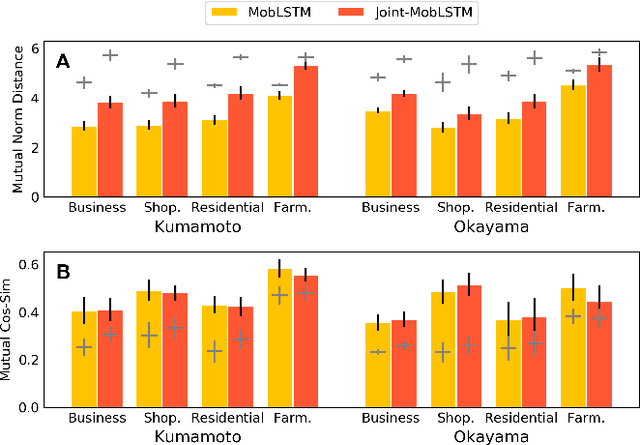
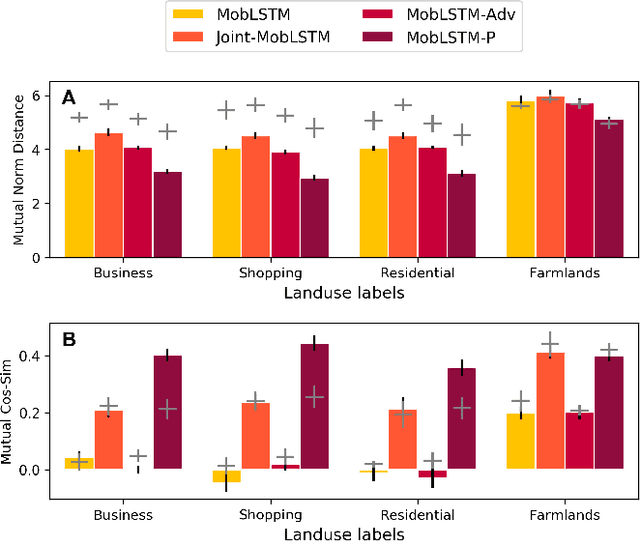
Large mobility datasets collected from various sources have allowed us to observe, analyze, predict and solve a wide range of important urban challenges. In particular, studies have generated place representations (or embeddings) from mobility patterns in a similar manner to word embeddings to better understand the functionality of different places within a city. However, studies have been limited to generating such representations of cities in an individual manner and has lacked an inter-city perspective, which has made it difficult to transfer the insights gained from the place representations across different cities. In this study, we attempt to bridge this research gap by treating \textit{cities} and \textit{languages} analogously. We apply methods developed for unsupervised machine language translation tasks to translate place representations across different cities. Real world mobility data collected from mobile phone users in 2 cities in Japan are used to test our place representation translation methods. Translated place representations are validated using landuse data, and results show that our methods were able to accurately translate place representations from one city to another.