 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Hierarchical Urban Representation Learning for Commuting Flow Prediction
Aug 27, 2024



Commuting flow prediction is an essential task for municipal operations in the real world. Previous studies have revealed that it is feasible to estimate the commuting origin-destination (OD) demand within a city using multiple auxiliary data. However, most existing methods are not suitable to deal with a similar task at a large scale, namely within a prefecture or the whole nation, owing to the increased number of geographical units that need to be maintained. In addition, region representation learning is a universal approach for gaining urban knowledge for diverse metropolitan downstream tasks. Although many researchers have developed comprehensive frameworks to describe urban units from multi-source data, they have not clarified the relationship between the selected geographical elements. Furthermore, metropolitan areas naturally preserve ranked structures, like cities and their inclusive districts, which makes elucidating relations between cross-level urban units necessary. Therefore, we develop a heterogeneous graph-based model to generate meaningful region embeddings at multiple spatial resolutions for predicting different types of inter-level OD flows. To demonstrate the effectiveness of the proposed method, extensive experiments were conducted using real-world aggregated mobile phone datasets collected from Shizuoka Prefecture, Japan. The results indicate that our proposed model outperforms existing models in terms of a uniform urban structure. We extend the understanding of predicted results using reasonable explanations to enhance the credibility of the model.
Crowdsensing-based Road Damage Detection Challenge (CRDDC-2022)
Nov 21, 2022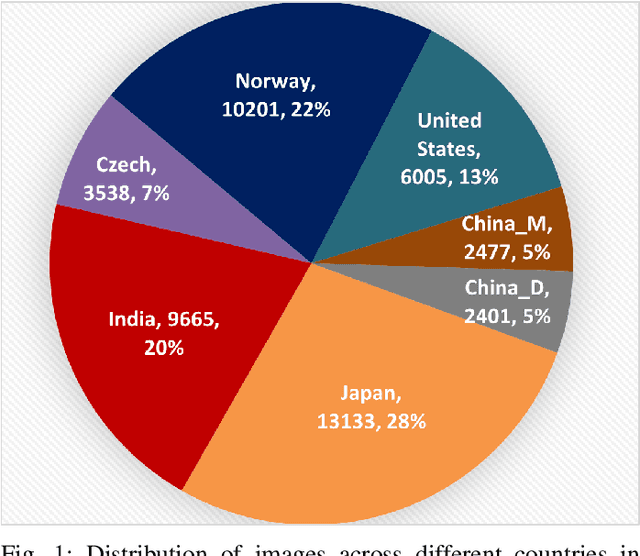



This paper summarizes the Crowdsensing-based Road Damage Detection Challenge (CRDDC), a Big Data Cup organized as a part of the IEEE International Conference on Big Data'2022. The Big Data Cup challenges involve a released dataset and a well-defined problem with clear evaluation metrics. The challenges run on a data competition platform that maintains a real-time online evaluation system for the participants. In the presented case, the data constitute 47,420 road images collected from India, Japan, the Czech Republic, Norway, the United States, and China to propose methods for automatically detecting road damages in these countries. More than 60 teams from 19 countries registered for this competition. The submitted solutions were evaluated using five leaderboards based on performance for unseen test images from the aforementioned six countries. This paper encapsulates the top 11 solutions proposed by these teams. The best-performing model utilizes ensemble learning based on YOLO and Faster-RCNN series models to yield an F1 score of 76% for test data combined from all 6 countries. The paper concludes with a comparison of current and past challenges and provides direction for the future.
Road Rutting Detection using Deep Learning on Images
Sep 28, 2022
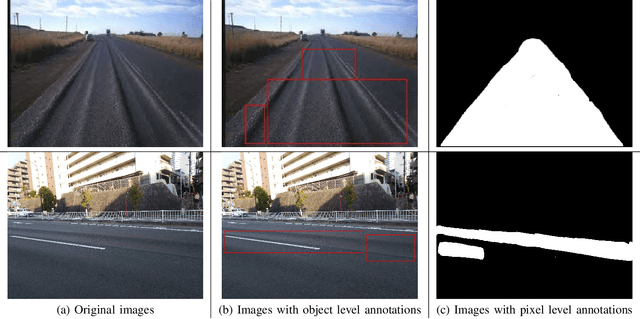


Road rutting is a severe road distress that can cause premature failure of road incurring early and costly maintenance costs. Research on road damage detection using image processing techniques and deep learning are being actively conducted in the past few years. However, these researches are mostly focused on detection of cracks, potholes, and their variants. Very few research has been done on the detection of road rutting. This paper proposes a novel road rutting dataset comprising of 949 images and provides both object level and pixel level annotations. Object detection models and semantic segmentation models were deployed to detect road rutting on the proposed dataset, and quantitative and qualitative analysis of model predictions were done to evaluate model performance and identify challenges faced in the detection of road rutting using the proposed method. Object detection model YOLOX-s achieves mAP@IoU=0.5 of 61.6% and semantic segmentation model PSPNet (Resnet-50) achieves IoU of 54.69 and accuracy of 72.67, thus providing a benchmark accuracy for similar work in future. The proposed road rutting dataset and the results of our research study will help accelerate the research on detection of road rutting using deep learning.
RDD2022: A multi-national image dataset for automatic Road Damage Detection
Sep 18, 2022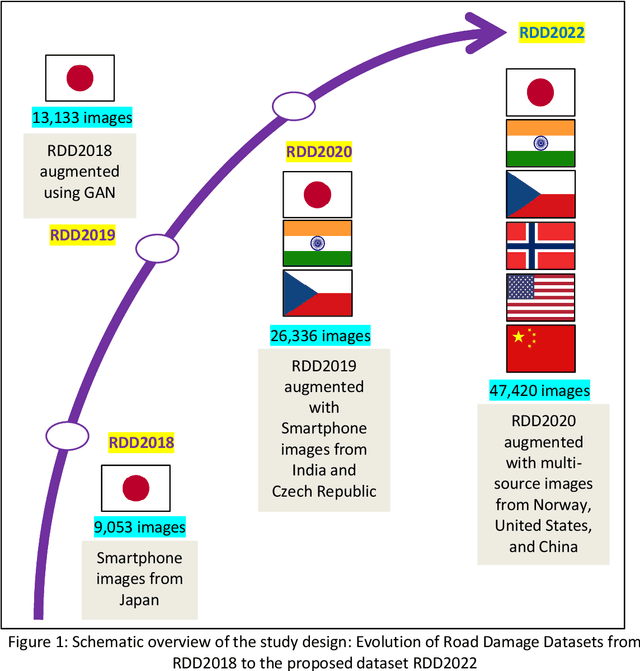
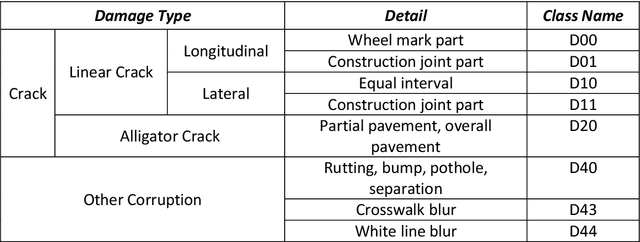
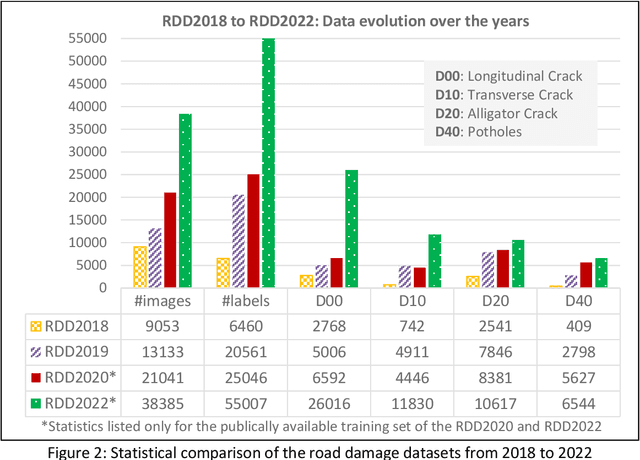

The data article describes the Road Damage Dataset, RDD2022, which comprises 47,420 road images from six countries, Japan, India, the Czech Republic, Norway, the United States, and China. The images have been annotated with more than 55,000 instances of road damage. Four types of road damage, namely longitudinal cracks, transverse cracks, alligator cracks, and potholes, are captured in the dataset. The annotated dataset is envisioned for developing deep learning-based methods to detect and classify road damage automatically. The dataset has been released as a part of the Crowd sensing-based Road Damage Detection Challenge (CRDDC2022). The challenge CRDDC2022 invites researchers from across the globe to propose solutions for automatic road damage detection in multiple countries. The municipalities and road agencies may utilize the RDD2022 dataset, and the models trained using RDD2022 for low-cost automatic monitoring of road conditions. Further, computer vision and machine learning researchers may use the dataset to benchmark the performance of different algorithms for other image-based applications of the same type (classification, object detection, etc.).
Global Road Damage Detection: State-of-the-art Solutions
Nov 17, 2020

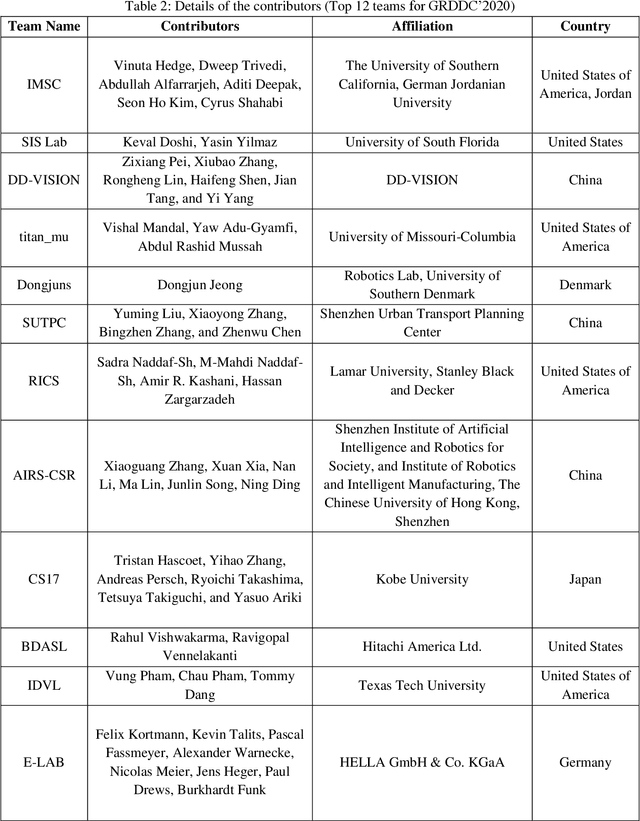

This paper summarizes the Global Road Damage Detection Challenge (GRDDC), a Big Data Cup organized as a part of the IEEE International Conference on Big Data'2020. The Big Data Cup challenges involve a released dataset and a well-defined problem with clear evaluation metrics. The challenges run on a data competition platform that maintains a leaderboard for the participants. In the presented case, the data constitute 26336 road images collected from India, Japan, and the Czech Republic to propose methods for automatically detecting road damages in these countries. In total, 121 teams from several countries registered for this competition. The submitted solutions were evaluated using two datasets test1 and test2, comprising 2,631 and 2,664 images. This paper encapsulates the top 12 solutions proposed by these teams. The best performing model utilizes YOLO-based ensemble learning to yield an F1 score of 0.67 on test1 and 0.66 on test2. The paper concludes with a review of the facets that worked well for the presented challenge and those that could be improved in future challenges.
Transfer Learning-based Road Damage Detection for Multiple Countries
Aug 30, 2020
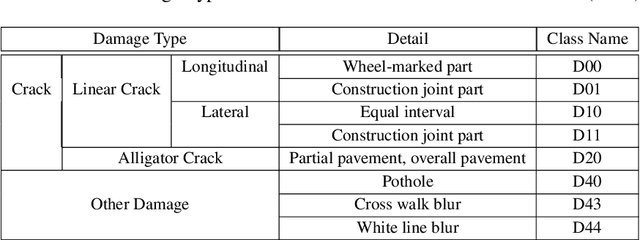
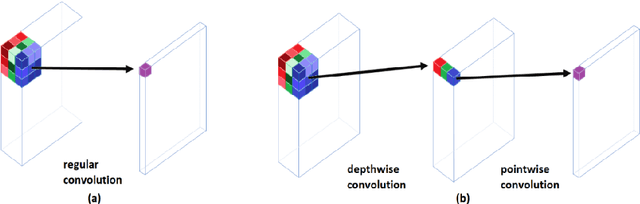
Many municipalities and road authorities seek to implement automated evaluation of road damage. However, they often lack technology, know-how, and funds to afford state-of-the-art equipment for data collection and analysis of road damages. Although some countries, like Japan, have developed less expensive and readily available Smartphone-based methods for automatic road condition monitoring, other countries still struggle to find efficient solutions. This work makes the following contributions in this context. Firstly, it assesses the usability of the Japanese model for other countries. Secondly, it proposes a large-scale heterogeneous road damage dataset comprising 26620 images collected from multiple countries using smartphones. Thirdly, we propose generalized models capable of detecting and classifying road damages in more than one country. Lastly, we provide recommendations for readers, local agencies, and municipalities of other countries when one other country publishes its data and model for automatic road damage detection and classification. Our dataset is available at (https://github.com/sekilab/RoadDamageDetector/).
City2City: Translating Place Representations across Cities
Nov 26, 2019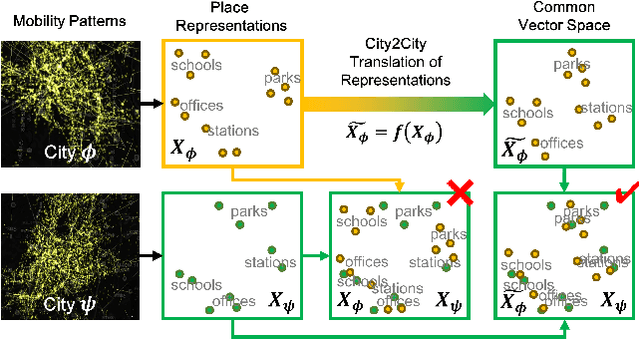
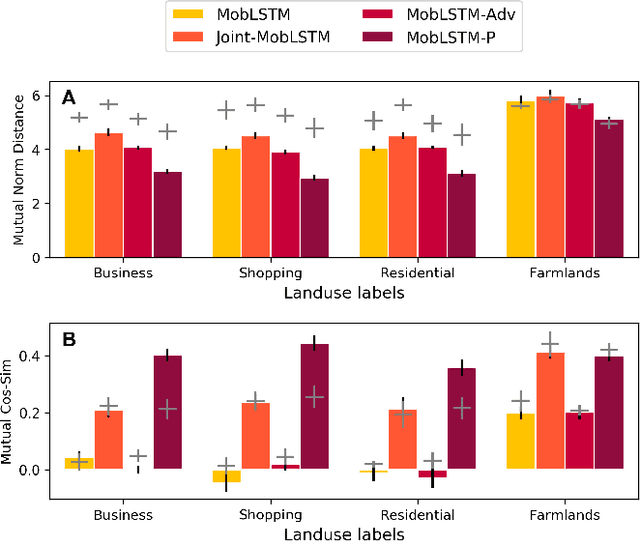
Large mobility datasets collected from various sources have allowed us to observe, analyze, predict and solve a wide range of important urban challenges. In particular, studies have generated place representations (or embeddings) from mobility patterns in a similar manner to word embeddings to better understand the functionality of different places within a city. However, studies have been limited to generating such representations of cities in an individual manner and has lacked an inter-city perspective, which has made it difficult to transfer the insights gained from the place representations across different cities. In this study, we attempt to bridge this research gap by treating \textit{cities} and \textit{languages} analogously. We apply methods developed for unsupervised machine language translation tasks to translate place representations across different cities. Real world mobility data collected from mobile phone users in 2 cities in Japan are used to test our place representation translation methods. Translated place representations are validated using landuse data, and results show that our methods were able to accurately translate place representations from one city to another.
Congestion Analysis of Convolutional Neural Network-Based Pedestrian Counting Methods on Helicopter Footage
Nov 05, 2019
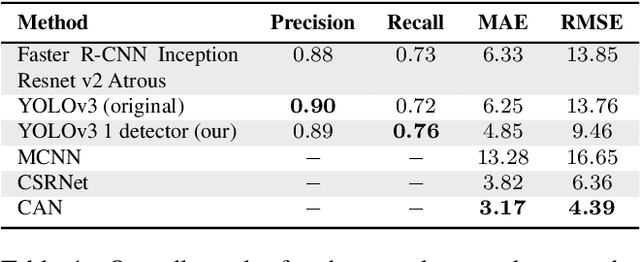

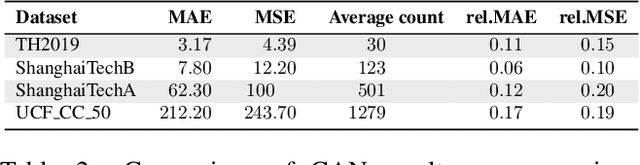
Over the past few years, researchers have presented many different applications for convolutional neural networks, including those for the detection and recognition of objects from images. The desire to understand our own nature has always been an important motivation for research. Thus, the visual recognition of humans is among the most important issues facing machine learning today. Most solutions for this task have been developed and tested by using several publicly available datasets. These datasets typically contain images taken from street-level closed-circuit television cameras offering a low-angle view. There are major differences between such images and those taken from the sky. In addition, aerial images are often very congested, containing hundreds of targets. These factors may have significant impact on the quality of the results. In this paper, we investigate state-of-the-art methods for counting pedestrians and the related performance of aerial footage. Furthermore, we analyze this performance with respect to the congestion levels of the images.
Road Damage Detection Using Deep Neural Networks with Images Captured Through a Smartphone
Feb 02, 2018
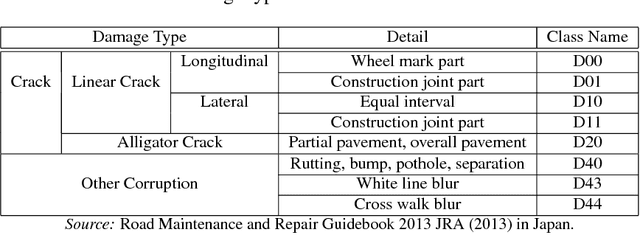
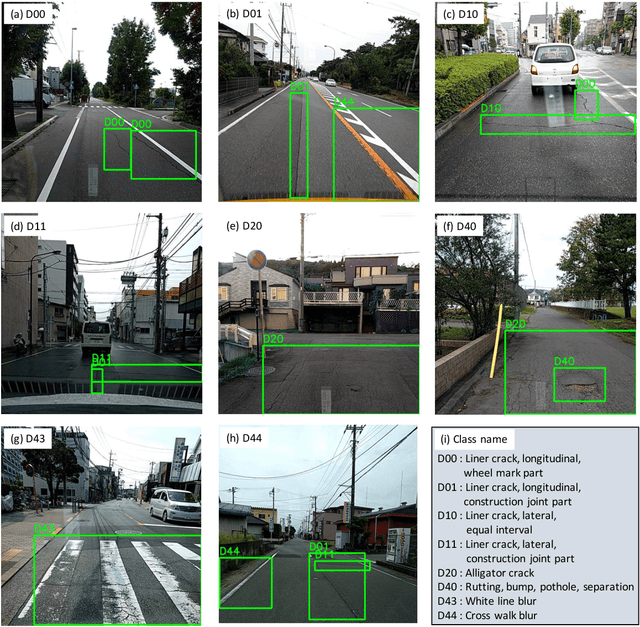

Research on damage detection of road surfaces using image processing techniques has been actively conducted, achieving considerably high detection accuracies. Many studies only focus on the detection of the presence or absence of damage. However, in a real-world scenario, when the road managers from a governing body need to repair such damage, they need to clearly understand the type of damage in order to take effective action. In addition, in many of these previous studies, the researchers acquire their own data using different methods. Hence, there is no uniform road damage dataset available openly, leading to the absence of a benchmark for road damage detection. This study makes three contributions to address these issues. First, to the best of our knowledge, for the first time, a large-scale road damage dataset is prepared. This dataset is composed of 9,053 road damage images captured with a smartphone installed on a car, with 15,435 instances of road surface damage included in these road images. In order to generate this dataset, we cooperated with 7 municipalities in Japan and acquired road images for more than 40 hours. These images were captured in a wide variety of weather and illuminance conditions. In each image, we annotated the bounding box representing the location and type of damage. Next, we used a state-of-the-art object detection method using convolutional neural networks to train the damage detection model with our dataset, and compared the accuracy and runtime speed on both, using a GPU server and a smartphone. Finally, we demonstrate that the type of damage can be classified into eight types with high accuracy by applying the proposed object detection method. The road damage dataset, our experimental results, and the developed smartphone application used in this study are publicly available (https://github.com/sekilab/RoadDamageDetector/).