 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInsect-Computer Hybrid Speaker: Speaker using Chirp of the Cicada Controlled by Electrical Muscle Stimulation
Apr 23, 2025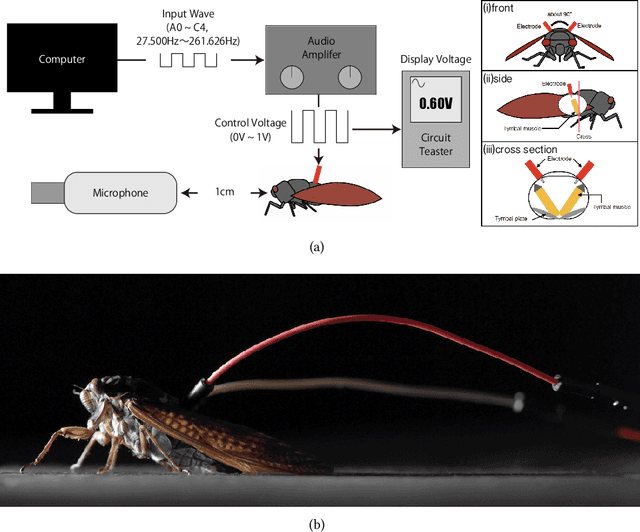

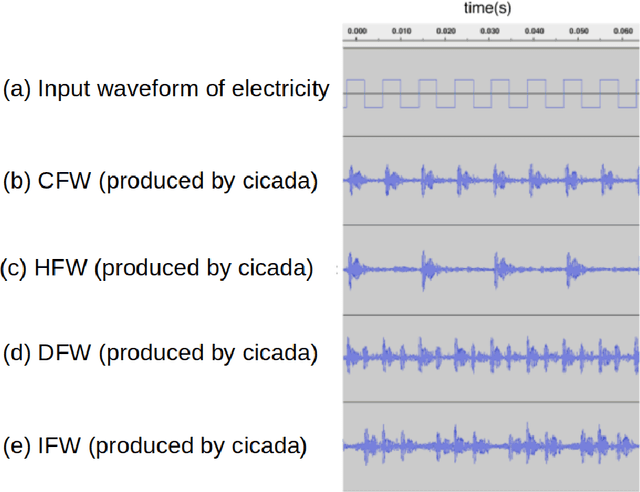
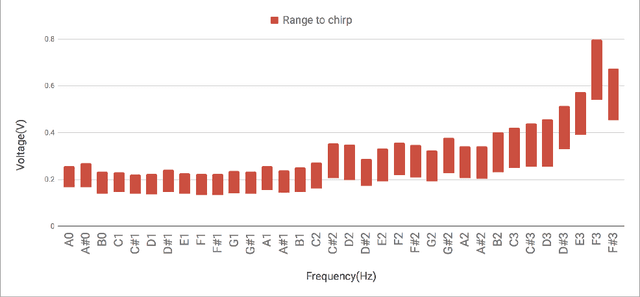
We propose "Insect-Computer Hybrid Speaker", which enables us to make musics made from combinations of computer and insects. Lots of studies have proposed methods and interfaces for controlling insects and obtaining feedback. However, there have been less research on the use of insects for interaction with third parties. In this paper, we propose a method in which cicadas are used as speakers triggered by using Electrical Muscle Stimulation (EMS). We explored and investigated the suitable waveform of chirp to be controlled, the appropriate voltage range, and the maximum pitch at which cicadas can chirp.
Real-Time Word-Level Temporal Segmentation in Streaming Speech Recognition
Apr 15, 2025Rich-text captions are essential to help communication for Deaf and hard-of-hearing (DHH) people, second-language learners, and those with autism spectrum disorder (ASD). They also preserve nuances when converting speech to text, enhancing the realism of presentation scripts and conversation or speech logs. However, current real-time captioning systems lack the capability to alter text attributes (ex. capitalization, sizes, and fonts) at the word level, hindering the accurate conveyance of speaker intent that is expressed in the tones or intonations of the speech. For example, ''YOU should do this'' tends to be considered as indicating ''You'' as the focus of the sentence, whereas ''You should do THIS'' tends to be ''This'' as the focus. This paper proposes a solution that changes the text decorations at the word level in real time. As a prototype, we developed an application that adjusts word size based on the loudness of each spoken word. Feedback from users implies that this system helped to convey the speaker's intent, offering a more engaging and accessible captioning experience.
SUMART: SUMmARizing Translation from Wordy to Concise Expression
Apr 14, 2025
We propose SUMART, a method for summarizing and compressing the volume of verbose subtitle translations. SUMART is designed for understanding translated captions (e.g., interlingual conversations via subtitle translation or when watching movies in foreign language audio and translated captions). SUMART is intended for users who want a big-picture and fast understanding of the conversation, audio, video content, and speech in a foreign language. During the training data collection, when a speaker makes a verbose statement, SUMART employs a large language model on-site to compress the volume of subtitles. This compressed data is then stored in a database for fine-tuning purposes. Later, SUMART uses data pairs from those non-compressed ASR results and compressed translated results for fine-tuning the translation model to generate more concise translations for practical uses. In practical applications, SUMART utilizes this trained model to produce concise translation results. Furthermore, as a practical application, we developed an application that allows conversations using subtitle translation in augmented reality spaces. As a pilot study, we conducted qualitative surveys using a SUMART prototype and a survey on the summarization model for SUMART. We envision the most effective use case of this system is where users need to consume a lot of information quickly (e.g., Speech, lectures, podcasts, Q&A in conferences).
Dynamik: Syntactically-Driven Dynamic Font Sizing for Emphasis of Key Information
Apr 13, 2025



In today's globalized world, there are increasing opportunities for individuals to communicate using a common non-native language (lingua franca). Non-native speakers often have opportunities to listen to foreign languages, but may not comprehend them as fully as native speakers do. To aid real-time comprehension, live transcription of subtitles is frequently used in everyday life (e.g., during Zoom conversations, watching YouTube videos, or on social networking sites). However, simultaneously reading subtitles while listening can increase cognitive load. In this study, we propose Dynamik, a system that reduces cognitive load during reading by decreasing the size of less important words and enlarging important ones, thereby enhancing sentence contrast. Our results indicate that Dynamik can reduce certain aspects of cognitive load, specifically, participants' perceived performance and effort among individuals with low proficiency in English, as well as enhance the users' sense of comprehension, especially among people with low English ability. We further discuss our methods' applicability to other languages and potential improvements and further research directions.
Single-tap Latency Reduction with Single- or Double- tap Prediction
Aug 05, 2024



Touch surfaces are widely utilized for smartphones, tablet PCs, and laptops (touchpad), and single and double taps are the most basic and common operations on them. The detection of single or double taps causes the single-tap latency problem, which creates a bottleneck in terms of the sensitivity of touch inputs. To reduce the single-tap latency, we propose a novel machine-learning-based tap prediction method called PredicTaps. Our method predicts whether a detected tap is a single tap or the first contact of a double tap without having to wait for the hundreds of milliseconds conventionally required. We present three evaluations and one user evaluation that demonstrate its broad applicability and usability for various tap situations on two form factors (touchpad and smartphone). The results showed PredicTaps reduces the single-tap latency from 150-500 ms to 12 ms on laptops and to 17.6 ms on smartphones without reducing usability.