 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProfy: Interpretable Visualization of Expertise-Dependent Motor Skills Toward Supporting Piano Practice
Jun 09, 2026The quality of piano performance depends on nuanced timing, articulation, and dynamic control, but practice feedback is often summary-based and hard to act on. We introduce Profy, a weakly supervised system that learns from take-level labels derived from aggregated listener ratings (expert-labeled vs. amateur-labeled) to produce time-aligned highlights for review during piano practice. We collected synchronized 1 kHz key-motion and audio from 73 pianists and used 1,083 valid takes for modeling and evaluation. The model outputs clip-level predictions together with evidence scores on a shared resampled model time base for visualization. On 20 amateur clips from short technique studies annotated by 21 expert pianists, the displayed highlight score aligns with passages that expert pianists marked for review despite training without localized labels (Pearson r=0.61, ROC-AUC 0.75). Rather than summarizing a take with a single global score, Profy helps learners decide where to inspect next by supporting scrubbing, looping, and focused replay of time-localized passages associated with expert-amateur differences.
NasoVoce: A Nose-Mounted Low-Audibility Speech Interface for Always-Available Speech Interaction
Mar 11, 2026Silent and whispered speech offer promise for always-available voice interaction with AI, yet existing methods struggle to balance vocabulary size, wearability, silence, and noise robustness. We present NasoVoce, a nose-bridge-mounted interface that integrates a microphone and a vibration sensor. Positioned at the nasal pads of smart glasses, it unobtrusively captures both acoustic and vibration signals. The nasal bridge, close to the mouth, allows access to bone- and skin-conducted speech and enables reliable capture of low-volume utterances such as whispered speech. While the microphone captures high-quality audio, it is highly sensitive to environmental noise. Conversely, the vibration sensor is robust to noise but yields lower signal quality. By fusing these complementary inputs, NasoVoce generates high-quality speech robust against interference. Evaluation with Whisper Large-v2, PESQ, STOI, and MUSHRA ratings confirms improved recognition and quality. NasoVoce demonstrates the feasibility of a practical interface for always-available, continuous, and discreet AI voice conversations.
* ACM CHI 2026 paper
Pinching Visuo-haptic Display: Investigating Cross-Modal Effects of Visual Textures on Electrostatic Cloth Tactile Sensations
Nov 08, 2025



This paper investigates how visual texture presentation influences tactile perception when interacting with electrostatic cloth displays. We propose a visuo-haptic system that allows users to pinch and rub virtual fabrics while feeling realistic frictional sensations modulated by electrostatic actuation. Through a user study, we examined the cross-modal effects between visual roughness and perceived tactile friction. The results demonstrate that visually rough textures amplify the perceived frictional force, even under identical electrostatic stimuli. These findings contribute to the understanding of multimodal texture perception and provide design insights for haptic feedback in virtual material interfaces.
SakugaFlow: A Stagewise Illustration Framework Emulating the Human Drawing Process and Providing Interactive Tutoring for Novice Drawing Skills
Jun 10, 2025While current AI illustration tools can generate high-quality images from text prompts, they rarely reveal the step-by-step procedure that human artists follow. We present SakugaFlow, a four-stage pipeline that pairs diffusion-based image generation with a large-language-model tutor. At each stage, novices receive real-time feedback on anatomy, perspective, and composition, revise any step non-linearly, and branch alternative versions. By exposing intermediate outputs and embedding pedagogical dialogue, SakugaFlow turns a black-box generator into a scaffolded learning environment that supports both creative exploration and skills acquisition.
MaskClip: Detachable Clip-on Piezoelectric Sensing of Mask Surface Vibrations for Real-time Noise-Robust Speech Input
May 04, 2025



Masks are essential in medical settings and during infectious outbreaks but significantly impair speech communication, especially in environments with background noise. Existing solutions often require substantial computational resources or compromise hygiene and comfort. We propose a novel sensing approach that captures only the wearer's voice by detecting mask surface vibrations using a piezoelectric sensor. Our developed device, MaskClip, employs a stainless steel clip with an optimally positioned piezoelectric sensor to selectively capture speech vibrations while inherently filtering out ambient noise. Evaluation experiments demonstrated superior performance with a low Character Error Rate of 6.1\% in noisy environments compared to conventional microphones. Subjective evaluations by 102 participants also showed high satisfaction scores. This approach shows promise for applications in settings where clear voice communication must be maintained while wearing protective equipment, such as medical facilities, cleanrooms, and industrial environments.
Real-Time Word-Level Temporal Segmentation in Streaming Speech Recognition
Apr 15, 2025Rich-text captions are essential to help communication for Deaf and hard-of-hearing (DHH) people, second-language learners, and those with autism spectrum disorder (ASD). They also preserve nuances when converting speech to text, enhancing the realism of presentation scripts and conversation or speech logs. However, current real-time captioning systems lack the capability to alter text attributes (ex. capitalization, sizes, and fonts) at the word level, hindering the accurate conveyance of speaker intent that is expressed in the tones or intonations of the speech. For example, ''YOU should do this'' tends to be considered as indicating ''You'' as the focus of the sentence, whereas ''You should do THIS'' tends to be ''This'' as the focus. This paper proposes a solution that changes the text decorations at the word level in real time. As a prototype, we developed an application that adjusts word size based on the loudness of each spoken word. Feedback from users implies that this system helped to convey the speaker's intent, offering a more engaging and accessible captioning experience.
SUMART: SUMmARizing Translation from Wordy to Concise Expression
Apr 14, 2025
We propose SUMART, a method for summarizing and compressing the volume of verbose subtitle translations. SUMART is designed for understanding translated captions (e.g., interlingual conversations via subtitle translation or when watching movies in foreign language audio and translated captions). SUMART is intended for users who want a big-picture and fast understanding of the conversation, audio, video content, and speech in a foreign language. During the training data collection, when a speaker makes a verbose statement, SUMART employs a large language model on-site to compress the volume of subtitles. This compressed data is then stored in a database for fine-tuning purposes. Later, SUMART uses data pairs from those non-compressed ASR results and compressed translated results for fine-tuning the translation model to generate more concise translations for practical uses. In practical applications, SUMART utilizes this trained model to produce concise translation results. Furthermore, as a practical application, we developed an application that allows conversations using subtitle translation in augmented reality spaces. As a pilot study, we conducted qualitative surveys using a SUMART prototype and a survey on the summarization model for SUMART. We envision the most effective use case of this system is where users need to consume a lot of information quickly (e.g., Speech, lectures, podcasts, Q&A in conferences).
GazeLLM: Multimodal LLMs incorporating Human Visual Attention
Mar 31, 2025Large Language Models (LLMs) are advancing into Multimodal LLMs (MLLMs), capable of processing image, audio, and video as well as text. Combining first-person video, MLLMs show promising potential for understanding human activities through video and audio, enabling many human-computer interaction and human-augmentation applications such as human activity support, real-world agents, and skill transfer to robots or other individuals. However, handling high-resolution, long-duration videos generates large latent representations, leading to substantial memory and processing demands, limiting the length and resolution MLLMs can manage. Reducing video resolution can lower memory usage but often compromises comprehension. This paper introduces a method that optimizes first-person video analysis by integrating eye-tracking data, and proposes a method that decomposes first-person vision video into sub areas for regions of gaze focus. By processing these selectively gazed-focused inputs, our approach achieves task comprehension equivalent to or even better than processing the entire image at full resolution, but with significantly reduced video data input (reduce the number of pixels to one-tenth), offering an efficient solution for using MLLMs to interpret and utilize human skills.
WhisperMask: A Noise Suppressive Mask-Type Microphone for Whisper Speech
Aug 22, 2024
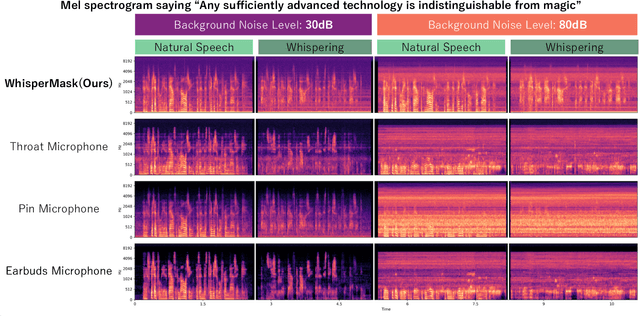

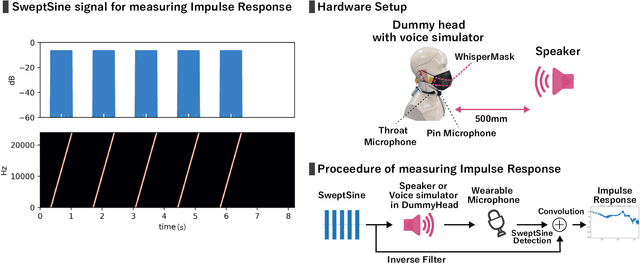
Whispering is a common privacy-preserving technique in voice-based interactions, but its effectiveness is limited in noisy environments. In conventional hardware- and software-based noise reduction approaches, isolating whispered speech from ambient noise and other speech sounds remains a challenge. We thus propose WhisperMask, a mask-type microphone featuring a large diaphragm with low sensitivity, making the wearer's voice significantly louder than the background noise. We evaluated WhisperMask using three key metrics: signal-to-noise ratio, quality of recorded voices, and speech recognition rate. Across all metrics, WhisperMask consistently outperformed traditional noise-suppressing microphones and software-based solutions. Notably, WhisperMask showed a 30% higher recognition accuracy for whispered speech recorded in an environment with 80 dB background noise compared with the pin microphone and earbuds. Furthermore, while a denoiser decreased the whispered speech recognition rate of these two microphones by approximately 20% at 30-60 dB noise, WhisperMask maintained a high performance even without denoising, surpassing the other microphones' performances by a significant margin.WhisperMask's design renders the wearer's voice as the dominant input and effectively suppresses background noise without relying on signal processing. This device allows for reliable voice interactions, such as phone calls and voice commands, in a wide range of noisy real-world scenarios while preserving user privacy.
* 14 pages, 14 figures
Telextiles: End-to-end Remote Transmission of Fabric Tactile Sensation
May 06, 2024The tactile sensation of textiles is critical in determining the comfort of clothing. For remote use, such as online shopping, users cannot physically touch the textile of clothes, making it difficult to evaluate its tactile sensation. Tactile sensing and actuation devices are required to transmit the tactile sensation of textiles. The sensing device needs to recognize different garments, even with hand-held sensors. In addition, the existing actuation device can only present a limited number of known patterns and cannot transmit unknown tactile sensations of textiles. To address these issues, we propose Telextiles, an interface that can remotely transmit tactile sensations of textiles by creating a latent space that reflects the proximity of textiles through contrastive self-supervised learning. We confirm that textiles with similar tactile features are located close to each other in the latent space through a two-dimensional plot. We then compress the latent features for known textile samples into the 1D distance and apply the 16 textile samples to the rollers in the order of the distance. The roller is rotated to select the textile with the closest feature if an unknown textile is detected.
* 10 pages, 8 figures, Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology