 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFunction-Space ADMM for Decentralized Federated Learning: A Control Theoretic Perspective
May 10, 2026Decentralized federated learning (FL) is a promising approach for training machine learning models on sensor networks, Internet of Things (IoT) devices, and other edge systems where no central server exists. While federated learning offers advantages such as preserving data privacy, it often suffers from non-independent and identically distributed (IID) data distributions across devices, which cause significant performance degradation. This issue is particularly severe when directly optimizing model parameters, because neural network training is inherently non-convex and standard convergence guarantees for convex optimization do not apply. Unlike existing decentralized FL methods that primarily operate in parameter space, we propose federated function-space alternating direction method of multipliers (FedF-ADMM). FedF-ADMM exploits the convexity of loss functionals within function space to derive alternating direction method of multipliers (ADMM)-based update directions, which are subsequently projected onto the parameter space via knowledge distillation. We further introduce a stabilization coefficient to enhance robustness under severe non-IID settings and analyze its behavior from a control-theoretic perspective by interpreting it as a proportional-integral (PI) term. Experiments under challenging non-IID scenarios, including settings where each device has data from only a single label, demonstrate that FedF-ADMM achieves faster and more stable convergence than existing decentralized FL methods, while attaining higher accuracy and better consensus among devices.
* (c) 2026 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works
Poster: Recognizing Hidden-in-the-Ear Private Key for Reliable Silent Speech Interface Using Multi-Task Learning
Dec 18, 2025Silent speech interface (SSI) enables hands-free input without audible vocalization, but most SSI systems do not verify speaker identity. We present HEar-ID, which uses consumer active noise-canceling earbuds to capture low-frequency "whisper" audio and high-frequency ultrasonic reflections. Features from both streams pass through a shared encoder, producing embeddings that feed a contrastive branch for user authentication and an SSI head for silent spelling recognition. This design supports decoding of 50 words while reliably rejecting impostors, all on commodity earbuds with a single model. Experiments demonstrate that HEar-ID achieves strong spelling accuracy and robust authentication.
Instruction-Tuning Llama-3-8B Excels in City-Scale Mobility Prediction
Oct 31, 2024



Human mobility prediction plays a critical role in applications such as disaster response, urban planning, and epidemic forecasting. Traditional methods often rely on designing crafted, domain-specific models, and typically focus on short-term predictions, which struggle to generalize across diverse urban environments. In this study, we introduce Llama-3-8B-Mob, a large language model fine-tuned with instruction tuning, for long-term citywide mobility prediction -- in a Q&A manner. We validate our approach using large-scale human mobility data from four metropolitan areas in Japan, focusing on predicting individual trajectories over the next 15 days. The results demonstrate that Llama-3-8B-Mob excels in modeling long-term human mobility -- surpassing the state-of-the-art on multiple prediction metrics. It also displays strong zero-shot generalization capabilities -- effectively generalizing to other cities even when fine-tuned only on limited samples from a single city. Source codes are available at https://github.com/TANGHULU6/Llama3-8B-Mob.
Taming the Long Tail in Human Mobility Prediction
Oct 19, 2024



With the popularity of location-based services, human mobility prediction plays a key role in enhancing personalized navigation, optimizing recommendation systems, and facilitating urban mobility and planning. This involves predicting a user's next POI (point-of-interest) visit using their past visit history. However, the uneven distribution of visitations over time and space, namely the long-tail problem in spatial distribution, makes it difficult for AI models to predict those POIs that are less visited by humans. In light of this issue, we propose the Long-Tail Adjusted Next POI Prediction (LoTNext) framework for mobility prediction, combining a Long-Tailed Graph Adjustment module to reduce the impact of the long-tailed nodes in the user-POI interaction graph and a novel Long-Tailed Loss Adjustment module to adjust loss by logit score and sample weight adjustment strategy. Also, we employ the auxiliary prediction task to enhance generalization and accuracy. Our experiments with two real-world trajectory datasets demonstrate that LoTNext significantly surpasses existing state-of-the-art works. Our code is available at https://github.com/Yukayo/LoTNext.
SIMformer: Single-Layer Vanilla Transformer Can Learn Free-Space Trajectory Similarity
Oct 18, 2024



Free-space trajectory similarity calculation, e.g., DTW, Hausdorff, and Frechet, often incur quadratic time complexity, thus learning-based methods have been proposed to accelerate the computation. The core idea is to train an encoder to transform trajectories into representation vectors and then compute vector similarity to approximate the ground truth. However, existing methods face dual challenges of effectiveness and efficiency: 1) they all utilize Euclidean distance to compute representation similarity, which leads to the severe curse of dimensionality issue -- reducing the distinguishability among representations and significantly affecting the accuracy of subsequent similarity search tasks; 2) most of them are trained in triplets manner and often necessitate additional information which downgrades the efficiency; 3) previous studies, while emphasizing the scalability in terms of efficiency, overlooked the deterioration of effectiveness when the dataset size grows. To cope with these issues, we propose a simple, yet accurate, fast, scalable model that only uses a single-layer vanilla transformer encoder as the feature extractor and employs tailored representation similarity functions to approximate various ground truth similarity measures. Extensive experiments demonstrate our model significantly mitigates the curse of dimensionality issue and outperforms the state-of-the-arts in effectiveness, efficiency, and scalability.
Image Generative Semantic Communication with Multi-Modal Similarity Estimation for Resource-Limited Networks
Apr 17, 2024



To reduce network traffic and support environments with limited resources, a method for transmitting images with low amounts of transmission data is required. Machine learning-based image compression methods, which compress the data size of images while maintaining their features, have been proposed. However, in certain situations, reconstructing a part of semantic information of images at the receiver end may be sufficient. To realize this concept, semantic-information-based communication, called semantic communication, has been proposed, along with an image transmission method using semantic communication. This method transmits only the semantic information of an image, and the receiver reconstructs the image using an image-generation model. This method utilizes one type of semantic information, but reconstructing images similar to the original image using only it is challenging. This study proposes a multi-modal image transmission method that leverages diverse semantic information for efficient semantic communication. The proposed method extracts multi-modal semantic information from an image and transmits only it. Subsequently, the receiver generates multiple images using an image-generation model and selects an output based on semantic similarity. The receiver must select the output based only on the received features; however, evaluating semantic similarity using conventional metrics is challenging. Therefore, this study explored new metrics to evaluate the similarity between semantic features of images and proposes two scoring procedures. The results indicate that the proposed procedures can compare semantic similarities, such as position and composition, between semantic features of the original and generated images. Thus, the proposed method can facilitate the transmission and utilization of photographs through mobile networks for various service applications.
Convergence Visualizer of Decentralized Federated Distillation with Reduced Communication Costs
Dec 19, 2023Federated learning (FL) achieves collaborative learning without the need for data sharing, thus preventing privacy leakage. To extend FL into a fully decentralized algorithm, researchers have applied distributed optimization algorithms to FL by considering machine learning (ML) tasks as parameter optimization problems. Conversely, the consensus-based multi-hop federated distillation (CMFD) proposed in the authors' previous work makes neural network (NN) models get close with others in a function space rather than in a parameter space. Hence, this study solves two unresolved challenges of CMFD: (1) communication cost reduction and (2) visualization of model convergence. Based on a proposed dynamic communication cost reduction method (DCCR), the amount of data transferred in a network is reduced; however, with a slight degradation in the prediction accuracy. In addition, a technique for visualizing the distance between the NN models in a function space is also proposed. The technique applies a dimensionality reduction technique by approximating infinite-dimensional functions as numerical vectors to visualize the trajectory of how the models change by the distributed learning algorithm.
* (c) 2023 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works
Estimating Sunlight Using GNSS Signal Strength from Smartphone
Aug 09, 2022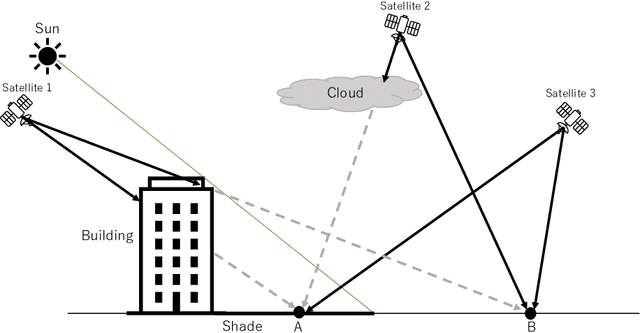
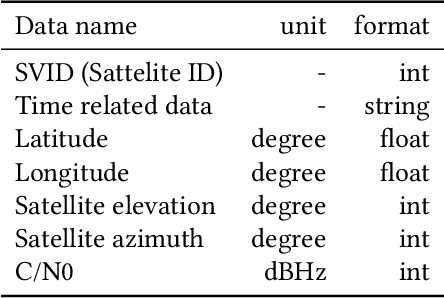
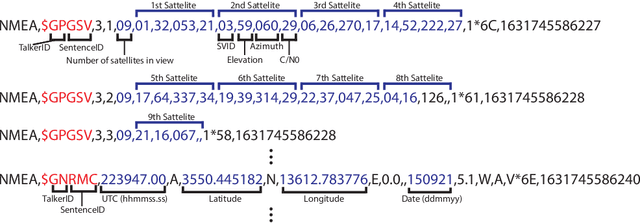
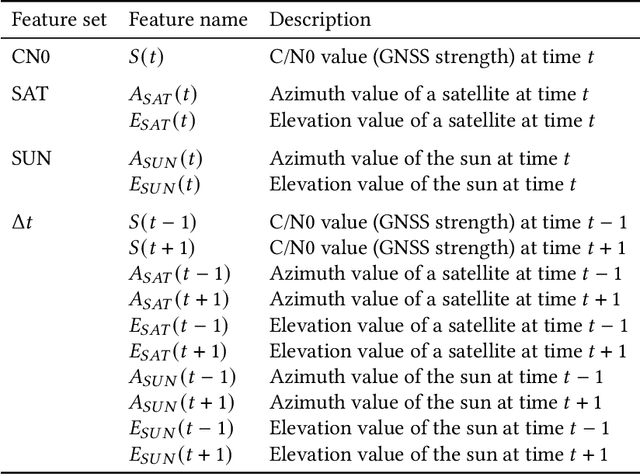
Excessive or inadequate exposure to ultraviolet light (UV) is harmful to health and causes osteoporosis, colon cancer, and skin cancer. The UV Index, a standard scale of UV light, tends to increase in sunny places and sharply decrease in the shade. A method for distinguishing shady and sunny places would help us to prevent and cure diseases caused by UV. However, the existing methods, such as carrying UV sensors, impose a load on the user, whereas city-level UV forecasts do not have enough granularity for monitoring an individual's UV exposure. This paper proposes a method to detect sunny and shady places by using an off-the-shelf mobile device. The method detects these places by using a characteristic of the GNSS signal strength that is attenuated by objects around the device. As a dataset, we collected GNSS signal data, such as C/N0, satellite ID, satellite angle, and sun angle, together with reference data (i.e., sunny and shady place information every minute) for four days from five locations. Using the dataset, we created twelve classification models by using supervised machine learning methods and evaluated their performance by 4-fold cross-validation. In addition, we investigated the feature importance and the effect of combining features. The performance evaluation showed that our classification model could classify sunny and shady places with more than 97% accuracy in the best case. Moreover, our investigation revealed that the value of C/N0 at a moment and its time series (i.e., C/N0 value before and after the moment) are more important features.